






本周四,OpenAI发布了新消息,通过用强化学习生成更优的思维链,在给出答案之前先通过生成思维链进行思考,在数/理/化/生、IOI信息学竞赛等对逻辑推理要求较高的领域中表现惊艳,甚至超过人类博士,给大模型迈向通用人工智能的道路打开了新的想象空间。对于复杂推理任务,这是个里程碑式的进展,代表人工智能认知能力新水平,因此OpenAI将计数器重置为1,并将这一系列命名为OpenAI o1。
先来感受一下,什么叫震撼:
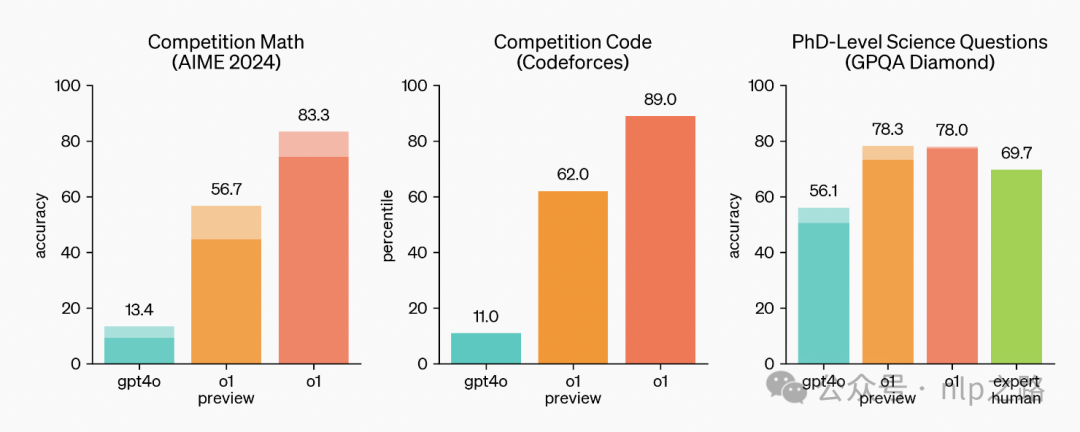
AIME2024是个高水平的数学竞赛,GPT4o的准确率为13.4%,o1的准确率直接干到了83.3%,编程竞赛,GPT4o是成绩是11%,o1干到了89%,博士级科学问题GPQA,人类专家是69.7%,o1直接碾压到了78%。
OpenAI官方给了一张图,非常有含金量:
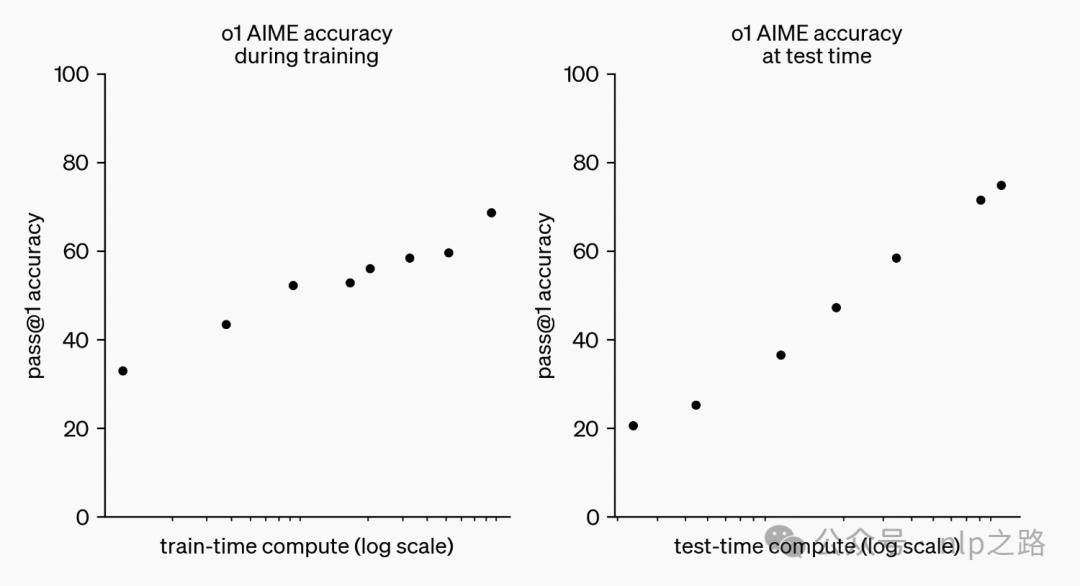
传统LLM的scaling law主要是模型数据量和模型参数量,侧重pretrain和postpretrain阶段,但由于自然语言符合zipf’s law,一味增多训练数据,其实还是强者恒强,补充的知识大概率原来的训练数据就有的,对模型带来新信息的边际效能会逐渐递减,而从开源模型和闭源模型之间的差距在逐渐缩小也可以看出,再依靠大力出奇迹去卷数据量卷参数量,不太好使了。而OpenAI这张图带给我们新的信息--推理阶段也有scaling law。
推理缩放定律:指的是模型推理时间越长,推理效果会越好。且以最佳方式扩展LLM测试时的计算量可能比扩展模型参数更有效。OpenAI应该早在学术界之前就发现了这一定律并实践成功,而学术界是近一个月左右才发现:Snell等人发现,PaLM 2-S通过测试时间搜索,在MATH上的表现优于一个14倍大的模型(《Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters》,https://arxiv.org/pdf/2408.03314)。
