







Reinforcement Learning: An Introduction读书笔记 第四章 动态规划)
Reinforcement Learning: An Introduction读书笔记 第四章 动态规划
The term dynamic programming (DP) refers to a collection of algorithms that
can be used to compute optimal policies given a perfect model of the environment as a Markov decision process (MDP).
- The environment is assumed as a finit MDP in this chapter.
Bellman optimality equations:
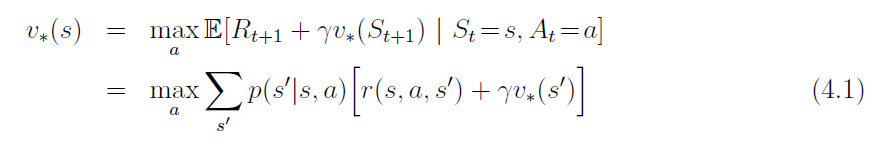
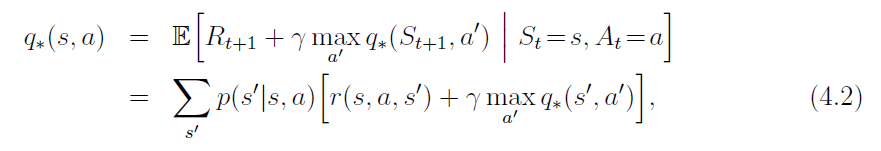
- DP algorithms are obtained by turning Bellman equations into update rules for improving approximations of the desired value functions.
4.1 Policy Evaluation
Suppose that the environment’s dynamics are completely known.
Consider a sequence of approximate value functions v0, v1, v2, . . ., each mapping S+ to R.
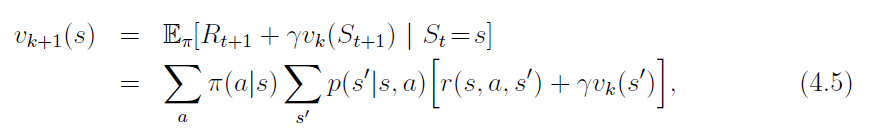
This algorithm is called iterative policy evaluation.
- All the backups done in DP algorithms are called full backups because they are based on all possible next states rather than on a sample next state.

4.2 Policy Improvement
For some state s we would like to know whether or not we should change the policy to deterministically choose an action a ≠ π(s).
Policy improvement theorem:
Let π and π’ be any pair of deterministic policies such that, for all s ∈ S,
Then the policy π’ must be as good as, or better than, π. That is, it must obtain greater or equal expected return from all states s ∈ S:
Proof:



the new greedy policy, π’ is given by:
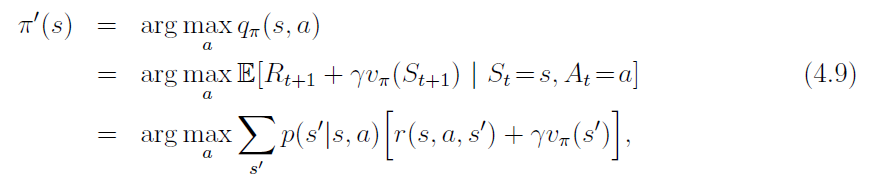
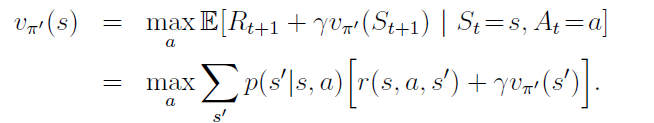
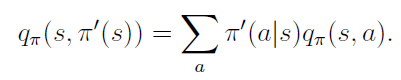
4.3 Policy Iteration

where E→ denotes a policy evaluation and I→ denotes a policy improvement.

4.4 Value Iteration
One drawback to policy iteration is that each of its iterations involves policy evaluation, which may itself be a protracted iterative computation requiring multiple sweeps through the state set.
One important special case is when policy evaluation is stopped after just one sweep (one backup of each state). This algorithm is called value iteration.

4.5 Asynchronous Dynamic Programming
A major drawback to the DP methods that we have discussed so far is that they involve operations over the entire state set of the MDP, that is, they require sweeps of the state set. If the state set is very large, then even a single sweep can be prohibitively expensive.
Asynchronous DP algorithms are in-place iterative DP algorithms that are not organized in terms of systematic sweeps of the state set. These algorithms back up the values of states in any order whatsoever, using whatever values of other states happen to be available. The values of some states may be backed up several times before the values of others are backed up once.
4.6 Generalized Policy Iteration(GPI)
We use the term generalized policy iteration (GPI) to refer to the general idea of letting policy evaluation and policy improvement processes interact, independent of the granularity and other details of the two processes.
- Almost all reinforcement learning methods are well described as GPI. That is, all have identifiable policies and value functions, with the policy always being improved with respect to the value function and the value function always being driven toward the value function for the policy.

The evaluation and improvement processes in GPI can be viewed as both competing and cooperating.
One might also think of the interaction between the evaluation and improvement processes in GPI in terms of two constraints or goals|for example, as two lines in two-dimensional space:

总结















 1561
1561











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









