







NN问题描述:
现代科技已经使得每天产生的数据(图像、视频)成为了一个天文数字,那我们怎么去对待这些数据,怎么找到他们之间的相关性,更准确的来讲就是如何提取useful information data from the data。比如我们已经知道一堆图像有人、花、鸟等类,而且已经有一部分图像被记好标签了,那么如何对剩下的图像也进行标记?一般我们要找到和这个需要进行标记的图像最相似的已被标记的图像P,那么这个需要标记的图像就和P一类。
更专业的描述就是:given a collection of objects(such as images), for each unlabeledobject q, find the labeled object p that is most similar to q, under some notionof similarity. (picture from Pitor Indyk slides)
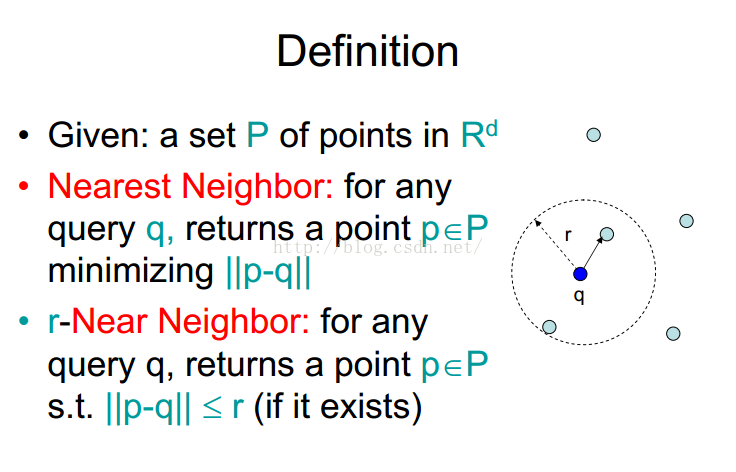
这种问题一般都被称为最近邻问题,上面提到的r就是找r个最近邻嘛。OK, 那么我们可以接着往下看了。
小时候学数学,老师经常会在黑板上画x,y轴,然后点几个点,写好坐标,让我们求谁到原点距离最短,也就是欧式距离最小,放到现在,我们如果在二维坐标系中,像撒麻豆一样撒出去1000个豆子,它们肯定会有自己的坐标,我们也可以用k—means距离找到相同的类,因为什么? 因为相同的类它们的距离肯定小,离聚类中心点更近,自然可以分辨出来。如果我们先确定有k类,自然其它点就对号入座。那么是不是问题就解决了? NO!
有没有发现一个问题?这些豆子是不是需要要对每一个位置中心点求距离?这可以看做最简单线性查找,查找那个中心点离自己距离近,如果维度为d,然后有n类,那么当然一次查找时间复杂度就为O(dn),如果你是计算机专业的会想到咦?我记得我大学数据结构老师有提到过k-dtrees work “well” in “low-medium” dimensions, 对头,同学上课很听讲,表扬一下,具体的一些查找方法你自行wikipedia,我脑海中应该看过几篇大拿论文中说过Near-linear query time for high dimensions。 LOL,那么这个NN,或者ANN还有个什么做的,低的用k-d trees, 高维的用什么方法也是个线性查找的时间。其实不然,你想一下,如果google搜图功能,你上传一个图像,然后想在庞大的网络中找到和它相似的,未必google真的把每张图片都跟你进行比较,并且找到相似的还进行排序展示出来? 当然不是。这里面说的线性查找是要包括训练、空间划分等,(也就是建索引之类的)但是这些我们提前已经弄好了,那么我们需要的时间其实就是查找时间而已,查找时间就会跟我们可以在已经建好的索引上进行查找就得了,所以才会这么快显示出来你需要的结果。
ANN描述:
好了,言归正传,这时我们可以把NN问题扩展到ANN(approximate near neighbor)问题:
ANN我一直以为是把NN问题模糊化,后来发现不然,这其实为后面我们要讲的LSH打下伏笔,还是给出Piotr Indyk(MIT) slides 上的解释:
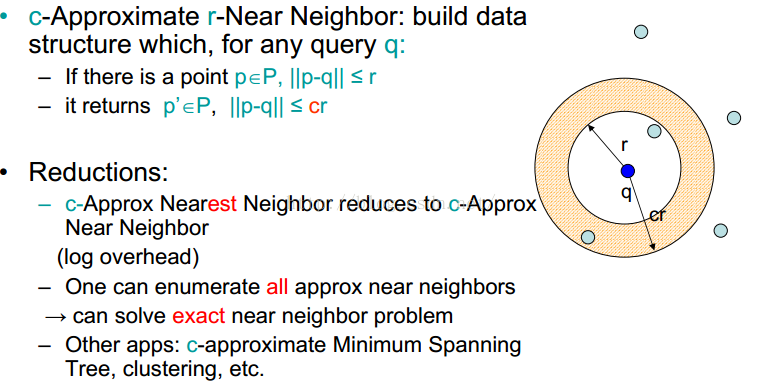
能搜到这篇博文起码文化水平是大学等级,英文阅读水平不会差,我这里就不翻译了,主要大家看到那黄色的一个小环圈了么?那就像在火星和木星之间的小行星带一样,那么这个小行星带究竟属于木星还是火星?这肯定不能下定结论,只能说木星对它们作用大,它们大概离木星更近一些,而上面给的一波英文其实意思比这还简单,就是一个unlabel的p离中心点q距离小于r那么一定小于cr(c大于0,然后我看到这里也很无语,这不是废话么),然后呢一个q可以列举出所有这样离它近的小行星,不过这确实可以玩的更深沉一点,真正的硬菜上来了。也就是这个slides的所有者提出的LSH。

