






《Improving Text Embeddings with Large Language Models》
https://arxiv.org/pdf/2401.00368
文本表示用双塔进行对比学习已经成为业界标配。
本文提出的方法使用标准的对比损失对开源的decoder-only LLMs进行微调,仅使用合成数据和不到1000步的训练,就能获得高质量的文本embedding。而当混合合成数据和标记数据时,在BEIR和MTEB benchmark数据集上取得了SOTA效果。
现有方法的局限性
- 以往的研究显示,预训练word embedding的加权平均是一个强大的语义相似性度量基线,但这些方法无法捕捉自然语言的丰富上下文信息。
- 随着预训练语言模型的出现,如BERT,研究者提出了Sentence-BERT和SimCSE等方法,通过在自然语言推理(NLI)数据集上微调BERT来学习文本嵌入。
- 为了进一步提升文本嵌入的性能和鲁棒性,最先进方法(Contriever、OpenAI Embeddings、E5和BGE等)采用了更复杂的多阶段训练范式,首先在数十亿弱监督文本对上预训练,然后在几个标记数据集上微调。
多阶段训练方法的问题
- 需要复杂的多阶段训练流程,需要花费很多精力研究如何挖掘大量高质量的相关性正负例,以及对比学习策略。
- 依赖于人工收集的数据集,其中部分数据集通常受到任务多样性和语言覆盖范围的限制。
- 大多数现有方法使用BERT风格的编码器作为主干,忽视了训练更好的LLMs和相关技术的最新进展(如上下文长度扩展)。
本文提出的方法
- 使用高级LLMs(如GPT4)为93种语言的数十万个文本嵌入任务生成合成数据。
- 通过两步提示策略,首先让LLMs思考候选任务池,然后根据任务池中给定的任务生成数据。
- 为了覆盖各种应用场景,生成鲁棒性强的文本表示,为每种任务类型设计了多个提示模板,并通过结合不同模板生成的数据来提高多样性。
-
非对称任务
这一类包括查询和文档在语义上相关但不是同义的任务。根据查询和文档的长度,进一步细分为四个组:短-长、长-短、短-短和长-长匹配。例如,短-长匹配任务涉及一个短查询和一个长文档,这是商业搜索引擎中的典型场景。对于每个组,我们设计了两步提示模板,首先提示LLMs思考任务列表,然后根据任务定义生成具体示例。在图1中,我们展示了短-长匹配子组的示例提示。GPT-4的输出大多是连贯和高质量的。在我们的初步实验中,我们还尝试使用单个提示生成任务定义和查询-文档对,但数据多样性不如提出的两步方法好。
-
对称任务
