







谱聚类(Spectral Clustering)算法简单易行,其聚类性能优于传统的K-means算法。谱聚类将数据的划分转化为对图的分割,是一种基于图论的聚类方法,其直观理解为根据图内点的相似度将图分为多个子图,使子图内部的点相似度最高,子图之间点的相似度最低。
1. 图论基础
1.1 图的表示
记
G=(V,E)
表示一个无向加权图,
V
表示所有顶点的集合
1.2 相似度图的构造方法
给定一组数据集
V={v1,...,vn}
,将其构造为相似度图的意义在于描述点对之间的局部近邻关系。此处介绍三种构造相似度图的方法。
(1)ε近邻图。如果两点之间的距离小于给定值ε,则连接两点。ε的值需要根据图中各点的距离选择,使与某一点连接的点不会太多,也不会太少。
(2)
k
近邻图。如果点
(3)全连接图。不考虑任何因素,直接将所有的点两两相连,由于图表示点之间的局部邻接特性,常用的相似性函数为
s(xi,xj)=exp(−∥xi−xj∥22σ2)
。
1.3 图的Laplacian矩阵
这里我们要讲到谱聚类中的关键内容——拉普拉斯矩阵,其定义为
L=D–W
,其中
D
和
(1)对任意的向量
f∈Rn
,有
fTLf=12∑i,j=1nwij(fi−fj)2
。
证明:(此处用到了W的对称性)
(2) L 是对称半正定矩阵,该性质可由(1)直接得到。
(3)
(4)本文假设 L 的特征值按照从小到大的顺序排列,
此外,还有normalized Laplacian,分别定义为
Lsym=D−12LD−12=I−D−12WD−12 ,和 Lrm=D−1L=I−D−1W ,其中两个下标sym和rw分别代表symmetric和random walk,此处不再介绍这两个矩阵的性质。
2. 谱聚类算法
2.1 图的分割问题
谱聚类算法源于图的分割(cut),首先将所有的样本点连接成图,然后将图分割成不同的子图,使得不同子图之间的连接权值最小。
定义两个子图之间的连接权值为
W(A,B)=∑i∈A,j∈Bwij
,记
A¯¯¯
为
A
的补集,为了表达方便,我们记
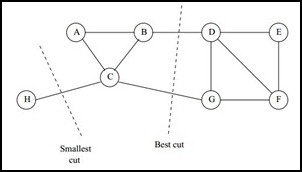
解决该问题的有效办法是让每个子图都有合理的大小,子图大小的度量方式不同就会得出不同的最小分割问题,常用的两种方法是RaioCut和Normalized Cut,分别如下:
RatioCut(A1,...,Ak)=12∑i=1kW(Ai,Ai¯¯¯¯)|Ai|=∑i=1kcut(Ai,Ai¯¯¯¯)|Ai|
Ncut(A1,...,Ak)=12∑i=1kW(Ai,Ai¯¯¯¯)vol(Ai)=∑i=1kcut(Ai,Ai¯¯¯¯)vol(Ai)
这两个目标函数均将子图的大小作为分母,这样就可以使每个子图不会太小,其中RatioCut以子图中点的个数 |Ai| 作为子图大小的度量,Normalized Cut以子图内所有点的度的和作为子图大小的衡量,即 vol(Ai)=∑j∈Aidj 。
下面我们分别讨论RatioCut和Normalized Cut是如何通过谱聚类来求解的。
2.2 求解RatioCut
首先从二聚类问题开始分析,其目标函数为最小化
定义向量 f=(f1,...,fn)T∈Rn ,其每个元素的定义如下:
结合图的Laplacian矩阵,我们可以得到RatioCut问题,推导过程如下:
