







情况1 out是y的平均值,是一个标量,可以直接得出其对x的梯度(对 x i x_i xi的梯度之和)
import torch
x=torch.tensor([[12,6],[31,0.9]],requires_grad=True)
y=x*x
out=y.mean()
out.backward() #等效于torch.autograd.backward(out)
print(x.grad)
输出:
tensor([[ 6.0000, 3.0000],
[15.5000, 0.4500]])
情况2 y和x都是矢量,不能直接输出y对x的梯度,可以给y赋予
import torch
x=torch.tensor([[12,6],[31,0.9]],requires_grad=True)
y=x*x
v=torch.tensor([[1,1],[1,1]])
y.backward(v) #可以这样更实用 y.backward(torch.ones_like(y))
#v即grad_tensors参数
print(x.grad)
输出:
tensor([[24.0000, 12.0000],
[62.0000, 1.8000]])
思路图解

总结:必须要对标量进行求导,要是矢量的话需要转化为标量或者给一个一样大小的权重
扩展知识
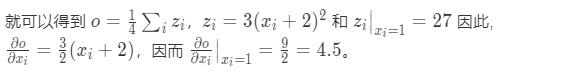
x和y都是向量的话,y对x的梯度相当于一个雅可比矩阵


为什么v可以写成这样??????????链接
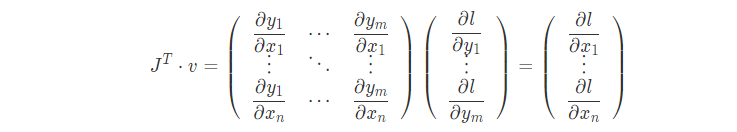
optimizer.zero_grad()是把梯度归零,而optimizer.step()是更新参数















 245
245











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