o1模型在训练和推理两个scaling law下双驱动,实现了性能提升。给大语言模型的效果优化带来了新的方向。
诺贝尔经济学奖得主丹尼尔-卡尼曼有一本著作《思考,快与慢》里面介绍了人类大脑的信息处理主要分为两个系统,第一个系统是快思考,偏经验记忆型,反应速度快,但欠缺思考容易出错;第二个是慢思考,偏逻辑推理型,反应速度慢,但思考的结果相对会更可靠。当输入经过第二系统处理的结果都符合一定规律,就会内化成记忆和经验,之后转由第一系统处理,以提高大脑处理信息的效率,同时降低大脑的能耗。OpenAI的这个推理阶段的scaling law,就是让模型慢思考。
而实现这个的功能的关键,是Self-replay RL,其实就是AlphaGo的自我博弈。当模型在回答一个复杂问题时,它就会进行一个类似Self-play的过程。模型会生成多个可能的思路,然后评估这些思路的质量,选择最佳的一个。通过自我探索、试错、完善思维链策略,模型学会将复杂问题分解为更简单的步骤,且当当前的方法不起作用时,模型也会尝试其他的策略,不断识别和纠正自己的错误。一旦答案正确,则中间推理的结果就可以形成数据飞轮,作为正reward和负reward,继续供模型训练完善,这比传统cot靠人类专家昂贵的标注样本效率高多了,上限也高多了。
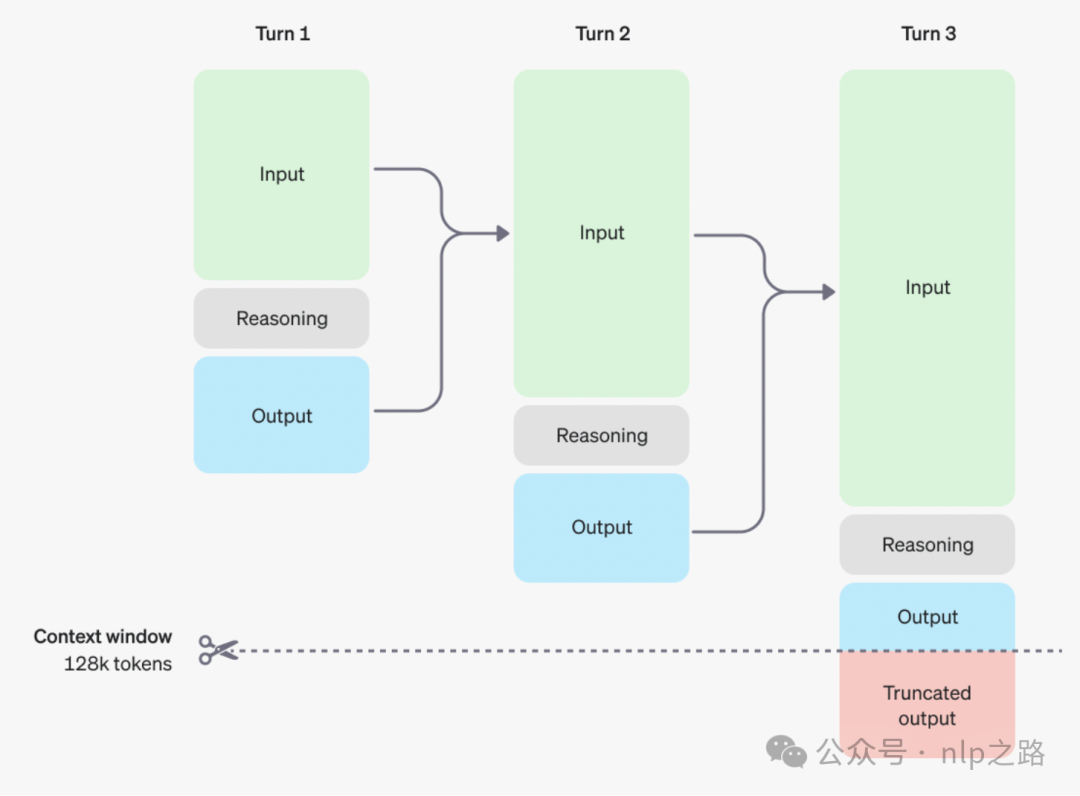
https://platform.openai.com/docs/guides/reasoning?reasoning-prompt-examples=coding-planning
而推理时,引入了reasoning tokens,告诉模型去拆碎对prompt的理解,并考虑多个方法去产生最后的答案,产生答案并作为可见的token后,模型删掉之前的reasoning tokens。对于多轮问答,则如上图所示,每轮都保留用户输入和系统的输出,但对中间的reasoning token则删掉,不作为模型的输入。直到达到128k个token的上限,则截断输出。