fTLf=12∑i,j=1nwij(fi−fj)2=12∑i∈A,j∈A¯wij⎛⎝∣∣A¯∣∣|A|−−−√+|A|∣∣A¯∣∣−−−√⎞⎠2+12∑i∈A¯,j∈Awij⎛⎝−∣∣A¯∣∣|A|−−−√−|A|∣∣A¯∣∣−−−√⎞⎠2=12∑i∈A,j∈A¯wij⎛⎝∣∣A¯∣∣|A|+|A|∣∣A¯∣∣+2⎞⎠+12∑i∈A¯,j∈Awij⎛⎝∣∣A¯∣∣|A|+|A|∣∣A¯∣∣+2⎞⎠=12⎛⎝∑i∈A,j∈A¯wij+∑i∈A¯,j∈Awij⎞⎠⎛⎝∣∣A¯∣∣|A|+|A|∣∣A¯∣∣+2⎞⎠=cut(A,A¯)⎛⎝∣∣A¯∣∣+|A||A|+|A|+∣∣A¯∣∣∣∣A¯∣∣⎞⎠=|V|cut(A,A¯)⎛⎝1|A|+1∣∣A¯∣∣⎞⎠=|V|RatioCut(A,A¯)
其中,
|V|
表示所有点的个数,给定样本点后,
|V|
是个常数。
因为,求解RatioCut问题可以转变为最小化
fTLf
的问题,其中
f
的取值如上面所定义,然而,该离散优化问题是NP-hard,因此,我们将其进行松弛,使
根据Rayleigh-Ritz定理可知,该问题的解为Laplacian矩阵 L 的最小特征值所对应的特征向量,由于
求解上述优化问题后,要将数据集分为
由该定义可知,
H
的列相互正交,即
此外, hTjLhj=(HTLH)jj ,因此
所以,多聚类的RatioCut问题可以转化为最小化 Tr(HTLH) 的问题, H 的取值如上面所定义。同样,我们将该NP-hard问题松弛,使
这是标准的迹最小化问题,其解为 L 的的前
2.3 求解Normalized Cut
类似于RatioCut,下面我们简要给出Normalized Cut的实现过程。
首先分析二聚类的情况,定义示性函数如下:
按照该定义, f 具有性质
该问题需要求解广义特征向量问题 Lf=λDf , f 取
再扩展到 k 聚类问题,定义
按照该定义, H 具有性质
因此, Ncut(A1,...,Ak)=Tr(HTLH) ,加上松弛条件,使 H 的元素可以取任意实数,Normalized Cut就可以转化为如下有约束的优化问题:
该问题的解为广义特征值问题 Lh=λDh 的前 k 个特征向量所构成的矩阵。最后采用k-means方法对该矩阵的行进行聚类,就可以实现对该数据集的
2.4 小结
针对以上两种图分割方法,谱聚类算法的步骤如下:
Step1:将每个样本看做图的顶点,构造无向加权图;
Step2:计算图的邻接矩阵W和拉普拉斯矩阵L;
Step3:根据图的分割准则计算拉普拉斯矩阵的前k个特征向量;
Step4:将拉普拉斯矩阵的前k个特征向量构成矩阵Y,把Y的每一行看做一个样本,然后用k-means方法对Y进行聚类。
3. 总结
谱聚类相当于先进行非线性降维,使原始数据点能够线性可分,最后再使用k-means聚类就可以得到比较好的聚类效果。
谱聚类算法也存在以下几点不足:
(1) 谱聚类的松弛条件是对原问题的一个近似,但是并不能保证该近似是合适的,其误差有可能非常大,而且导致聚类问题不稳定;
(2) 构造相似度矩阵的尺度参数根据经验设定,尺度参数的选择对聚类效果影响较大;
(3) 同其他聚类方法一样,聚类数目的选择难以确定;
(4) 根据图最小分割的目标函数可知,谱聚类适用于均衡分类问题,即各簇之间点的个数相差不大,对于簇之间点个数相差悬殊的聚类问题,谱聚类则不适用。
以下一组图均为采用谱聚类方法进行聚类的结果,左侧一列的数据点个数分布比较均衡,聚类效果比较好,可以看出,右侧一列数据点的分布不均衡,谱聚类算法仍然将数据分成几个均衡的簇,而不能体现数据的分布结构。
















 488
488











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









