






文章地址:https://arxiv.org/pdf/2203.07090.pdf
文章内容
目前基于方面实体情感分析任务(aspect-based sentiment analysis,ABSA)由于缺乏大量的带注释的数据而导致目前的发展遇到了极大地阻碍。为了解决这个问题,之前的工作利用普通的情感分析(SA)数据集通过多任务或预训练的方式来辅助训练ABSA模型。基于上述工作,该文作者首次将伪标签PL(Pseudo-Label)的方法来合并这2个同质任务,并且提出了一个全新的框架——双粒度伪标签DPL(Dual-granularity Pseudo Labeling)。与PL类似,DPL可以结合目前的先进方法,并取得SOTA的结果。
伪标签PL
伪标签的核心思想为通过使用有限数量的已标注样本来训练教师网络(teacher network),然后再通过教师网络为未标记样本生成伪标签。最后将生成的伪标记样本和原始数据集合并,并反馈给最终的模型以训练。
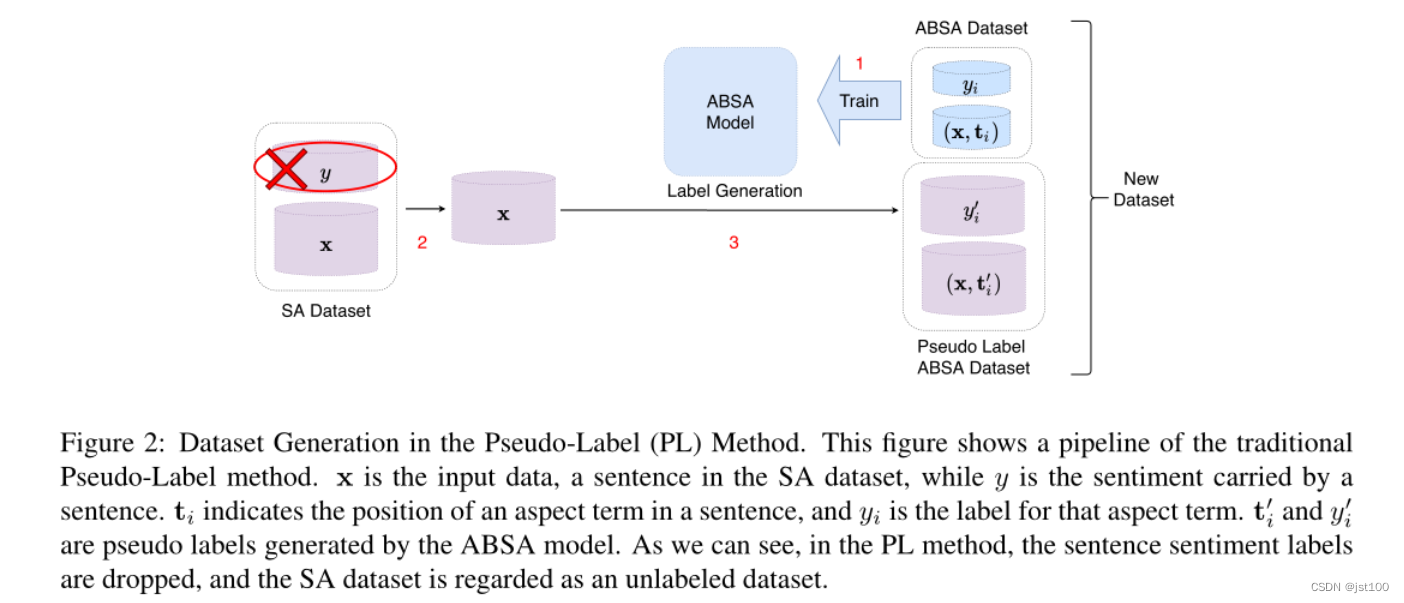
作者在这篇文章中的核心任务为将已有的大规模SA数据集合并到ABSA数据集当中。但如上图所示,传统的伪标签方法完全放弃并浪费了SA数据集中所提供的助理杜标签。
双粒度标签DPL
为了解决这个问题,作者提出了双粒度伪标签框架(DPL)。本质上,DPL扩展了原始的PL框架,并且能够利用从这两种粒度中提取的标签。即,DPL不同粒度上的教师模型用以为两个粒度上的数据集生成伪标签。因此可以将两个粒度级别的数据集合为一体,也就是每个句子的样本都同时具有粗粒度和细粒度标注。
双粒度伪标签标注
前言
作者所使用的数据集为同一领域中的粗粒度数据集和细粒度数据集,对于粗粒度数据集其要学习的映射为:
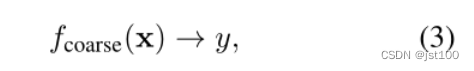
即对于一句话的情感标签。
而对于细粒度的数据集,其目标映射为:
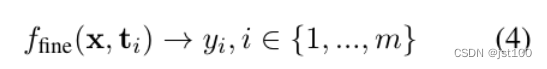
其中t代表对应的方面实体,也就是要学习每一个方面实体对应的映射。最终作者想获得的数据集效果如下所示:
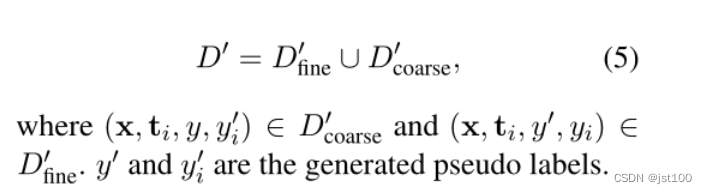
DPL骨架
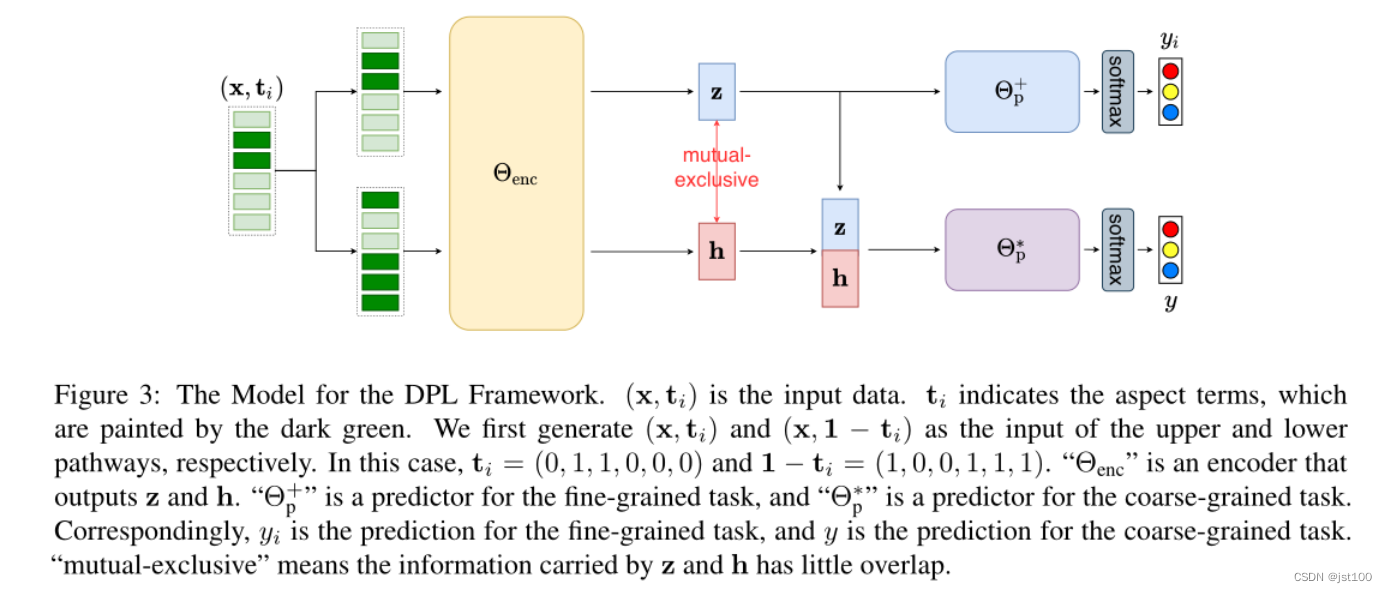
如上图所示,作者设置对应了于2个粒度的路径,使用z和h表示两条路径中的内部表示向量。
- z为携带了可以决定细粒度(每个方面实体)的情感标签
- h和z的组合可以决定粗粒度(整个句子)的情感标签
- h和z所携带的信息理应互斥,即仅依靠h不能得到细粒度的情感标签
最主要的问题在于怎么让细粒度的信息只通过z,粗粒度的信息通过h,以及对于粗粒度情感标签的判断依赖于h和z的拼接而不是其中的任意一个。
为了满足上述条件,作者设计了三个损失函数,头两项分别是粗粒度和细粒度的分类损失项从而满足条件1和条件2。对于条件3则通过引入对抗训练的思想来减少h所携带的与细粒度任务相关的信息。
细粒度和粗粒度任务
对于细粒度任务其损失函数如下所示:

对粗粒度任务其损失函数如下所示:

对抗训练
为了保证h和z之间的互斥性,引入了对抗训练损失项,以最大限度的减少h所携带的细粒度任务的相关信息,具体如下所示:
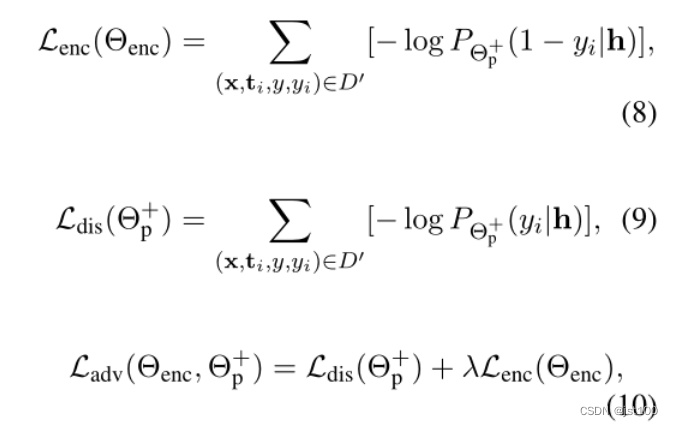
最终损失
最终损失如下所示:
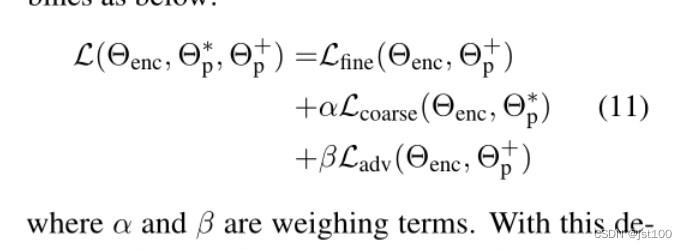















 896
896











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









