







 本文详细分析了ZeroMQ的多中心模型,解释了如何扩展单中心以实现任务在多个中心之间的共享。通过9个步骤展示了跨中心任务分配与回收的过程,并提供了在Windows下使用TCP代替IPC进行调试的方法。
本文详细分析了ZeroMQ的多中心模型,解释了如何扩展单中心以实现任务在多个中心之间的共享。通过9个步骤展示了跨中心任务分配与回收的过程,并提供了在Windows下使用TCP代替IPC进行调试的方法。
前言
这个例子是zeromq指南中的一个例子(peering3),你去这个地址可以看到例子的原文。当然原文并没有详细的解析这个例子,但是你把这个例子搞懂了zeromq基本就算入门了。
介绍
在这之前先看看它要解决的问题到底是什么。让我们先看这样的一种模型,你有很多客户,很多的工人,你还有一个中心用来将客户的请求发给工人,工人处理完将结果发给客户。工人可以任意的增加,客户也可以任意的增加。中心将客户的任务分配给工人,并将工人的结果发还给客户。见下图:
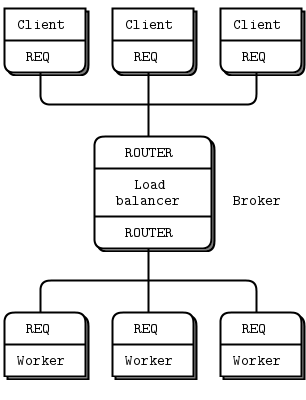
工人的增加不用配置,想增加多少都可以,客户端也是。然而中心只有一个,peering3就是演示如何扩展中心的,如下图:
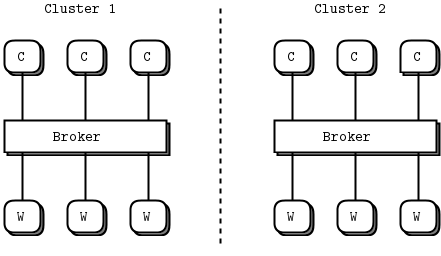
上图中有两个中心,如何让两个中心共享工人?例如如果中心1的工人都忙的时候,又来了一个客户。而中心2还有没有任务的工人。这时候最好有一种手段将任务发给中心2处理,完成后在发回1的客户。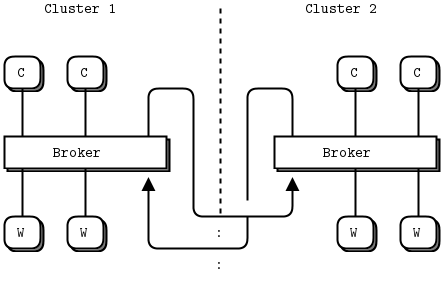
如果没看单中心的例子那你应该先去吧单中心的例子看懂。对单一中心的例子我简单描述下它的运作过程。
一共分5步走完这个循环:
1 轮询后端,发现一个工人准备好,从后端收到一个工人的ready信号。
(没有工人的情况下,根本不会轮询前端,好像餐馆你没有厨师在后面做菜,那么其实你根本不需要前台把客人接进来)
2 在后端有工人的情况下,轮询前端。收到一个客户请求。
3 向一个准备好的工人发送任务请求。
4 工人做完工作回传结果到后端。
5 通过前端将结果发给前端的客户。
完成整个工作循环,因为使用了ROUTER因此中心是完全异步方式工作的。也就是说有无数个客户的这5步任务穿插在线上。为什么要使用这种啰嗦的带一个中心的模式呢?其实它是为了解决分散任务的目的,同时获得无限扩展而没有其他成本的目的。因为系统增加工人并不需要改变程序,你只需要多启动几个工人。
多中心
多中心的模型是单中心模型的自然扩展。多中心在内部的主循环中加入了两个ROUTER用来和其他的中心交换信息。增加一个PUB-SUB套接字用来发布本地多余的工人状态。如下图:
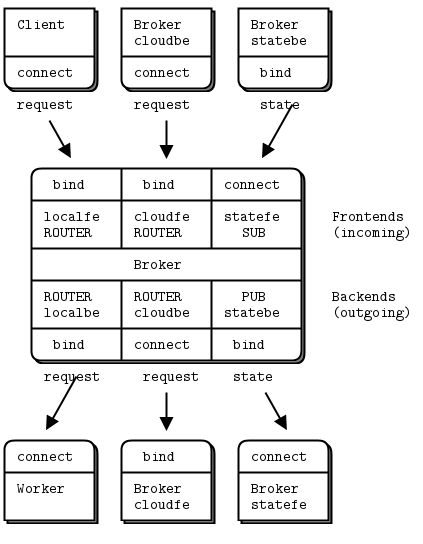
这个例子很复杂,上面已经说了单中心的本地一个循环有5步。抛开本地循环和其他中心交换需要9步。
1 如果本地工人多于本地客户时(瞬时的)。发送一个广播通知给其他中心。
下面是代码片段
...
