






今天介绍的这篇文章是关于小型语言模型(Small Language Models, SLMs)的研究综述,作者团队来自北京邮电大学、鹏城实验室、Helixon Research、剑桥大学等机构。
语言模型的发展目前呈现出分歧,一方面是追求人工通用智能的LLMs,在训练和推理双scaling law的指引下不断加大计算量;另一方面是为了ROI考虑,快速迭代、低成本训练&推理而提出的SLMs。
前者是为了扩宽现有通用人工智能技术解决问题能力的边界,是仰望星空,在各种自媒体资讯的轰炸中,已经处于舞台灯光的中心;
后者是为了加速LLM在各个领域的落地,是脚踏实地,是让LLM这波技术革命发挥经济效益的关键假设,幕后坚强的后盾。
论文调研了59个最先进的开源SLMs,分析了它们的技术创新,包括架构、训练数据集和训练算法。
模型架构
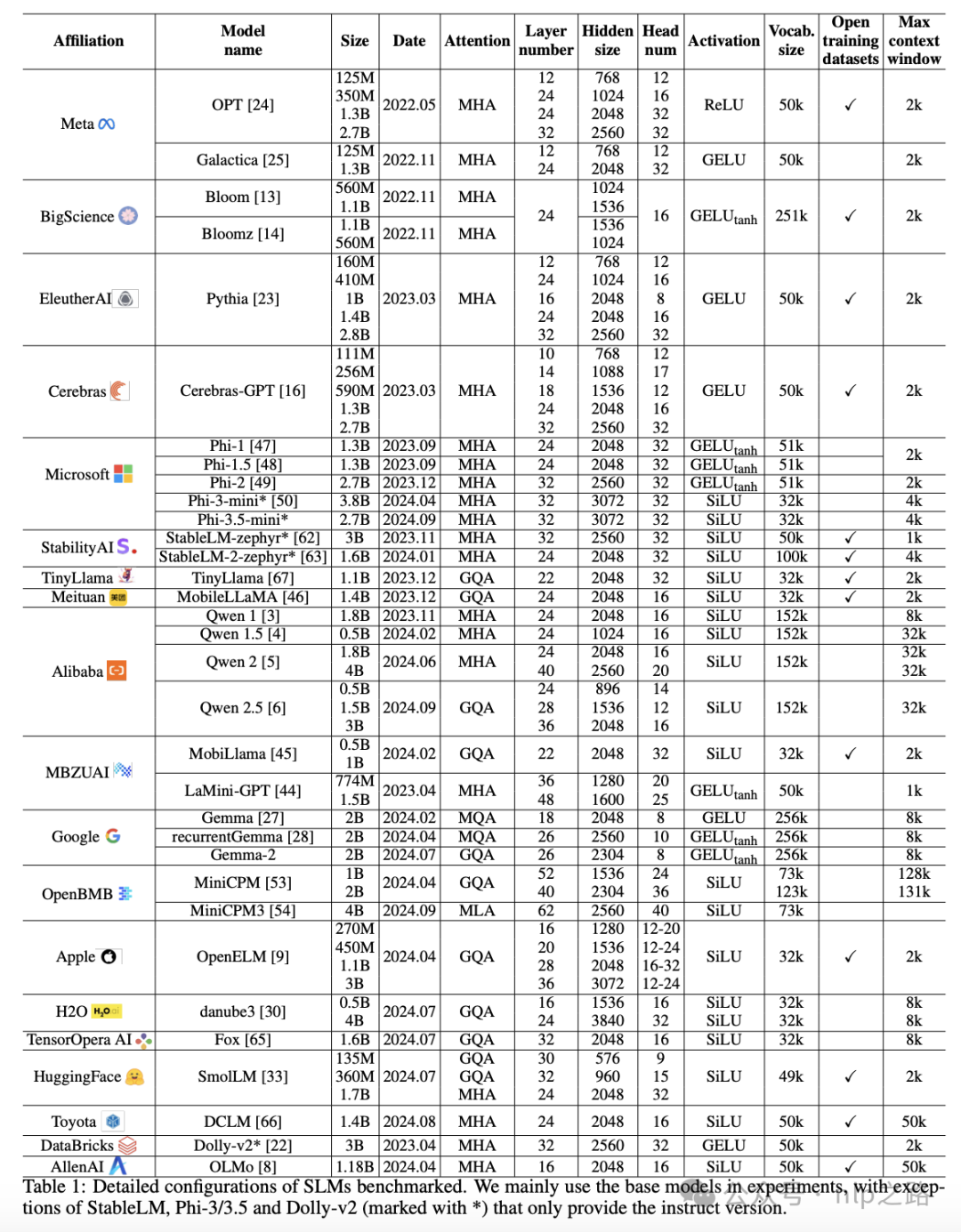
SLMs通常采用基于Transformer的decoder架构,参数范围在100M到5B之间。
作者们对的几个主要组成部分进行了详细的统计分析:
-
自注意力的类型:自注意力机制是Transformer模型的核心。