对称任务涉及查询和文档具有相似的语义含义但表面形式不同的任务。本文测试了两种应用场景:单语语义文本相似性(STS)和双文本检索。针对场景设计了两种不同的提示模板,以适应它们特定的目标。为了进一步增强提示的多样性,从而增强合成数据的多样性,我们在每个提示模板中加入了几个占位符,其值在运行时随机采样。例如,在图1中,“{query_length}”的值从集合“{少于5个词,5-10个词,至少10个词}”中采样。
为了生成多语言数据,我们从XLM-R的语言列表中采样“{language}”的值,对高资源语言给予更多权重。任何不符合预定义JSON格式的生成数据在解析过程中都被丢弃。还通过精确字符串匹配去重。
-
-
训练
给定一个相关的查询-文档对 (q+, d+),我们首先应用以下指令模板到原始查询q+ 以生成一个新的查询 q+_inst:
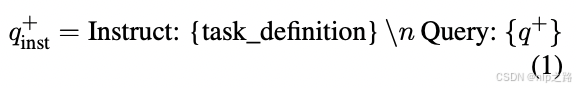
-
其中,“{task_definition}”是一个占位符,一句话描述任务。对于生成的合成数据,我们使用头脑风暴步骤的输出。对于其他数据集,如MS-MARCO,我们手动制作任务定义prompt并将其应用于数据集中的所有query。我们不修改文档侧的任何指令前缀。通过这种方式,文档索引可以预建,我们可以通过改变查询侧来定制执行的任务。
给定一个预训练的LLM,我们在查询和文档的末尾附加一个[EOS]标记,然后将它们输入LLM,通过取最后一层[EOS]向量获得查询和文档嵌入 (hq+_inst, hd+)。为了训练嵌入模型,我们采用了标准的InfoNCE损失L,覆盖batch内随机采样负例和难负例:
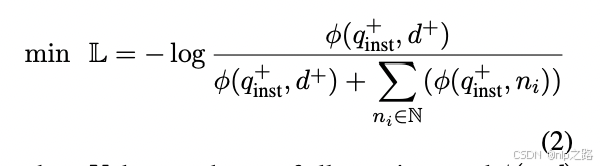
-
其中N表示所有负样本的集合,φ(q, d) 是一个计算查询q和文档d之间匹配分数的函数。在本文中,我们采用了以下的温度缩放余弦相似度函数:
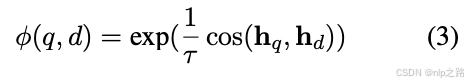 τ是一个温度超参数,在实验中固定为0.02。
τ是一个温度超参数,在实验中固定为0.02。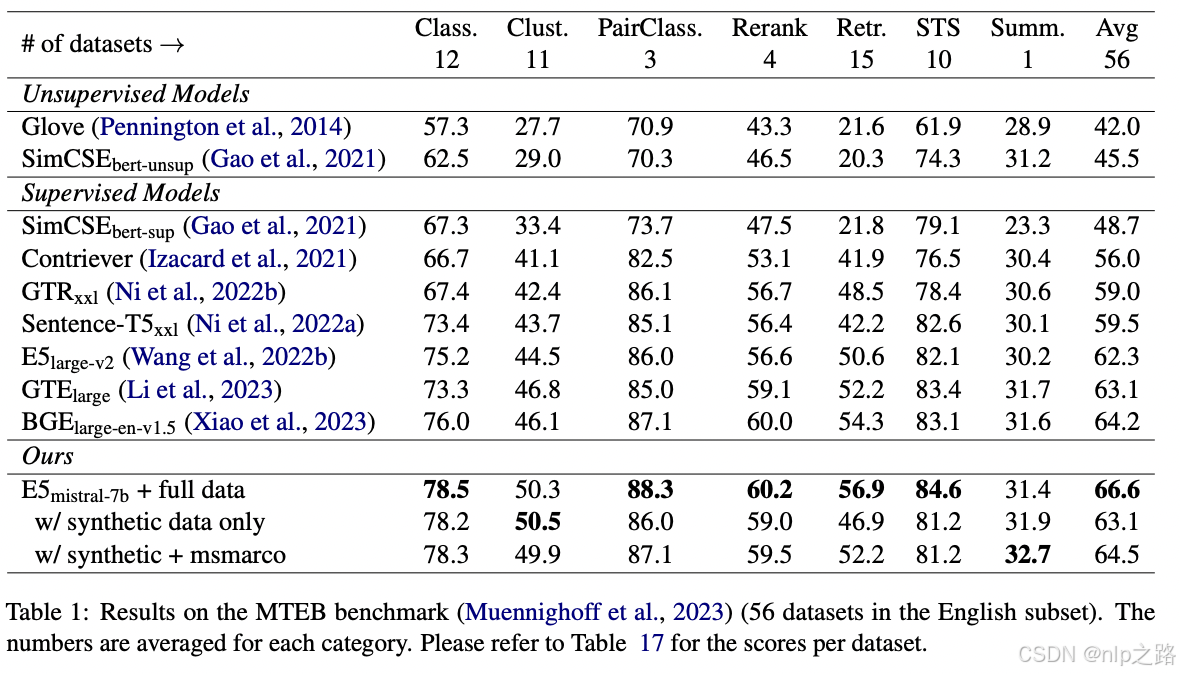
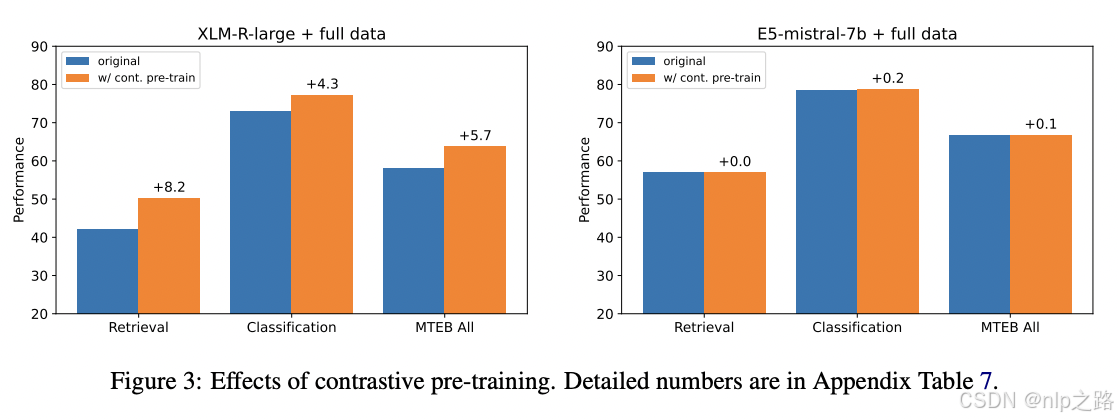
- 另外值得注意的是,本文还重验证了对比预训练的效果,对比预训练对XLM-R-large有益,当在相同数据上微调时,其检索性能提高了8.2点,这与之前的发现一致。然而,对于基于Mistral-7B的模型,对比预训练对模型质量的影响微乎其微。这意味着广泛的自回归预训练使LLMs能够获得良好的文本表示,只需要最小的微调就可以将它们转化为有效的嵌入模型。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









