







<h1><a name="t0"></a>如何简单形象又有趣地讲解神经网络是什么?</h1>
0. 分类
神经网络最重要的用途是分类,为了让大家对分类有个直观的认识,咱们先看几个例子:
- 垃圾邮件识别:现在有一封电子邮件,把出现在里面的所有词汇提取出来,送进一个机器里,机器需要判断这封邮件是否是垃圾邮件。
- 疾病判断:病人到医院去做了一大堆肝功、尿检测验,把测验结果送进一个机器里,机器需要判断这个病人是否得病,得的什么病。
- 猫狗分类:有一大堆猫、狗照片,把每一张照片送进一个机器里,机器需要判断这幅照片里的东西是猫还是狗。
这种能自动对输入的东西进行分类的机器,就叫做分类器。
分类器的输入是一个数值向量,叫做特征(向量)。在第一个例子里,分类器的输入是一堆0、1值,表示字典里的每一个词是否在邮件中出现,比如向量(1,1,0,0,0......)就表示这封邮件里只出现了两个词abandon和abnormal;第二个例子里,分类器的输入是一堆化验指标;第三个例子里,分类器的输入是照片,假如每一张照片都是320*240像素的红绿蓝三通道彩色照片,那么分类器的输入就是一个长度为320*240*3=230400的向量。
分类器的输出也是数值。第一个例子中,输出1表示邮件是垃圾邮件,输出0则说明邮件是正常邮件;第二个例子中,输出0表示健康,输出1表示有甲肝,输出2表示有乙肝,输出3表示有饼干等等;第三个例子中,输出0表示图片中是狗,输出1表示是猫。
分类器的目标就是让正确分类的比例尽可能高。一般我们需要首先收集一些样本,人为标记上正确分类结果,然后用这些标记好的数据训练分类器,训练好的分类器就可以在新来的特征向量上工作了。
1. 神经元
咱们假设分类器的输入是通过某种途径获得的两个值,输出是0和1,比如分别代表猫和狗。现在有一些样本:
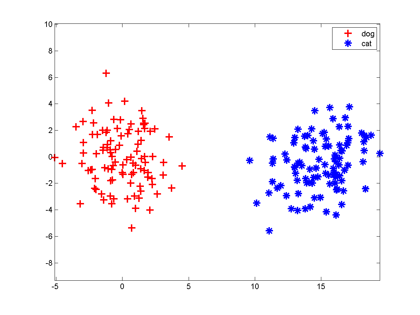
大家想想,最简单地把这两组特征向量分开的方法是啥?当然是在两组数据中间画一条竖直线,直线左边是狗,右边是猫,分类器就完成了。以后来了新的向量,凡是落在直线左边的都是狗,落在右边的都是猫。
一条直线把平面一分为二,一个平面把三维空间一分为二,一个n-1维超平面把n维空间一分为二,两边分属不同的两类,这种分类器就叫做神经元。
大家都知道平面上的直线方程是,等式左边大于零和小于零分别表示点
在直线的一侧还是另一侧,把这个式子推广到n维空间里,直线的高维形式称为超平面,它的方程是:
神经元就是当h大于0时输出1,h小于0时输出0这么一个模型,它的实质就是把特征空间一切两半,认为两瓣分别属两个类。你恐怕再也想不到比这更简单的分类器了,它是McCulloch和Pitts在1943年想出来了。
这个模型有点像人脑中的神经元:从多个感受器接受电信号,进行处理(加权相加再偏移一点,即判断输入是否在某条直线
的一侧),发出电信号(在正确的那侧发出1,否则不发信号,可以认为是发出0),这就是它叫神经元的原因。
当然,上面那幅图我们是开了上帝视角才知道“一条竖直线能分开两类”,在实际训练神经元时,我们并不知道特征是怎么抱团的。神经元模型的一种学习方法称为Hebb算法:
