






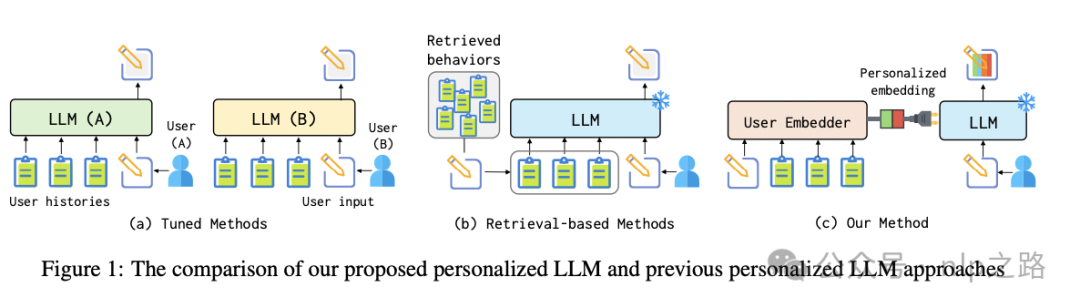
LLM目前最有前景的应用之一就是超级助手,其中个人超级助手早晚躲不开个性服务,因为即使有相同需求的用户,也可能偏好不同的输出。以通用人工智能著称的LLM又要怎么开启个性化服务呢?
给每个用户单独微调一个LLM在toC端肯定是不现实的,即使是用各种PEFT的奇淫巧技,也能把公司底裤都亏没了。
最简单的,历史对话可以和当前输入拼接一起输入LLM中得到上下文相关的回答。这种适用于冷启,但使用时间久了,对话内容多,计算量超标不说,也可能引入噪声干扰模型的回答。
稍好一点的利用RAG,检索历史对话有可能有信息增益的部分作为输入补充信息。但这种硬抽取的策略可能会打断用户历史的连续性,并且无法捕捉到用户的整体风格和模式,导致性能不佳。
还有没有别的方法?譬如现有个性化推荐系统中的做法,将user embedding/user行为历史/user属性信息 作为特征输入到模型中,算是soft RAG?
人大和百度联合发表的这篇论文《LLMs + Persona-Plug = Personalized LLMs》正是提出了这个思路的一种解决方案。我们主要了解下是如何提炼user embedding和怎么输入LLM实现个性化信息注入的。
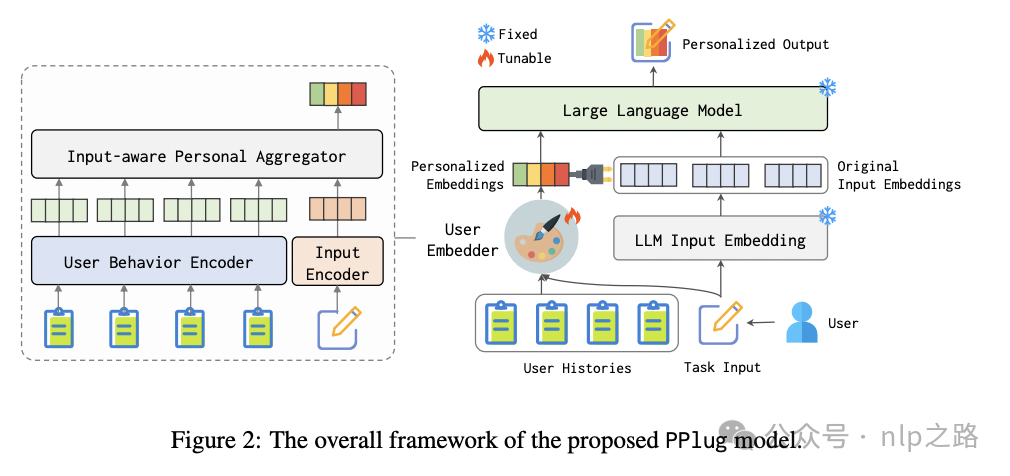
用了轻量的双向attention模型作为encoder(BGE-based,约220M),为保障训练稳定性,用户历史的encoder固定参数,只finetune当前输入的encoder。
得到历史embedding和当前输入的embedding后,需要有个信息交互/融合模块,得到最终的user embedding,其实套路跟个性化推荐中的基本一样,就是attention:
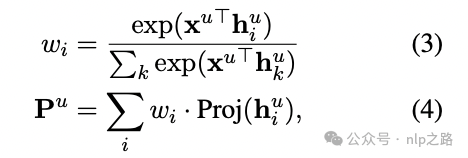
其中Proj(2层MLP)是将encoder空间映射到LLM空间。
那怎么输入LLM呢?
在最前面拼接Instruction embedding(前人研究这有助于让模型注意到指令需求,和其他常规任务区分开,其实就是soft prompt),然后是上面得到的user embedding,接着是用户当前输入,让LLM输出。训练时LLM参数固定,只微调Instruction embedding、encoder和Proj的参数。这样去掉这些个性化插件,原来的模型还是正常用,加进去就实现个性化功能,实现插件可灵活插拔。
最终结果也是好于现有Retrieval Base Personalized的方法的。
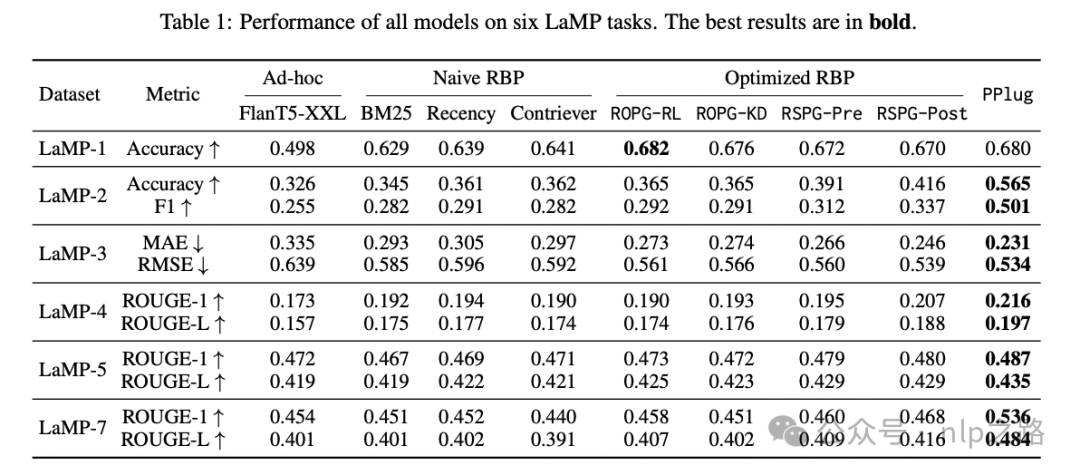
这个头一开,接下来就可以把推荐的那些用户行为序列建模的各种套路都抄过来了,什么各种类型的序列,超长序列,各种attention交互,来提炼更好的user embedding,enjoy yourselves
附录
https://arxiv.org/pdf/2409.11901
https://huggingface.co/BAAI/bge-base-en-v1.5
欢迎微信扫码关注nlp之路,发送LLM领取奖品~



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