SLMs主要使用以下四种注意力机制之一:多头自注意力(Multi-Head Attention, MHA)、多查询注意力(Multi-Query Attention, MQA)、组查询注意力(Group-Query Attention, GQA)和多头潜在注意力(Multi-Head Latent Attention, MLA)。这些机制的不同之处在于它们处理输入数据的方式,例如MHA通过多个注意力头同时关注输入数据的不同部分,而MQA、GQA和MLA则通过不同的方式减少计算复杂性。
-
前馈神经网络的类型:前馈网络可以分为标准前馈网络(Standard FFN)和带门控的前馈网络(Gated FFN)。标准前馈网络是一个带有激活函数的两层神经网络,而带门控的前馈网络则增加了额外的门控层。
-
FFN的中间比率:FFN的中间比率是指中间维度与隐藏维度的比率。不同的FFN配置对模型的性能和效率有不同的影响。
-
FFN的激活函数:FFN使用的激活函数主要有四种:ReLU(Rectified Linear Unit)、GELU(Gaussian Error Linear Unit)、GELUtanh和SiLU(Sigmoid Linear Unit)。不同的激活函数对模型的非线性处理能力有影响。
-
层归一化类型:层归一化主要有LayerNorm和RMSNorm两种类型。归一化是用于稳定训练过程和加速收敛的技术。
-