先随机选一条直线/平面/超平面,然后把样本一个个拿过来,如果这条直线分错了,说明这个点分错边了,就稍微把直线移动一点,让它靠近这个样本,争取跨过这个样本,让它跑到直线正确的一侧;如果直线分对了,它就暂时停下不动。因此训练神经元的过程就是这条直线不断在跳舞,最终跳到两个类之间的竖直线位置。
2. 神经网络
MP神经元有几个显著缺点。首先它把直线一侧变为0,另一侧变为1,这东西不可微,不利于数学分析。人们用一个和0-1阶跃函数类似但是更平滑的函数Sigmoid函数来代替它(Sigmoid函数自带一个尺度参数,可以控制神经元对离超平面距离不同的点的响应,这里忽略它),从此神经网络的训练就可以用梯度下降法来构造了,这就是有名的反向传播算法。
神经元的另一个缺点是:它只能切一刀!你给我说说一刀怎么能把下面这两类分开吧。
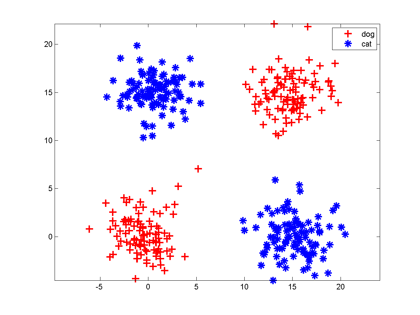
解决办法是多层神经网络,底层神经元的输出是高层神经元的输入。我们可以在中间横着砍一刀,竖着砍一刀,然后把左上和右下的部分合在一起,与右上的左下部分分开;也可以围着左上角的边沿砍10刀把这一部分先挖出来,然后和右下角合并。
每砍一刀,其实就是使用了一个神经元,把不同砍下的半平面做交、并等运算,就是把这些神经元的输出当作输入,后面再连接一个神经元。这个例子中特征的形状称为异或,这种情况一个神经元搞不定,但是两层神经元就能正确对其进行分类。
只要你能砍足够多刀,把结果拼在一起,什么奇怪形状的边界神经网络都能够表示,所以说神经网络在理论上可以表示很复杂的函数/空间分布。但是真实的神经网络是否能摆动到正确的位置还要看网络初始值设置、样本容量和分布。
神经网络神奇的地方在于它的每一个组件非常简单——把空间切一刀+某种激活函数(0-1阶跃、sigmoid、max-pooling),但是可以一层一层级联。输入向量连到许多神经元上,这些神经元的输出又连到一堆神经元上,这一过程可以重复很多次。这和人脑中的神经元很相似:每一个神经元都有一些神经元作为其输入,又是另一些神经元的输入,数值向量就像是电信号,在不同神经元之间传导,每一个神经元只有满足了某种条件才会发射信号到下一层神经元。当然,人脑比神经网络模型复杂很多:人工神经网络一般不存在环状结构;人脑神经元的电信号不仅有强弱,还有时间缓急之分,就像莫尔斯电码,在人工神经网络里没有这种复杂的信号模式。
神经网络的训练依靠反向传播算法:最开始输入层输入特征向量,网络层层计算获得输出,输出层发现输出和正确的类号不一样,这时它就让最后一层神经元进行参数调整,最后一层神经元不仅自己调整参数,还会勒令连接它的倒数第二层神经元调整,层层往回退着调整。经过调整的网络会在样本上继续测试,如果输出还是老分错,继续来一轮回退调整,直到网络输出满意为止。这很像中国的文艺体制,武媚娘传奇剧组就是网络中的一个神经元,最近刚刚调整了参数。
3. 大型神经网络
我们不禁要想了,假如我们的这个网络有10层神经元,第8层第2015个神经元,它有什么含义呢?我们知道它把第七层的一大堆神经元的输出作为输入,第七层的神经元又是以第六层的一大堆神经元做为输入,那么这个特殊第八层的神经元,它会不会代表了某种抽象的概念?
