







|
黄鹏,Sun中国工程研究院 2005年11月14日,Sun公司在美国旧金山宣布,最终产品名称确定为UltraSPARC T1的“Niagara”处理器芯片正式问世,这也是全球第一款商用CMT处理器芯片,标志着处理器发展发展历史上新纪元的到来。 “Niagara”这个代号取自位于美加边界的尼亚加拉大瀑布,意为“急流、洪水”,Sun公司用Niagara这一名称来形象的展现这一处理器在吞吐量方面的超前优势。本文将通过一系列文章向大家介绍: 第一篇:什么是CMT技术 在本系列的第一篇中,我们将来探讨CMT诞生的背景,CMT技术的实质及其优势。 1.传统微处理器的发展瓶颈 1.1 传统通用微处理器体系结构的局限性 当前,传统的微处理器主要有如下三方面的发展局限性:
不可否认,ILP技术以及主频的提升在一定程度上、一定时间内提高了计算机对于单一线程执行速度。然而,相对于CPU主频、复杂程度的提升,计算机的整体性能并没有取得相匹配的增长。这其中的主要原因就在于:从计算机体系结构的角度来看,传统的技术并不能有效、充分的利用计算机的整体硬件能力。 1.2 计算机应用的演变 时至今日,以商用事务处理和Web服务为代表的应用日益成为服务器应用的主流。回顾计算机的近30年发展历史,我们不难发现,计算机应用已经从传统的以SPEC CPU2000为代表的计算密集型的科学技术应用,发展到了现今的以SPEC JBB2000为代表的数据密集型应用,表现出完全不同的执行和数据访问的特征。 传统的计算密集型应用,对于数据的运算操作远远多于数据的装入操作,因而具备很高的代码和数据访问的局部性,能够有效的利用预取操作数、Cache等技术来弥补内存带宽的不足以及内存访问未命中所造成的时间延迟。
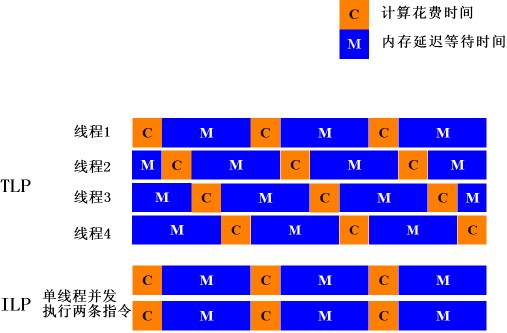
因此,和计算机应用的演变相适应,高端计算机的核心评价指标正在发生根本性的变化,从高性能计算(High-Performance Computing)转向高效能计算(High-Productive Computing),从强调单任务的性能到更多的强调多任务处理的吞吐量(Throughput)。正是基于这一认识,早在2003年,Sun公司在发布其今后处理器产品蓝图时,就已经将系统吞吐量计算(Throughput-computing)作为今后研发的重点。 所以,构建高主频、复杂的ILP处理器,并不能够解决传统的处理器体系结构中固有的问题。为了提高系统整体的性能,就势必要求突破传统的思路,开发ILP之外的更粗粒度的并行性。 2.TLP的提出 在这种情况下,线程级并行(Thread Level Parallelism, TLP)技术应运而生。TLP技术将处理器内部的并行由指令级上升到线程级,旨在通过线程级的并行来增加指令吞吐量,提高处理器的资源利用率。TLP处理器的中心思想是:当某一个线程由于等待内存访问结构而空闲时,可以立刻导入其他的就绪线程来运行。这样,处理器流水线就能够始终处于忙碌的状态,系统的处理能力提高了,吞吐量自然也相应提升了。我们可以从下面示意图的比较看出TLP相对于ILP的优势。 在图2示意的TLP处理器的理想状态中,由于内存访问而导致的延迟可以经由导入其他线程的执行而抵消。相对而言,ILP只能够缩短指令在CPU中的执行时间,却不能有效改善由于内存等待而造成的延迟。(注:使用乱序执行(out-of-order)的ILP处理器能够小幅度利用内存等待的延迟来执行指令)。当前处理器的运行速度普遍都在GHz的水平,性能瓶颈转移到内存和I/O的延迟,较之于ILP,在解决I/O和内存访问延迟方面,TLP具备显著的优势。 