







目录
一:Logistic回归简介
Logistic回归是统计学习中的经典分类方法,属于对数线性模型,所以也被称为对数几率回归。该模型是一种分类算法,Logistic回归是一种线性分类器,针对的是线性可分问题。我们要了解Logistic回归进行分类的主要思想是:根据现有的数据对分类边界线建立回归方程,然后以此进行分类。这里回归一词源于最佳拟合参数,表示要找到最佳拟合参数集。
Logistic回归的优点在于计算代价不高,易于理解和实现。缺点是容易发生欠拟合现象,分类的精度不高。适合于数值型和标称型数据进行分类。
1.1基于Logistic回归和Sigmoid函数的分类
我们想要的函数应该是: 能接受所有的输入然后预测出类别。例如,在两个类的情况下,上述函数输出 0 或 1。有一个函数具有类似的性质(可以输出 0 或者 1 的性质),且数学上更易处理,这就是 Sigmoid 函数。 Sigmoid 函数具体的计算公式如下:
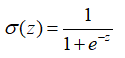
我们可以在每个特征上都乘以一个回归系数,然后将所有值累加,将中国总和带入Sigmoid 函数中,得到一个范围在[0,1]的数值,小于0.5归为0类,导游0.5归为1类。所以Logistic回归可以看出是一种概率估计。
Sigmoid 函数的函数输入记为z,由下面公式得出:
![]()
采用向量的写法可以写成![]() ,它表示 将两个数值向量对于元素相乘然后相加得到z值。x为分类器输入数值,w为我们要找的最佳参数。
,它表示 将两个数值向量对于元素相乘然后相加得到z值。x为分类器输入数值,w为我们要找的最佳参数。
1.2梯度上升法
梯度上升法的基本思想是:找到某个函数的最大值,最好的方法是沿着该函数的梯度方向探寻,梯度记为![]() ,那么f(x,y)的梯度由下面表示:
,那么f(x,y)的梯度由下面表示:
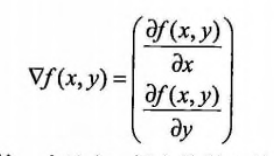
这个梯度意味着沿着x的方向移动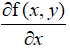 ,沿着y的方向移动
,沿着y的方向移动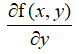 ,其中f(x,y)必须在待计算的点上有定义并且可微。下图是一个具体的例子。从p0开始,计算改点的梯度,然后根据梯度移动到下一个点p1。在p1点,在次计算梯度,并根据新的梯度方向移动到p2。如此循环迭代,直到满足停止条件。迭代的过程中,梯度算法总是保证我们选取到最佳的移动方向。
,其中f(x,y)必须在待计算的点上有定义并且可微。下图是一个具体的例子。从p0开始,计算改点的梯度,然后根据梯度移动到下一个点p1。在p1点,在次计算梯度,并根据新的梯度方向移动到p2。如此循环迭代,直到满足停止条件。迭代的过程中,梯度算法总是保证我们选取到最佳的移动方向。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1525
1525











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