就好比你的大脑里有一大堆负责处理声音、视觉、触觉信号的神经元,它们对于不同的信息会发出不同的信号,那么会不会有这么一个神经元(或者神经元小集团),它收集这些信号,分析其是否符合某个抽象的概念,和其他负责更具体和更抽象概念的神经元进行交互。
2012年多伦多大学的Krizhevsky等人构造了一个超大型卷积神经网络[1],有9层,共65万个神经元,6千万个参数。网络的输入是图片,输出是1000个类,比如小虫、美洲豹、救生船等等。这个模型的训练需要海量图片,它的分类准确率也完爆先前所有分类器。纽约大学的Zeiler和Fergusi[2]把这个网络中某些神经元挑出来,把在其上响应特别大的那些输入图像放在一起,看它们有什么共同点。他们发现中间层的神经元响应了某些十分抽象的特征。
第一层神经元主要负责识别颜色和简单纹理

第二层的一些神经元可以识别更加细化的纹理,比如布纹、刻度、叶纹。

第三层的一些神经元负责感受黑夜里的黄色烛光、鸡蛋黄、高光。

第四层的一些神经元负责识别萌狗的脸、七星瓢虫和一堆圆形物体的存在。

第五层的一些神经元可以识别出花、圆形屋顶、键盘、鸟、黑眼圈动物。

这里面的概念并不是整个网络的输出,是网络中间层神经元的偏好,它们为后面的神经元服务。虽然每一个神经元都傻不拉几的(只会切一刀),但是65万个神经元能学到的东西还真是深邃呢。
[1] Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2012). Imagenet classification with deep convolutional neural networks. In Advances in neural information processing systems(pp. 1097-1105).
[2] Zeiler, M. D., & Fergus, R. (2013). Visualizing and understanding convolutional neural networks. arXiv preprint arXiv:1311.2901.
9分钟深度学习视频教学
视频代码教学
视频里演示的代码,已经编写成免费上机操作教程,可一步步跟着指示进行学习。
YJango:超智能体S01:高考与机器学习zhuanlan.zhihu.com YJango:超智能体M01:7分钟入门线性代数+微积分zhuanlan.zhihu.com
YJango:超智能体M01:7分钟入门线性代数+微积分zhuanlan.zhihu.com
一、基本变换:层
神经网络是由一层一层构建的,那么每层究竟在做什么?
- 数学式子:
,其中
是输入向量,
是输出向量,
是偏移向量,
是权重矩阵,
是激活函数。每一层仅仅是把输入
经过如此简单的操作得到
。
- 数学理解:通过如下5种对输入空间(输入向量的集合)的操作,完成 输入空间 ——> 输出空间 的变换 (矩阵的行空间到列空间)。
注:用“空间”二字的原因是被分类的并不是单个事物,而是一类事物。空间是指这类事物所有个体的集合。- 1. 升维/降维
- 2. 放大/缩小
- 3. 旋转
- 4. 平移
- 5. “弯曲”
这5种操作中,1,2,3的操作由完成,4的操作是由
完成,5的操作则是由
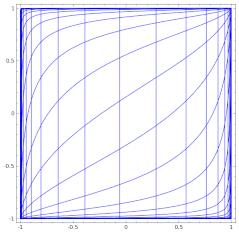
每层神经网络的数学理解: 用线性变换跟随着非线性变化,将输入空间投向另一个空间。
- 物理理解:对
又符合了我们所处的世界都是非线性的特点。
- 情景:
,数值且定为
,若确定
- 情景:
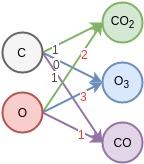
- 1.如果权重W的数值如(1),那么网络的输出y⃗ 就会是三个新物质,[二氧化碳,臭氧,一氧化碳]。
(1)
- 2.也可以减少右侧的一个节点,并改变权重W至(2),那么输出
。
(2)
- 3.如果希望通过层网络能够从[C, O]空间转变到
空间的话,那么网络的学习过程就是将W的数值变成尽可能接近(1)的过程 。如果再加一层,就是通过组合
每层神经网络的物理理解: 通过现有的不同物质的组合形成新物质。
二、理解视角:
现在我们知道了每一层的行为,但这种行为又是如何完成识别任务的呢?