LSH思考:
导师说过大牛都是从基础开始弄起,原来不以为然,现在发现这句话有点意思,上面这个式子感觉初中基础就能看懂,但LSH如今只要搞KNN、ANN的人基本上都知道,具体这几行的意思就是,如果object p和q之间距离如果小于r(和上面ANN提出来的一样),那么他们就会有一个很大的概率会属于同一个类,如果p和q之间的距离大于cr那么他们会有一个比较小的概率属于同一个类,来看看怎么算这个相似概率,比如给出进行hash function的p =10001000,q = 11001100,那么p和q的相似性就等于1-2/8 = 3/4, 也就是红色代表的不想似的个数除以码长,具体详细的解释可以参考下面的网址,并且它给出了很详细的解释和补充:http://blog.csdn.net/icvpr/article/details/12342159
而我这里当然也要说些这些博客没有的好玩的东西,首先我自己因为一些论文需要,在matlab上面写了一个小型图像查找系统,对LSH进行了范围内的改进,然后通过query image 查找最近相似图片,先给出部分查找结果:
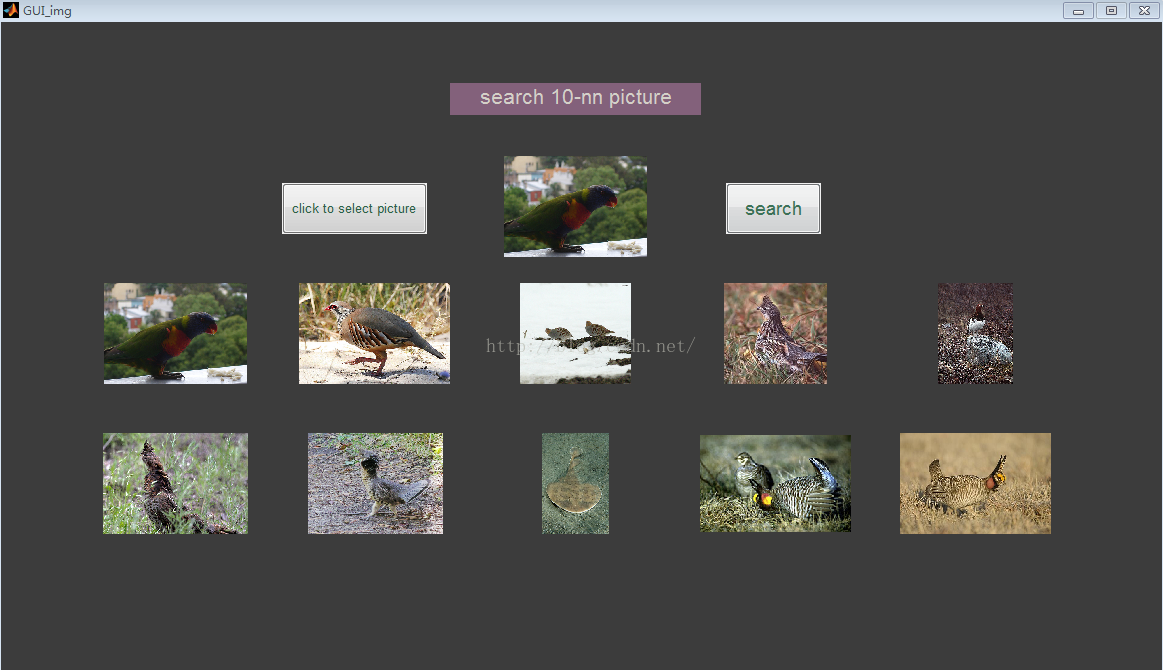
这是一个接近2W张随意图片的dataset,得出来的查找结果我个人觉得满意,LSH已经在最近邻查找上得到了广泛的应用,我看过的很多论文都写着这样一句话:LSH is popular methods in ANN, 几乎实验部分都会和LSH以及E2LSH进行比较,可以看出LSH的重要性。当然我也总结一下LSH的不足,因为以前有PPT进行展示过,所以偷懒就直接上我的slides:


上面说的中心思想就是我们想让在相近的r近邻(就和前面那个小行星的白色里面的)进行hash冲突的概率更大,而cr则越远,但是原始的LSH则会使得r-近邻和cr-近邻都越大,所以LSH会使得查找的结果很多时候并不能得到一个较好的回馈值。
从另外一个角度理解,我们把LSH大致可以这样看 :首先根据hash function进行散列操作,使得相邻的object散列到同一个桶里面,当然它和那种N mod k的这种散列方式是有本质上的区别,它不会完全就能很好的分好类,让所有的相邻点都在一个桶,也不能让不相邻的点不在同一个桶,但是LSH能在一定程度上保证可以区分谁是相近的点谁是离query object较远的点。

















 526
526

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