if (local_capacity != previous) {
// We stick our own identity onto the envelope
zstr_sendm(statebe, self);
// Broadcast new capacity
zstr_sendf(statebe, "%d", local_capacity);
}
...2 其他中心收到通知,并知道有一个其他中心有多余的工人。
下面是代码片段
...
if (primary[2].revents & ZMQ_POLLIN) {
char *peer = zstr_recv(statefe);
char *status = zstr_recv(statefe);
cloud_capacity = atoi(status);
free(peer);
free(status);
}
... 3 一个本地前端收到一个客户,并且本地没有工人而且发现云端有多余工人,这时候它通过云的后端(cloudbe)发送任务到云端。
// Route to random broker peer
int peer = randof(argc - 2) + 2;
zmsg_pushmem(msg, argv[peer], strlen(argv[peer]));
zmsg_send(&msg, cloudbe);4 云的前端收入一个任务(cloudfe),其实下面的步骤和本地客户一样处理了。
if (secondary[1].revents & ZMQ_POLLIN)
{
msg = zmsg_recv(cloudfe);
}5 将任务发给一个本地工人。
6 工人处理完成将结果发回本地后端
7 通过云的前端将任务发给其他中心
// Route reply to cloud if it's addressed to a broker
for (argn = 2; msg && argn < argc; argn++) {
char *data = (char *)zframe_data(zmsg_first(msg));
size_t size = zframe_size(zmsg_first(msg));
if (size == strlen(argv[argn])
&& memcmp(data, argv[argn], size) == 0)
{
zmsg_send(&msg, cloudfe);
}
}8 请求边的中心通过云后端接收到处理结果。
if (primary[1].revents & ZMQ_POLLIN) {
msg = zmsg_recv(cloudbe);
if (!msg)
break; // Interrupted
// We don't use peer broker identity for anything
zframe_t *identity = zmsg_unwrap(msg);
zframe_destroy(&identity);
}9 这一步和本地处理一样,将处理结果发给客户。(和本地工人处理完一样)
if (msg)
{
zmsg_send(&msg, localfe);
}通过这9步完成一个跨中心的任务分配与回收。你可以编译程序通过调试来过一遍上面的步骤,但是因为这是一个多线程多进程的模型很难进行调试。另外windows不支持ipc协议,你需要使用tcp加加配置端口来重新分配地址。
下面是完整源代码。
源代码
// Broker peering simulation (part 3)
// Prototypes the full flow of status and tasks
#include "czmq.h"
#define NBR_CLIENTS 10
#define NBR_WORKERS 5
#define WORKER_READY "\001" // Signals worker is ready
// Our own name; in practice, this would be configured per node
static char *self;
// This is the client task. It issues a burst of requests and then
// sleeps for a few seconds. This simulates sporadic activity; when
// a number of clients are active at once, the local 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