这个其实是对next token prediction的一个扩展。预测不仅仅是局限在next token,文字的输出背后可能会有很多思考的痕迹,而OpenAI这种做法,正是建模这种文字背后思考的痕迹,让模型学会思考。
类似的研究有半年前斯坦福的《Quiet-STaR: Language Models Can Teach Themselves to Think Before Speaking》这篇论文,https://arxiv.org/pdf/2403.09629。
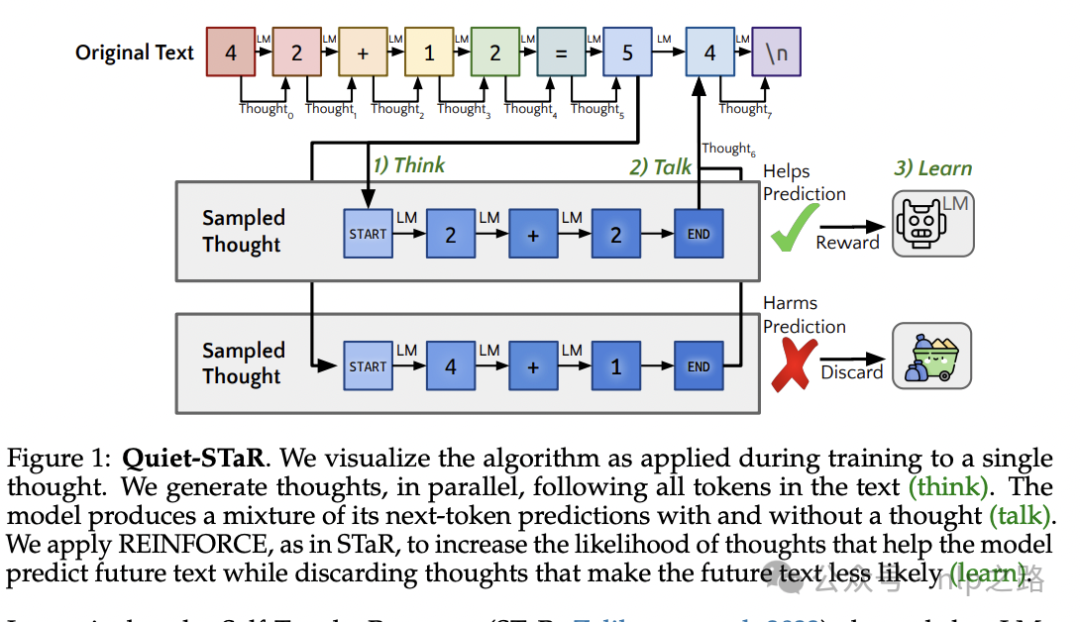
如上图,模型会并行的生成多个思路/想法,然后根据每个思路加与不加,对模型预测出正确的下一个token的似然概率是有益还是有害作为reward,用强化学习探索出更优的生成和选择候选思路的策略,这样不断提高模型逻辑推理的水平。

这本质上就是模型自己来生产并决定用什么prompt来引导自己输出更好的结果了,也意味着,之前那一批prompt工程师们又要失业了。
意料之中,却比想象中更快。
我很早之前了解过prompt learning,但自己却很少去研究过prompt要怎么写。因为在我的认知里,prompt工程师是用一种黑盒测试的方式,来适应人对大模型的使用。当设计出来的prompt跟模型训练数据分布越相似,效果就会越好。不管是hack中了模型的训练数据,还是hack中了模型的泛化方向,本质都是一种投机。以人去适应特定机器所获得的技能,衰退的速度会远超想象。机器一旦升级更新,人类针对旧机器积累的技能很可能不再有效。
我们回到LLM的落地。
AI要产生比较可观的经济效益,主要有两种落地姿势:+AI,AI+。
+AI,是大部分公司目前的做法,即在已有的系统或者业务下,使用AI技术进行优化,提高系统效率,降本增效,大部分都属于中小型创新,常见于各种大厂或成熟业务;
AI+,是以AI技术为核心,重新定义产品解决方案,相比现有的解决方案,用户体验需要好上好几倍,而不是仅仅好一点,才能有足够的势能让用户甘愿完成解决方案的切换。