数学视角:“线性可分”
- 一维情景:以分类为例,当要分类正数、负数、零,三类的时候,一维空间的直线可以找到两个超平面(比当前空间低一维的子空间。当前空间是直线的话,超平面就是点)分割这三类。但面对像分类奇数和偶数无法找到可以区分它们的点的时候,我们借助 x % 2(取余)的转变,把x变换到另一个空间下来比较,从而分割。

- 二维情景:平面的四个象限也是线性可分。但下图的红蓝两条线就无法找到一超平面去分割。
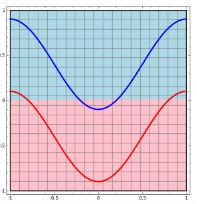
神经网络的解决方法依旧是转换到另外一个空间下,用的是所说的5种空间变换操作。比如下图就是经过放大、平移、旋转、扭曲原二维空间后,在三维空间下就可以成功找到一个超平面分割红蓝两线 (同SVM的思路一样)。
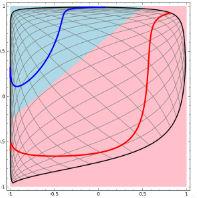
上面是一层神经网络可以做到的,如果把 当做新的输入再次用这5种操作进行第二遍空间变换的话,网络也就变为了二层。最终输出是
。
设想网络拥有很多层时,对原始输入空间的“扭曲力”会大幅增加,如下图,最终我们可以轻松找到一个超平面分割空间。
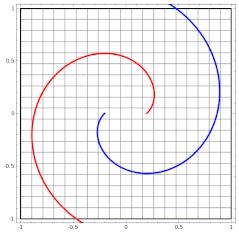
当然也有如下图失败的时候,关键在于“如何扭曲空间”。所谓监督学习就是给予神经网络网络大量的训练例子,让网络从训练例子中学会如何变换空间。每一层的权重W就控制着如何变换空间,我们最终需要的也就是训练好的神经网络的所有层的权重矩阵。

这里有非常棒的可视化空间变换demo,一定要打开尝试并感受这种扭曲过程。更多内容请看Neural Networks, Manifolds, and Topology。
线性可分视角:神经网络的学习就是 学习如何利用矩阵的线性变换加激活函数的非线性变换,将原始输入空间投向线性可分/稀疏的空间去分类/回归。 增加节点数:增加维度,即增加线性转换能力。 增加层数:增加激活函数的次数,即增加非线性转换次数。
物理视角:“物质组成”
- 类比:回想上文由碳氧原子通过不同组合形成若干分子的例子。从分子层面继续迭代这种组合思想,可以形成DNA,细胞,组织,器官,最终可以形成一个完整的人。继续迭代还会有家庭,公司,国家等。这种现象在身边随处可见。并且原子的内部结构与太阳系又惊人的相似。不同层级之间都是以类似的几种规则再不断形成新物质。你也可能听过分形学这三个字。可通过观看从1米到150亿光年来感受自然界这种层级现象的普遍性。
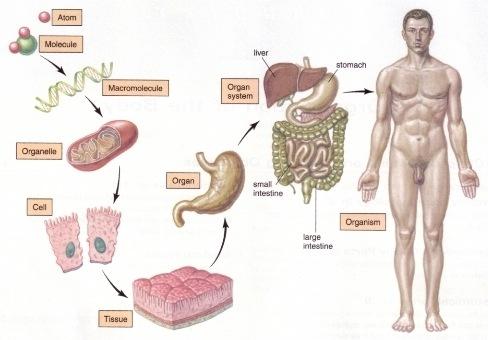
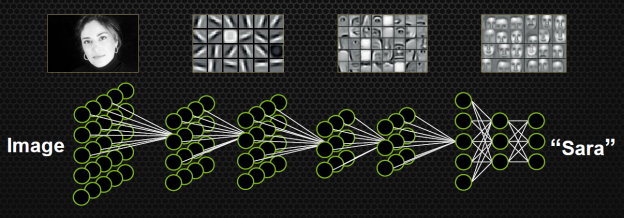
- 人脸识别情景:我们可以模拟这种思想并应用在画面识别上。由像素组成菱角再组成五官最后到不同的人脸。每一层代表不同的不同的物质层面 (如分子层)。而每层的W存储着如何组合上一层的物质从而形成新物质。
如果我们完全掌握一架飞机是如何从分子开始一层一层形成的,拿到一堆分子后,我们就可以判断他们是否可以以此形成方式,形成一架飞机。
附:Tensorflow playground展示了数据是如何“流动”的。
