







1. 引言
关于Logistic Regression很多人都会有疑问:它用于分类问题,却为什么叫回归?Logistic Regression用到了一个常用的非线性函数——sigmoid函数,那它用于线性分类还是非线性分类?
本文首先指出,Logistic Regression是一个被Logistic函数归一化后的线性分类模型,本文只讨论二分类的情况,其因变量
y∈{0,1}
。与传统的KNN等分类方法不同之处在于Logistic Regression给出的结果并不是一个离散值或者确切的类别,而是一个与观测样本相关的概率,将线性回归转化成概率分类问题。
Logistic Regression可由线性回归推广而来。在线性回归中,
y=wTx+ϵ
,通常假设
ϵ∼N(0,σ)
,那么
E(y)=wTx
。对于Logistic Regression,其期望
0<E(y)<1
,而自变量的线性组合
wTx
的范围为实数域
R
。因此,Logistic Regression从几率的概念构建线性回归模型。一个事件发生的几率(odds)为该事件发生的概率与不发生概率的比值,记
p=P(y=1|x,w)
,那么该事件的几率为
p1−p
,几率的取值范围为[0,+∞),其对数的取值范围为实数域,所以,可以将对数几率作为因变量构建线性回归模型:
logp1−p=wTx
由此可得
p=11+exp(−wTx)
,即
P(y=1|x,w)=11+exp(−wTx)
,这便是Logistic Regression采用sigmoid函数的原因,sigmoid函数将自变量的线性组合映射到(0,1),用以表述分类的概率特性。
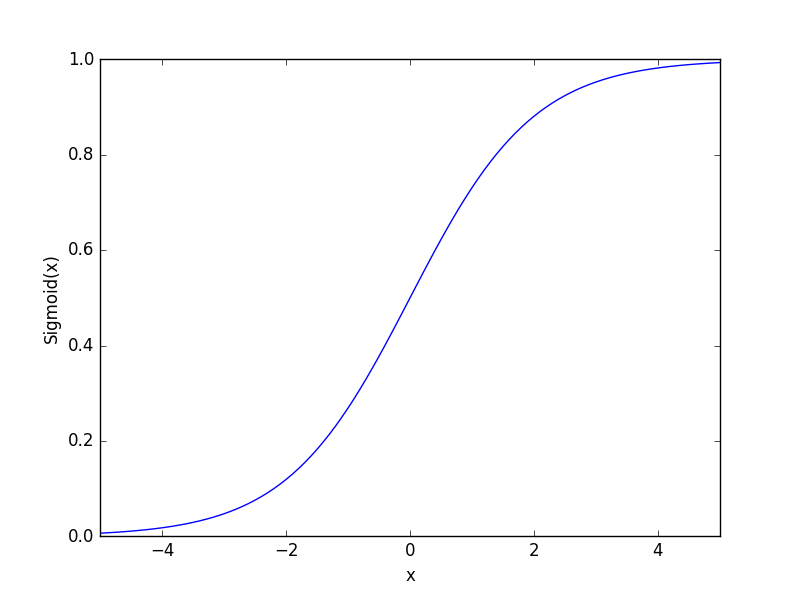
2. Logistic Regression模型及求解
记
hw(x)=11+exp(−wTx)
,那么对于输入
x
,分类结果分别为类别1和0的概率为
p(y=1|x,w)=hw(x)
p(y=0|x,w)=1−hw(x)
该模型可以用一个等式描述:
p(y|x,w)=(hw(x))y(1−hw(x))1−y
模型已经建立,接下来就要构建损失函数。上面以对数几率构建的线性回归模型中,由于
p(y=1)
未知,所以不能用最小二乘法求解,通常采用极大似然法,其损失函数为对数似然函数
然后对损失函数求导。其中,sigmoid函数 hw(x) 对 w 的第j个分量 wj 的偏导为
∂hw(x)∂wj=exp(−wTx)[1+exp(−wTx)]2xj=hw(x)(1−hw(x))xj
那么,损失函数对 wj 的偏导为
由于 y∈{0,1} ,该问题没有解析解,那么就需要借助梯度上升法求解。每一步迭代的更新如下:
wj=wj+α∂J(w)∂wj
其中α为学习率,梯度上升是一个基本的优化求解方法,基于其有改进的随机梯度方法和变学习率方法,此处不再详细介绍。
3. 总结
虽然Logistic Regression给出的是分类的概率属性,但既然是分类,还是要给出具体属于哪一类,通常设定 p(y=1|x,w)>0.5 则归为1类, p(y=1|x,w)<0.5 则归为0类。由于sigmoid函数为单调函数,所以界定了y的概率阈值,就确定了x的分类边界,Logistic Regression通过对数据分类边界的拟合来实现分类。















 7284
7284

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









