







一、smartcn(转自http://www.07net01.com/linux/solr4_3zhipeizhizhongwenfencismartcn_455940_1372147112.html)
1、将自带的jar包拷贝到tomcat下
文件:solr-5.1.0/contrib/analysis-extras/lucene-libs/lucene-analyzers-smartcn-5.1.0.jar
拷贝到: /usr/local/tomcat/webapps/solr/WEB-INF/lib/
2、修改schema.xml,添加
<fieldType name="text_smart" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.SmartChineseSentenceTokenizerFactory"/>
<filter class="solr.SmartChineseWordTokenFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.SmartChineseSentenceTokenizerFactory"/>
<filter class="solr.SmartChineseWordTokenFilterFactory"/>
</analyzer>
</fieldType>

二、mmseg4j
1、和smartcn一样将jar包(mmseg4j-core-1.10.0.jar、mmseg4j-solr-2.3.0.jar)复制到tomcat/webapps/solr/WEB-INF/lib/
2、修改schema.xml,添加以下内容后重启tomcat
<fieldType name="text_zh_wangtest" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="complex" dicPath="dic" />
<filter class="solr.StopFilterFactory" words="stopwords.txt" />
</analyzer>
</fieldType>3、测试

三、索引字段加入中文分词
这里新建了张表articles
CREATE TABLE `articles` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`title` varchar(200) NOT NULL,
`author` varchar(50) NOT NULL,
`last_update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;网上找点数据塞进去
INSERT INTO `articles` VALUES ('1', '3.6亿曼城又被这卧底坑死!无底黑洞让1亿白花', '梓泉', '2016-01-07 09:43:17');
INSERT INTO `articles` VALUES ('2', '瓜帅版曼城豪阵曝光!组最奢华中轴 梅西领4天王', '小九', '2016-01-07 09:43:41');
INSERT INTO `articles` VALUES ('3', '联赛杯-弃将助小魔兽绝杀 曼城丢争议球1-2负 ', '斯科', '2016-01-07 09:43:50');