词汇量大小:词汇量是模型能够识别的独特标记的总数。词汇量的大小直接影响模型处理语言的能力。
作者们还讨论了SLMs在架构上的创新,包括参数共享和逐层参数缩放等技术。参数共享是通过在不同层或网络组件之间重用同一组权重来减少参数数量,从而提高训练和推理的效率。逐层参数缩放则是允许模型中的每个Transformer层有不同的配置,以便更好地利用可用的参数预算。
训练数据
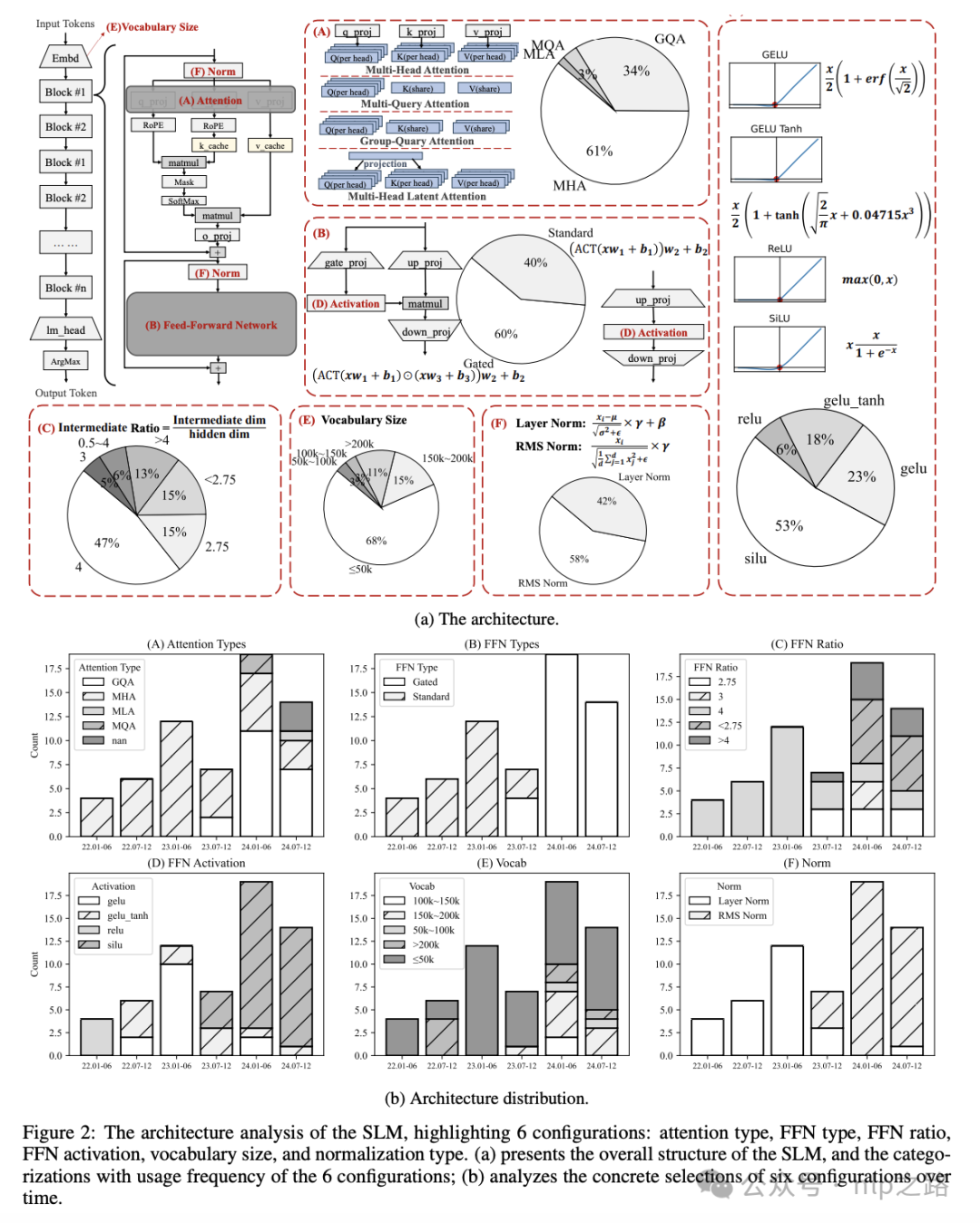
作者发现共有12个这样的数据集被用于训练SLMs,这些数据集的多样性和质量直接影响了模型的性能。
-
The Pile (825B tokens): 这是一个由多个较小的、不同领域的语料库组合而成的大型数据集。
-
FineWeb-Edu (1.3T tokens): 从FineWeb中筛选出来的教育文本的集合。
-
StarCoder (35B tokens): 包含Python代码的语料库。
-
Cosmopedia (25B tokens): 由Mixtral-8x7B-Instruct-v0.1生成的合成教科书、博客文章、故事、帖子和WikiHow文章的数据集。
-
RefinedWeb (5T tokens): 从CommonCrawl中提取的经过广泛筛选的、高质量的网页数据。
-