TLP不仅仅是单纯从技术角度提出的学术观点,而且也符合了服务器应用的特征。现今的网络计算环境从本质上来说就是多线程的,这就决定了相对于整体的吞吐量而言,单个线程的执行速度并不那么重要了。这也可以解释:对于服务器端的企业级商务应用,传统的ILP方式的高主频系统并不能够有效的提升系统的效能。下表给出了一些实际服务器应用的具体情况。从表中可以看出,许多典型的服务器端应用需要处理大量的并发线程的能力,而并不是提高单线程的执行速度。换言之,对于服务器的并发工作环境,TLP才是提升性能的王道。
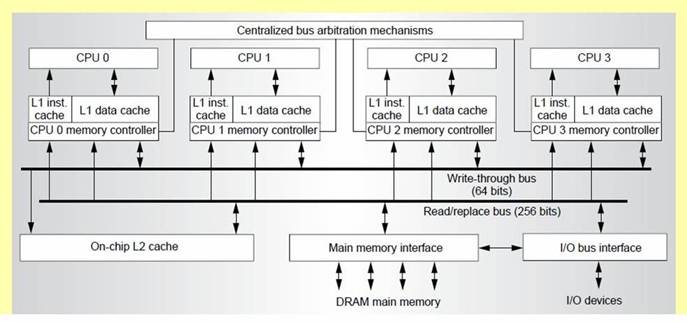
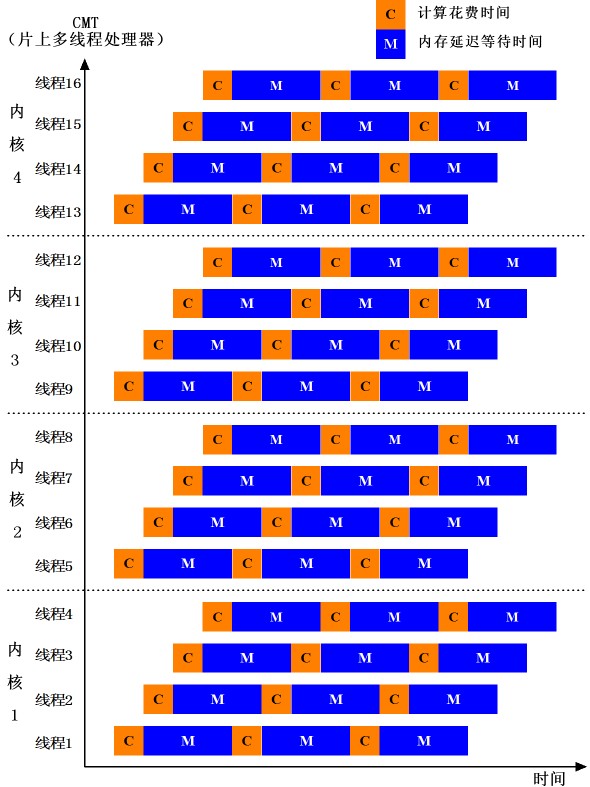
表1:常见的服务器端企业级应用中的指令级并行度和线程级并行度的比较 现在,业界普遍认为,TLP将是下一代高性能处理器的主流体系结构技术,ILP将仅仅成为TLP中表示性能的辅助参数。 3.SMP技术 SMP的全称是“对称多处理”(Symmetrical Multi-Processing)技术,可以看作是一种从宏观角度支持TLP的体系结构技术。SMP是指在一个计算机上汇集了多个CPU,各CPU之间共享内存子系统以及总线结构。它是相对非对称多处理技术而言的、应用十分广泛的并行技术。在这种架构中,一台电脑不再由单个CPU组成,而同时由多个处理器运行操作系统的单一复本,并共享内存和一台计算机的其他资源。虽然同时使用多个CPU,但是从管理的角度来看,它们的表现就像一台单机一样。系统将任务队列地分布于多个CPU之上,从而极大地提高了整个系统的数据处理能力。所有的处理器都可以平等地访问内存、I/O和外部中断。在对称多处理系统中,系统资源被系统中所有CPU共享,工作负载能够均匀地分配到所有可用处理器之上。SMP技术是高性能服务器和工作站级主板架构中提升性能的有效手段,像某些UNIX服务器可支持高达256个CPU的SMP系统。 然而,传统的SMP系统内部的多个处理器通过片外总线互连,共享总线带宽,传统总线所固有的低带宽、高延迟已经成为SMP系统的性能瓶颈。在SMP方面的一种发展趋势就是将SMP系统搬到一块芯片内部,利用片内的高带宽总线来代替片外总线,实现片内高带宽的SMP超级计算机。 4.CMT=CMP+MT 4.1 CMP-单芯片多处理器=片内SMP TLP的研究已经开展许多年了,学术界提出了多种实现方式,其中又以Stanford大学的单芯片多处理器(CMP, Chip Multi-Processor)的Hydra CMP为典型代表。CMP的基本思想是在单个芯片上实现SMP,每一个处理器核心实质上都是一个相对简单的单线程处理器。CMP允许线程在多个处理器内核上并行执行,从而利用线程级并行性来提高系统性能。下图是Hydra CMP的体系结构。可以看出CMP主要是依赖SMP体系结构来实现TLP的。 4.2 MT-多线程处理器(Multi-threading Processor) 为了理解CMT,我们还有必要看一下多线程处理器(Hardware Multithreading)。顾名思义,多线程处理器是在一个处理器内核中提供支持多个“硬”线程(Hardware Thread)的能力,通常由处理器内核为每个线程维护独立的处理器状态,包括寄存器与程序计数器PC等,并能够快速地切换线程上下文。由于多线程处理器在遇到延迟事件时,可以将线程迅速切换去执行另外一部分程序代码,从而有效避免了将时间浪费在延迟等待上。下图中给出了一个支持硬件多线程技术的CPU在四个硬线程之间切换的情况,可以看出,在这种方式下,处理器的流水线始终保持在满负荷的工作状态,即便是某些线程由于内存访问被阻塞。 