企业在技术落地时决策用+AI还是AI+,需要考虑两个方面:
一是AI在全业务流程的价值链占比。如果很小,比如只有10%,则比较适合+AI策略。因为还需要补全剩余90%,而这可能在产业深耕多年的公司已经具备,仅靠AI胜算不大。如电商行业,即使没有chatgpt,依然能依靠已有的搜索和推荐建立人-货-场连接,商家依然可以通过提供优质的产品和服务,通过线上线下积累的渠道完成价值交换。
二是AI是否具备护城河。如果具备形成护城河,则AI+的策略会更有胜算。因为后来者因为护城河的原因,要追赶需要付出更大的代价。如OpenAI的chatgpt,不仅仅是技术壁垒,在超高的人气加持下,用户不断产生的系统交互日志,会帮他们建立品牌认知,也不断帮他们及时发现用户在bot场景下的真实使用需求,进而继续迭代完善他们的模型服务。
根据这两个标准,可以划分出四个象限,如下图所示。
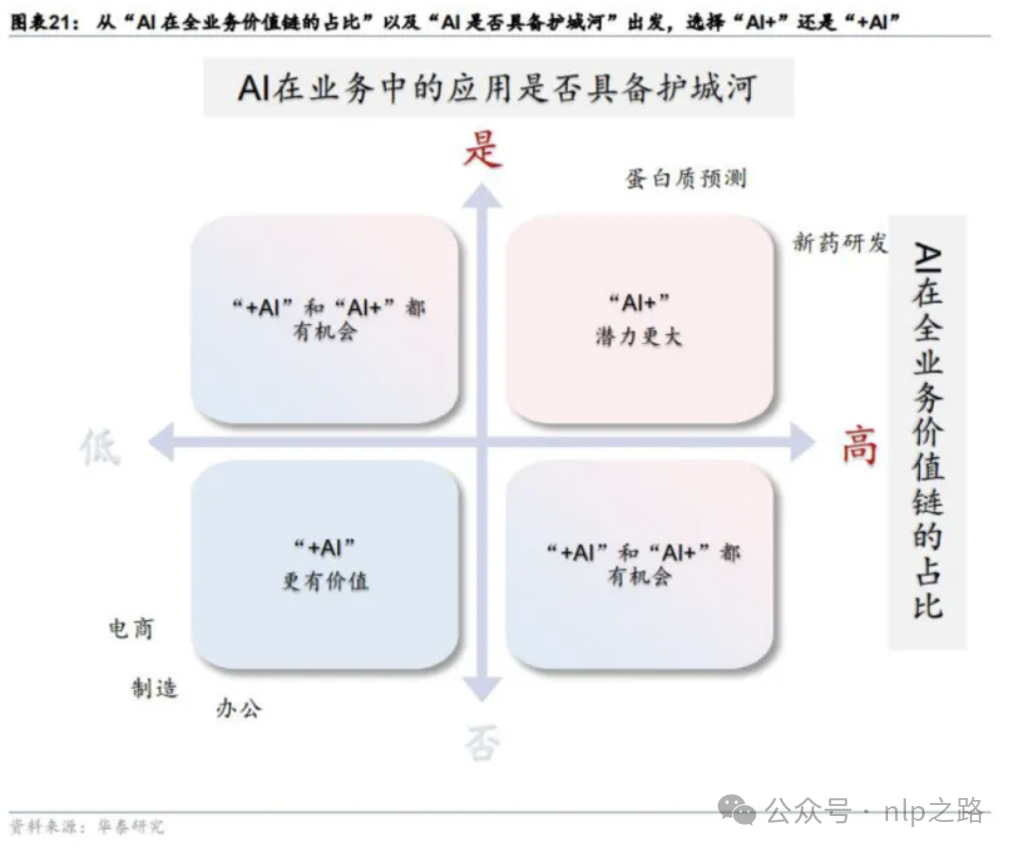
而o1模型的成功,意味着大语言模型除了传统的偏文科型的领域外,进一步进军理工型领域的应用。现实世界的问题,有不少是需要逻辑推理的,短期内即使人类专家也不太容易取得突破性成果的,如研发新药、开发新电池等。这些都主要对应到上图的右上角象限,发展空间比原来更大了。
只要用户需求够痛,生成的结果就算不一定正确,但也可能给人类带来有价值的启发,那么即使推理时间长,如几小时、几天甚至几周,相信也会有人接受并愿意尝试的。而随着端上推理分担计算量和工程性能优化,推理的算力成本或者时间成本也一定会慢慢得到解决。
预测未来的趋势还是会有一个类似Agent(侧重工程)或者MOE(侧重模型)的系统,去针对不同的问题,决定使用侧重记忆型的模型,还是推理型的模型,或者多个模型结果整合。
欢迎微信扫码关注公众号 nlp之路, 回复LLM, 免费领取LLM相关资料
















 726
726

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