物质组成视角:神经网络的学习过程就是 学习物质组成方式的过程。 增加节点数:增加同一层物质的种类,比如118个元素的原子层就有118个节点。 增加层数:增加更多层级,比如分子层,原子层,器官层,并通过判断更抽象的概念来识别物体。
三、神经网络的训练
知道了神经网络的学习过程就是学习控制着空间变换方式(物质组成方式)的权重矩阵后,接下来的问题就是如何学习每一层的权重矩阵W。
如何训练:
既然我们希望网络的输出尽可能的接近真正想要预测的值。那么就可以通过比较当前网络的预测值和我们真正想要的目标值,再根据两者的差异情况来更新每一层的权重矩阵(比如,如果网络的预测值高了,就调整权重让它预测低一些,不断调整,直到能够预测出目标值)。因此就需要先定义“如何比较预测值和目标值的差异”,这便是损失函数或目标函数(loss function or objective function),用于衡量预测值和目标值的差异的方程。loss function的输出值(loss)越高表示差异性越大。那神经网络的训练就变成了尽可能的缩小loss的过程。
所用的方法是梯度下降(Gradient descent):通过使loss值向当前点对应梯度的反方向不断移动,来降低loss。一次移动多少是由学习速率(learning rate)来控制的。
梯度下降的问题:
然而使用梯度下降训练神经网络拥有两个主要难题。
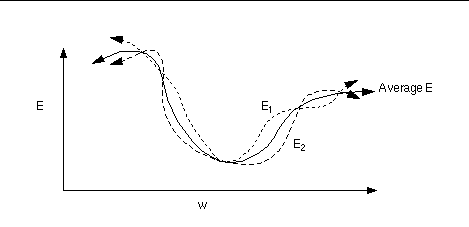
1、局部极小值
梯度下降寻找的是loss function的局部极小值,而我们想要全局最小值。如下图所示,我们希望loss值可以降低到右侧深蓝色的最低点,但loss有可能“卡”在左侧的局部极小值中。
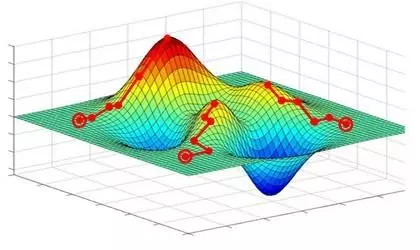
试图解决“卡在局部极小值”问题的方法分两大类:
- 调节步伐:调节学习速率,使每一次的更新“步伐”不同。常用方法有:
- 随机梯度下降(Stochastic Gradient Descent (SGD):每次只更新一个样本所计算的梯度
- 小批量梯度下降(Mini-batch gradient descent):每次更新若干样本所计算的梯度的平均值
- 动量(Momentum):不仅仅考虑当前样本所计算的梯度;Nesterov动量(Nesterov Momentum):Momentum的改进
- Adagrad、RMSProp、Adadelta、Adam:这些方法都是训练过程中依照规则降低学习速率,部分也综合动量
- 优化起点:合理初始化权重(weights initialization)、预训练网络(pre-train),使网络获得一个较好的“起始点”,如最右侧的起始点就比最左侧的起始点要好。常用方法有:高斯分布初始权重(Gaussian distribution)、均匀分布初始权重(Uniform distribution)、Glorot 初始权重、He初始权、稀疏矩阵初始权重(sparse matrix)
2、梯度的计算
机器学习所处理的数据都是高维数据,该如何快速计算梯度、而不是以年来计算。
其次如何更新隐藏层的权重?