INSERT INTO `articles` VALUES ('4', '瓜迪奥拉去曼城已定!英媒:他与前巴萨2巨头重逢 ', '兰尼斯特', '2016-01-07 09:44:06');
INSERT INTO `articles` VALUES ('5', '曼城主帅讽皇马:同情贝帅 皇马干出这种事不奇怪 ', '马尔科', '2016-01-07 09:44:18');solr后台新建core_articles。
修改data-config.xml
<dataConfig>
<dataSource name="solrDB" type="JdbcDataSource" driver="com.mysql.jdbc.Driver" url="jdbc:mysql://localhost:3306/wangtest" user="root" password="123456" />
<document>
<entity dataSource="solrDB" name="articles"
query="select * from articles"
deltaImportQuery="select * from articles where id= '${dih.delta.id}'"
deltaQuery="select id from articles where last_update_time > '${dataimporter.last_index_time}'">
<field column="id" name="id" />
<field column="title" name="title" />
<field column="author" name="author" />
<field column="last_update_time" name="last_update_time" />
</entity>
</document>
</dataConfig>修改schema.xml,添加filedType
<fieldType name="text_mmseg4j" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="complex" dicPath="dic" />
<filter class="solr.StopFilterFactory" words="stopwords.txt" />
</analyzer>
</fieldType>再添加相关索引字段
<field name="title" type="text_mmseg4j" indexed="true" stored="true" required="true" />
<field name="author" type="text_mmseg4j" indexed="true" stored="true" required="true" />
<field name="last_update_time" type="date" indexed="true" stored="true" />
重启tomcat后全量导入。
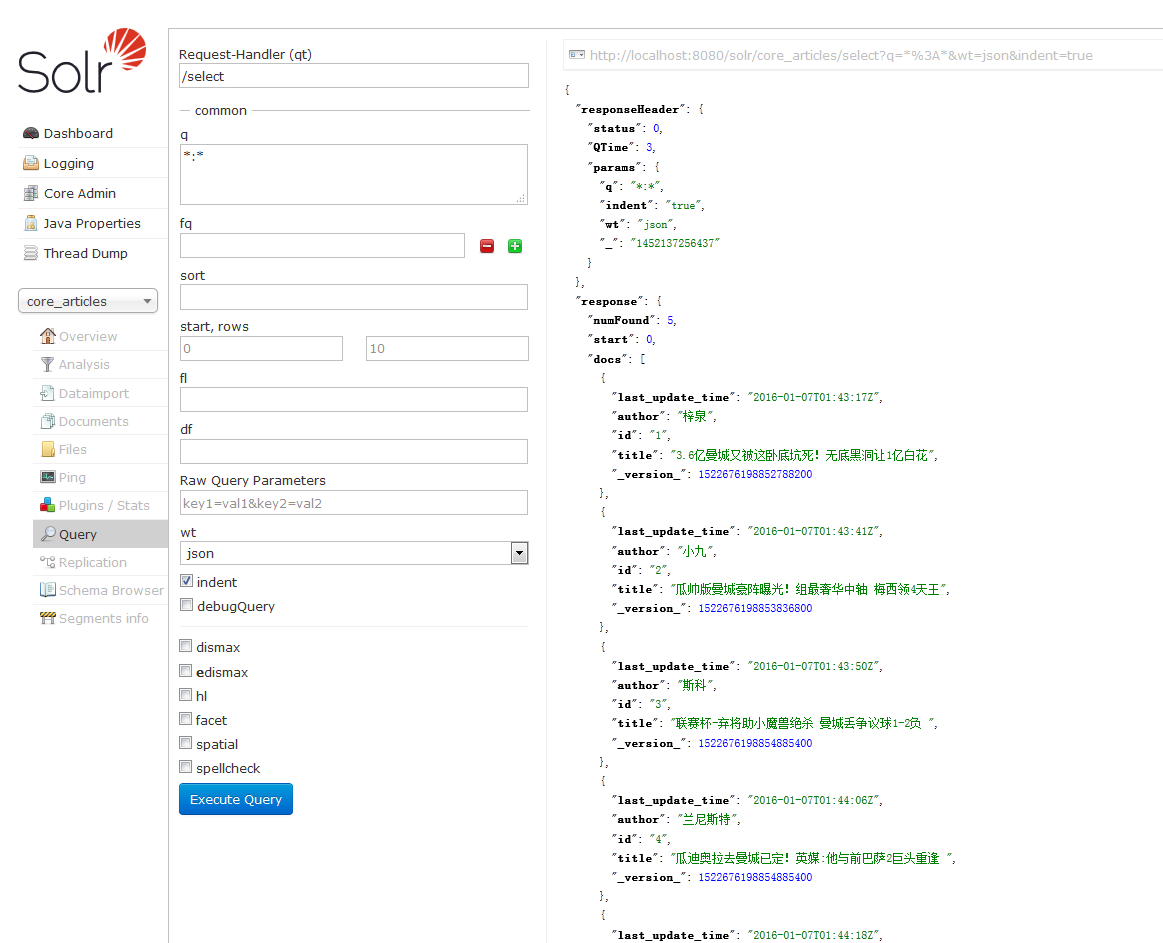
在Query里搜索的结果
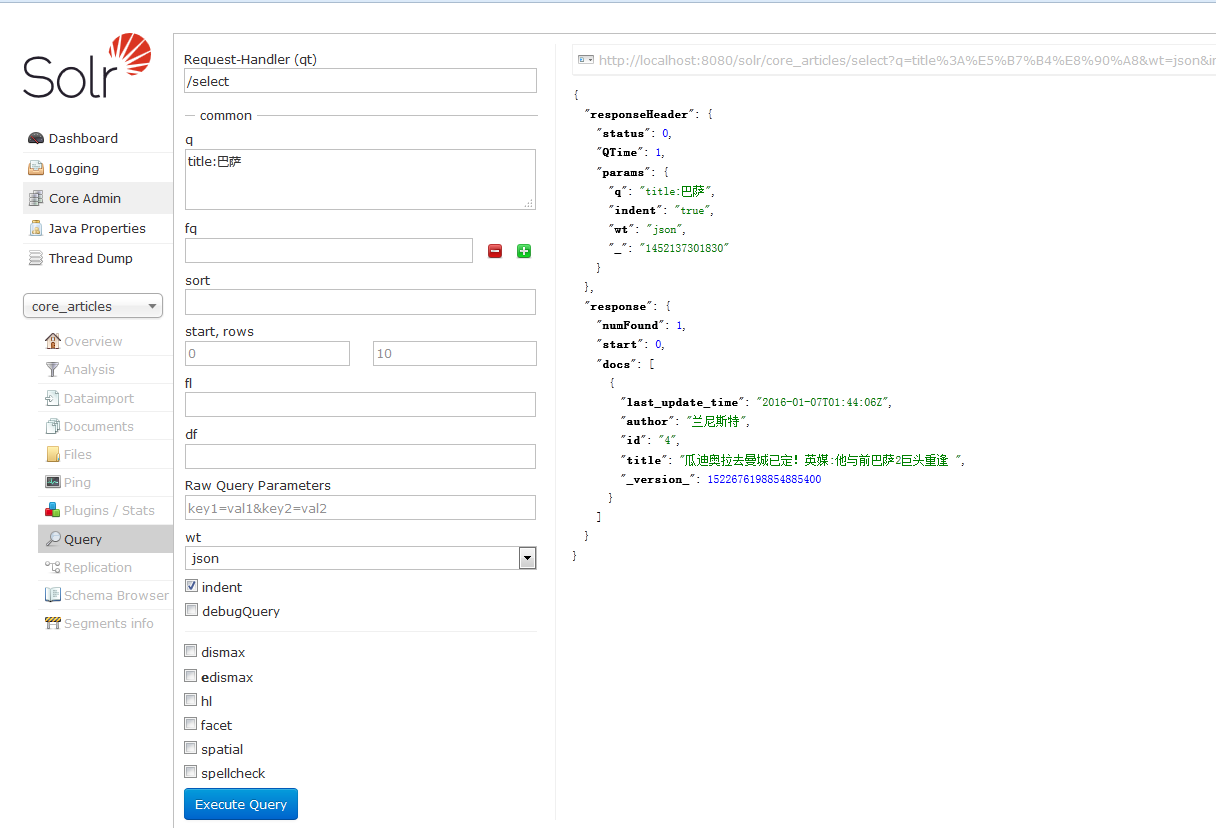
对title字段进行关键字搜索(如:巴萨)结果















 979
979











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









