







一 Kennard-Stone算法原理(KS算法)
KS算法原理:把所有的样本都看作训练集候选样本,依次从中挑选样本进训练集。首先选择欧氏距离最远的两个样本进入训练集,其后通过计算剩下的每一个样品到训练集内每一个已知样品的欧式距离,找到距已选样本最远以及最近的两个样本,并将这两个样本选入训练集,重复上述步骤直到样本数量达到要求。
欧式距离计算公式:
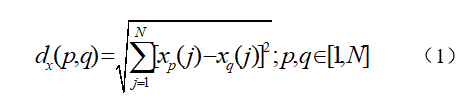
Xp,Xq表示两个不同的样本,N代表样本的光谱波点数量
二 python代码实现
def ks(x, y, test_size=0.2):
"""
:param x: shape (n_samples, n_features)
:param y: shape (n_sample, )
:param test_size: the ratio of test_size (float)
:return: spec_train: (n_samples, n_features)
spec_test: (n_samples, n_features)
target_train: (n_sample, )
target_test: (n_sample, )
"""
M = x.shape[0]
N = round((1-test_size) * M)
samples = np.arange(M)
D = np.zeros((M, M))
for i in range((M-1)):
xa = x[i, :]
for j in range((i+1), M):
xb = x[j, :]
D[i, j] = np.linalg.norm(xa-xb)
maxD = np.max(D, axis=0)
index_row = np.argmax(D, axis=0)
index_column = np.argmax(maxD)
m = np.zeros(N)
m[0] = np.array(index_row[index_column])
m[1] = np.array(index_column)
m = m.astype(int)
dminmax = np.zeros(N)
dminmax[1] = D[m[0], m[1]]
for i in range(2, N):
pool = np.delete(samples, m[:i])
dmin = np.zeros((M-i))
for j in range((M-i)):
indexa = pool[j]
d = np.zeros(i)
for k in range(i):
indexb = m[k]
if indexa < indexb:
d[k] = D[indexa, indexb]
else:
d[k] = D[indexb, indexa]
dmin[j] = np.min(d)
dminmax[i] = np.max(dmin)
index = np.argmax(dmin)
m[i] = pool[index]
m_complement = np.delete(np.arange(x.shape[0]), m)
spec_train = x[m, :]
target_train = y[m]
spec_test = x[m_complement, :]
target_test = y[m_complement]
return spec_train, spec_test, target_train, target_test















 7726
7726











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