解决方法是:计算图:反向传播算法
这里的解释留给非常棒的Computational Graphs: Backpropagation
需要知道的是,反向传播算法是求梯度的一种方法。如同快速傅里叶变换(FFT)的贡献。
而计算图的概念又使梯度的计算更加合理方便。
基本流程图:
下面就结合图简单浏览一下训练和识别过程,并描述各个部分的作用。要结合图解阅读以下内容。但手机显示的图过小,最好用电脑打开。
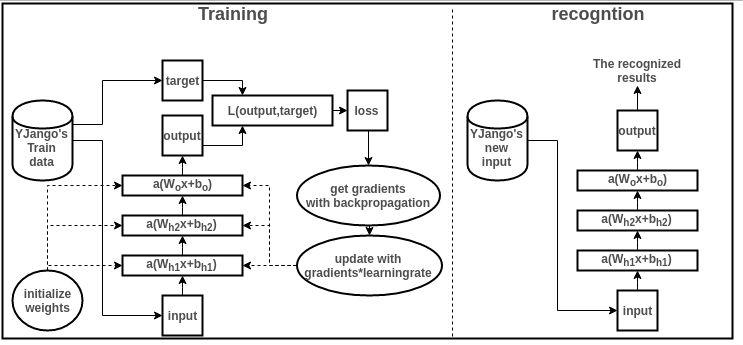
- 收集训练集(train data):也就是同时有input以及对应label的数据。每个数据叫做训练样本(sample)。label也叫target,也是机器学习中最贵的部分。上图表示的是我的数据库。假设input本别是x的维度是39,label的维度是48。
- 设计网络结构(architecture):确定层数、每一隐藏层的节点数和激活函数,以及输出层的激活函数和损失函数。上图用的是两层隐藏层(最后一层是输出层)。隐藏层所用激活函数a( )是ReLu,输出层的激活函数是线性linear(也可看成是没有激活函数)。隐藏层都是1000节点。损失函数L( )是用于比较距离MSE:mean((output - target)^2)。MSE越小表示预测效果越好。训练过程就是不断减小MSE的过程。到此所有数据的维度都已确定:
- 训练数据:
- 权重矩阵:
- 偏移向量:
- 网络输出:
- 训练数据:
- 数据预处理(preprocessing):将所有样本的input和label处理成能够使用神经网络的数据,label的值域符合激活函数的值域。并简单优化数据以便让训练易于收敛。比如中心化(mean subtraction)、归一化(normlization)、主成分分析(PCA)、白化(whitening)。假设上图的input和output全都经过了中心化和归一化。
- 权重初始化(weights initialization):
在训练前不能为空,要初始化才能够计算loss从而来降低。
- 训练网络(training):训练过程就是用训练数据的input经过网络计算出output,再和label计算出loss,再计算出gradients来更新weights的过程。
- 正向传递:,算当前网络的预测值
- 计算loss:
- 计算梯度:从loss开始反向传播计算每个参数(parameters)对应的梯度(gradients)。这里用Stochastic Gradient Descent (SGD) 来计算梯度,即每次更新所计算的梯度都是从一个样本计算出来的。传统的方法Gradient Descent是正向传递所有样本来计算梯度。SGD的方法来计算梯度的话,loss function的形状如下图所示会有变化,这样在更新中就有可能“跳出”局部最小值。
- 正向传递:,算当前网络的预测值
-
- 更新权重:这里用最简单的方法来更新,即所有参数都
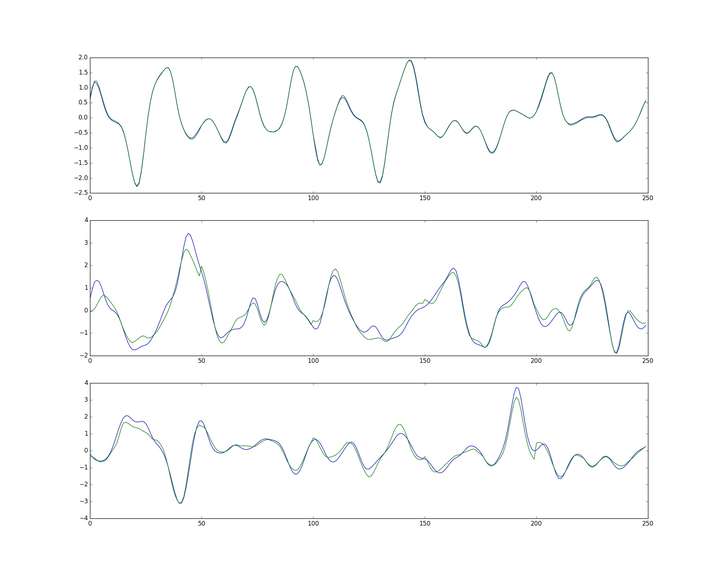
- 预测新值:训练过所有样本后,打乱样本顺序再次训练若干次。训练完毕后,当再来新的数据input,就可以利用训练的网络来预测了。这时的output就是效果很好的预测值了。下图是一张实际值和预测值的三组对比图。输出数据是48维,这里只取1个维度来画图。蓝色的是实际值,绿色的是实际值。最上方的是训练数据的对比图,而下方的两行是神经网络模型从未见过的数据预测对比图。(不过这里用的是RNN,主要是为了让大家感受一下效果)
- 更新权重:这里用最简单的方法来更新,即所有参数都














 6761
6761











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}