RedPajama (1.2T tokens): 包括来自84个CommonCrawl快照的超过100B个文本文件,并使用CCNet管道进行处理。
-
Dolma : 一个英语语料库,使用MinHash算法进行了内部和跨语料库的去重。
-
WuDaoCorpora(4T tokens): 一个超大规模的中文语料库,包含约3T的训练数据和1.08T的汉字。
-
RoBERTa CCNewsV2: 包含CommonCrawl新闻数据集的英文部分的更新版本。
-
PushShift.io Reddit: 自2015年以来收集Reddit数据并供研究人员使用的社交媒体数据收集、分析和归档平台。
-
DCLM-baseline (1.35T tokens): 从Common Crawl提取的标准语料库,基于OpenLM框架的有效预训练配方,以及53个下游评估的广泛套件。
-
CulturaX (6.3T tokens): 一个庞大的多语言数据集,包含167种语言。
作者们还对这些数据集的使用偏好进行了统计分析,发现数据集的选择随着时间的推移而多样化。例如,The Pile在2022年和2023年被广泛使用,但最近逐渐被其他数据集所取代,如RefinedWeb和RedPajama。
此外,作者们还探讨了预训练数据集的质量对SLMs性能的影响。他们根据模型在常识推理和问题解决任务上的平均准确率,将过去三年的SLMs分为小于0.5B、1B、2B和3B的参数组,并分析了这些数据集的质量。研究发现,最近发布的两个数据集,DCLM和FineWeb-Edu,由于采用了基于模型的数据过滤,因此在性能上显示出了优越性。
训练算法
在这一部分,文章探讨了用于提升小型语言模型(SLMs)性能的几种创新训练方法。这些方法致力于通过改进模型的学习能力和知识迁移效率,从而提高模型在实际应用中的表现。
-
最大更新参数化(Maximal Update Parameterization, µP):
-
这种方法控制初始化、逐层学习率和激活幅度,以确保模型训练在不同层宽度下都能保持分析上的稳定性。
-
除了提高训练稳定性外,µP还提高了训练超参数(尤其是学习率)从小规模模型到大规模模型的可转移性。
-
例如,Cerebras-GPT就是使用最大更新参数化来训练模型的。
-
-
知识蒸馏(Knowledge Distillation):
-
知识蒸馏是大型语言模型(LLMs)领域的一个重要概念,它涉及从大型复杂的教师模型中提取有价值的知识,并将其传递给更小、更高效的学生模型。
-
该技术的核心是让学生模型学习接近教师模型的行为和预测,通过最小化两者输出之间的差异来实现。
-
例如,LaMini-GPT和Gemma-2就采用了知识蒸馏技术。
-
-
二阶段预训练策略(Two Stage Pre-training Strategy):
-
这种策略涉及将模型训练分为两个不同的阶段。
-
在预训练阶段,模型仅使用大规模但质量较低的预训练数据,这些数据量大且能支持持续训练,尤其是在提供更多计算资源的情况下。
-
在退火阶段,使用多样化和高质量的特定领域预训练数据,这些数据被混合到预训练数据中。
-
MiniCPM采用了二阶段预训练策略。
-
这些训练算法的引入和应用,为SLMs的性能提升和应用范围拓展提供了新的可能性。通过这些方法,研究者能够更有效地利用有限的资源来训练出性能更强的模型,同时保持模型的尺寸和运行成本在可接受的范围内。
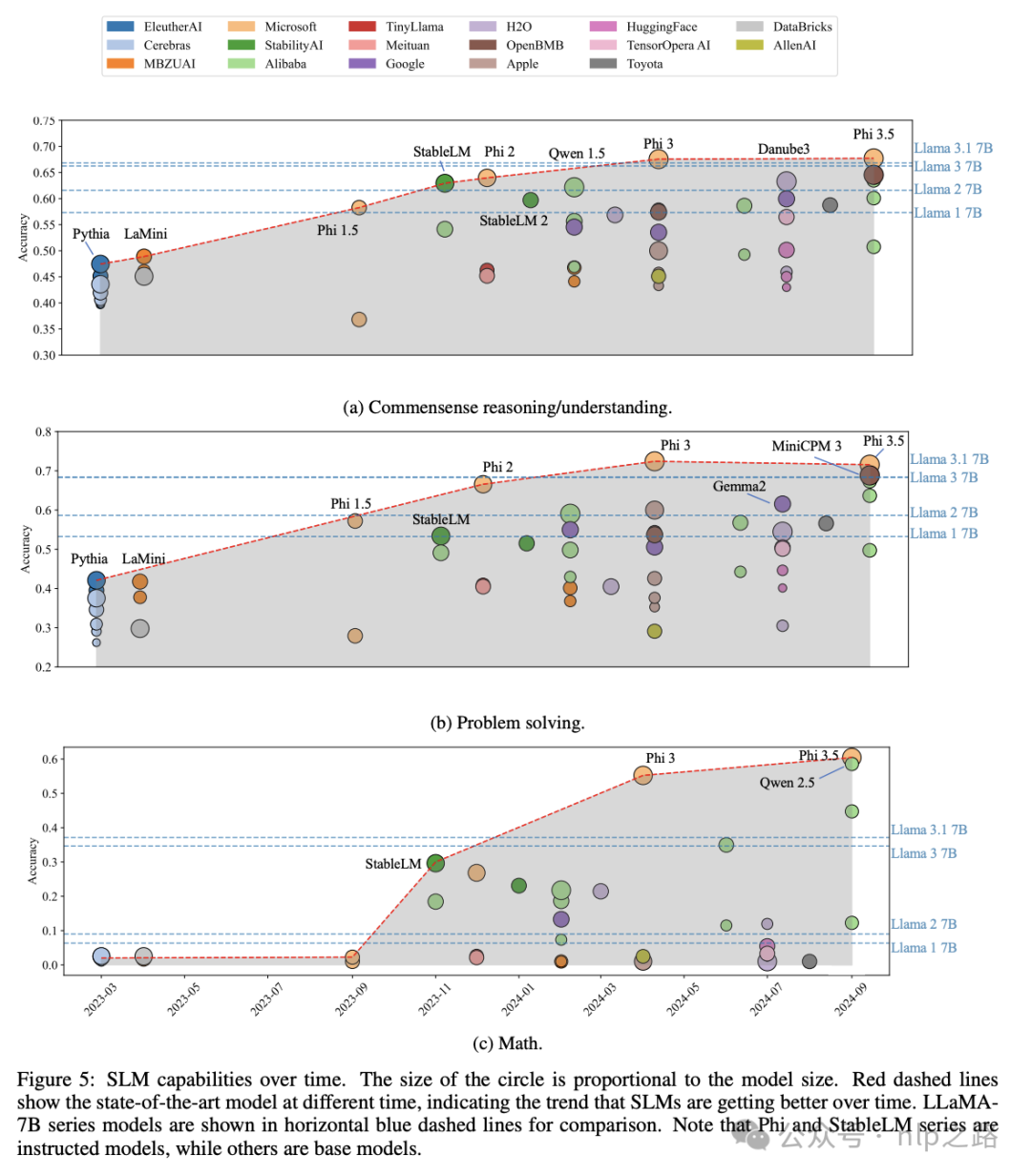
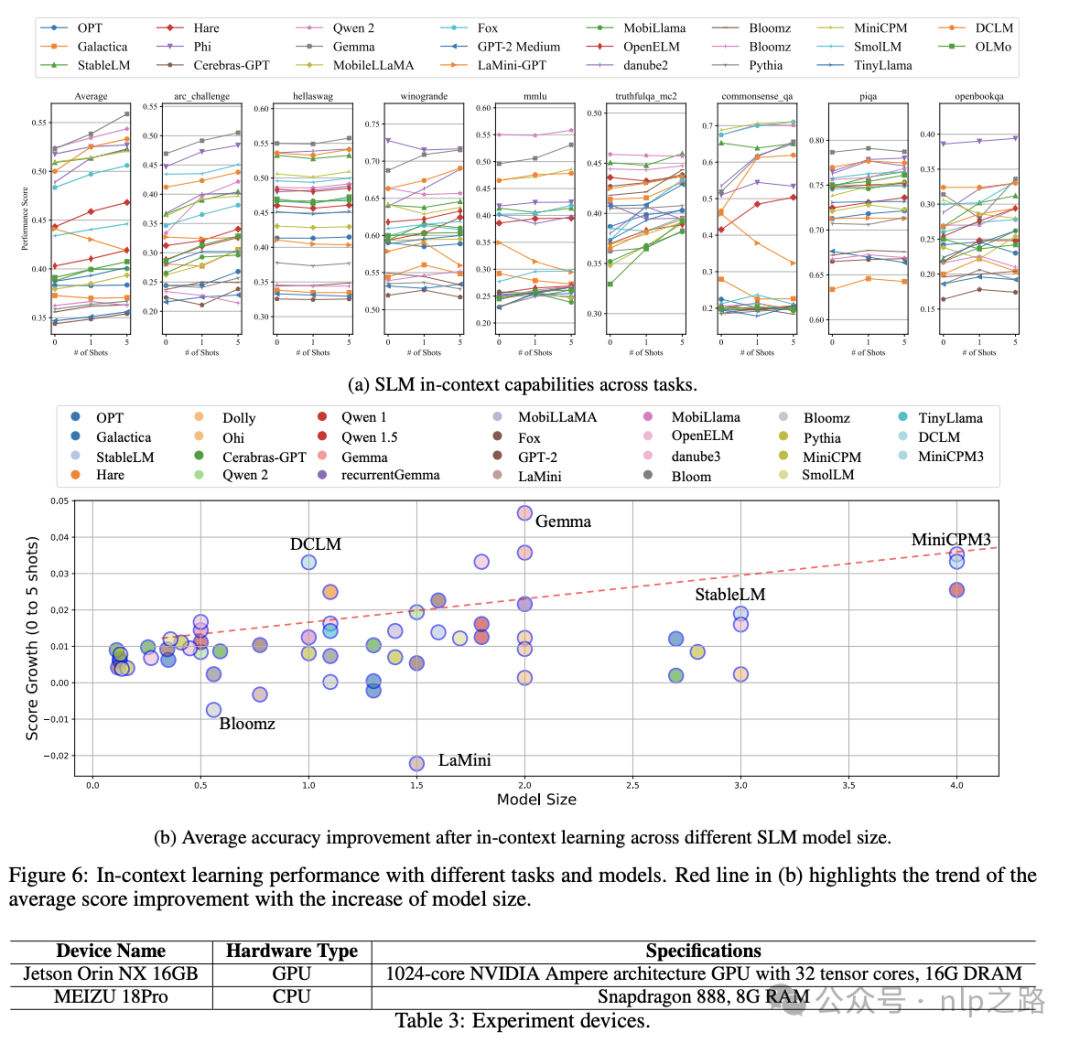
SLM的能力
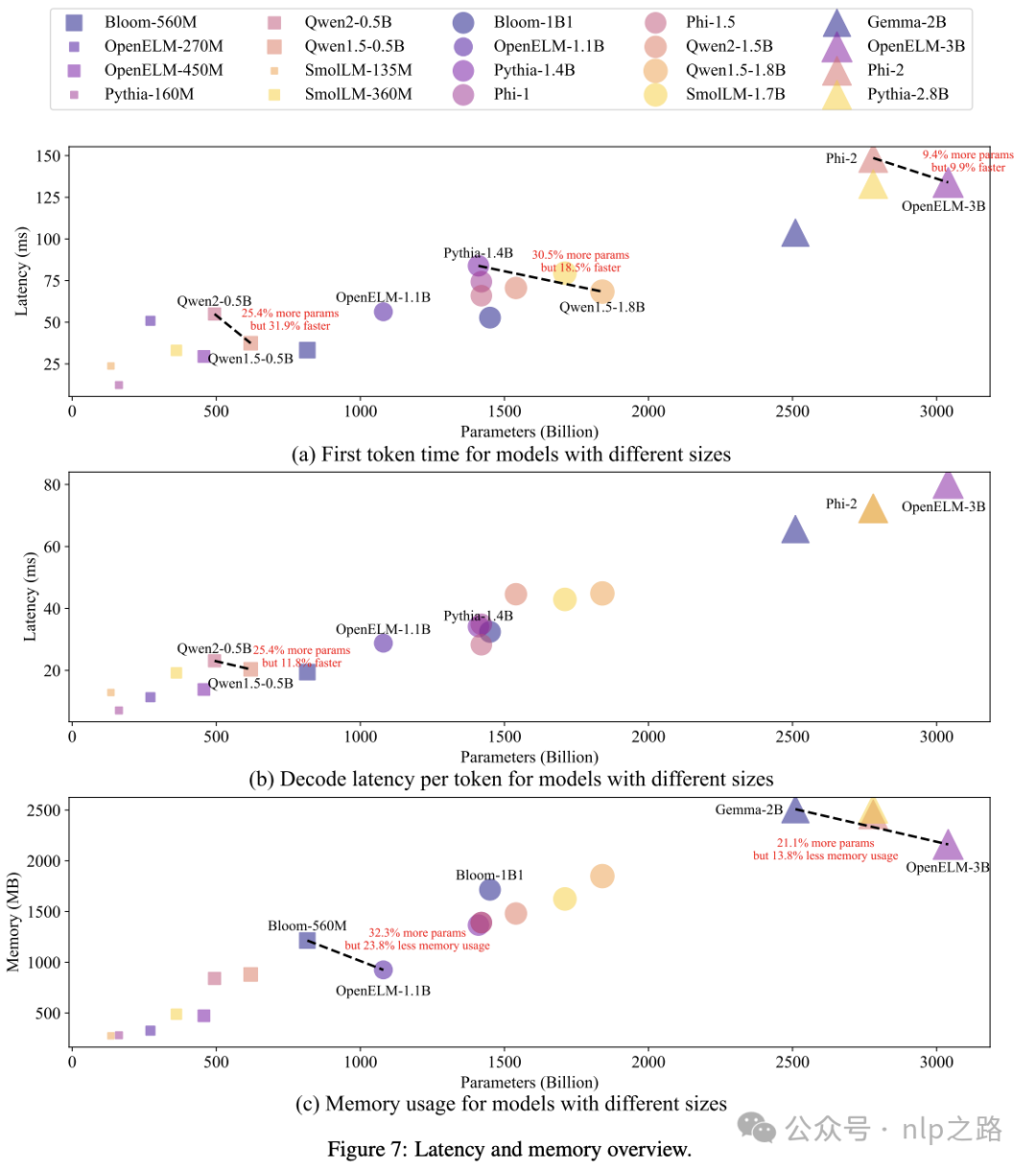
SLM运行成本
附录:
https://arxiv.org/pdf/2409.15790
欢迎微信扫码关注nlp之路,发送LLM领取奖品~


















 1897
1897

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