我们小结一下,多线程处理器MT赋予CPU在多个线程中转换处理的能力,是一个超标量处理器内核。一个CMP是由若干个单线程处理器以SMP(对称多处理器系统)方式构成的支持TLP的系统,如果我们用MT处理器去置换CMP中的一个个的单线程处理器内核,使用多线程处理器来构造SMP方式的TLP系统,岂不是锦上添花?没错,这种将CMP和MT相结合的创新就是CMT技术。 4.3 片上多线程Chip Multi-threading (CMT) 简言之,CMT就是在一块芯片上集成多个MT处理器内核所构造的支持TLP的SMP系统。和极为复杂的传统单线程处理器不同,CMT技术采用相对简单的多线程处理器核心。每个处理器核心都维护多个线程,线程一直保持运行状态直到被阻塞,这时流水线将立即切换到另外一个就绪的线程。CMT处理器的一个天生优势是:由于这些单个的处理器核心的流水线相对简单,它们的制备不那么复杂,因而能耗低,散热量小。下图示意了一个4核的CMT技术的CPU,支持并发16个线程。 由于CMT采用了可以采用相对简单的多线程微处理器作为处理器核心,使得CMT主要具有以下优点:
4.4 CMT:吞吐量运算和性能的有力保障 CMT技术,通过引入全新的体系结构来尽可能充分的利用系统的资源,提高系统的吞吐量。一方面,系统由多个实实在在的处理器内核构成,确保系统多发射的有效执行。另一方面,每一个内核内部又是多线程的,执行部件在各个硬线程之间迅速切换,又能够进一步提高系统的利用率,提高并发执行的指令数目,提升系统的吞吐量。可以说,这种全新的体系结构为提升应用程序的性能提供了有效的保证。我们来具体看一下CMT处理器体系结构的运行特征。 首先,相对于传统的单内核处理器,CMT处理器中提供了物理上而非逻辑上的多个处理器内核,提供了多套执行部件。这样的系统,无需借助复杂的硬件分析设备或者复杂的编译器,就能够真正并发处理多个指令,而不用考虑指令之间的相关性。 其次,相对于单线程的处理器而言,CMT处理器能够大幅度抵消内存访问延迟带来的副作用。当某一个线程由于内存访问而必须等待时,传统的单线程机器必须作一系列的空闲操作等待内存访问的结果,而CMT则可以迅速切换到另外一个就绪的线程,忽略前一个被阻塞的线程,这样,内存访问所造成的延迟就有可能最大程度上的被CMT的线程切换能力所屏蔽了。如果从CMT内部来看,则是每一个多线程处理器内部的流水线都能够经常性的保持满负荷的运作,不断的处理就绪的线程。所以,CMT处理器内部的处理效能就大大提高了,不用把能耗浪费在无用的空闲操作上。 另一方面,我们也必须牢记CMT的设计初衷:CMT是为了提高系统的吞吐能力,而不是为了提高单个线程的执行速度。正因为如此,单线程的程序在CMT上运行一个实例时的性能可能不如在传统的单线程处理器上运行的性能好。这主要是由两方面的原因造成的: 首先,单一的线程并不能独享处理器的所有资源,而必须和其他的硬线程来分享,为其他的硬线程让出一些时间片,所以整体的运行时间反而慢了。(注:对于良好设计的CMT处理器,可以通过软件指令动态关闭单个内核中的多个线程,使得各个内核以单线程方式来运行)。 其次,在绝大多数的CMT处理器中,每个处理器内核的流水线都相对简单,不如同时期的单线程处理器来得复杂和功能强大,这也是造成单线程应用在CMT上运行较慢的原因。 所以,必须牢记:CMT处理器实质上是一种TLP系统,利用并发运行多个线程所获得的吞吐量来换取性能的。为了充分利用CMT,就必须使得系统能够获得充足的线程级并发任务输入,确保系统能够“吃饱”,才能够让系统“跑得快”!例如:针对上面的单线程应用的特殊例子,我们可以同时在CMT系统上同时运行该应用的多个实例。这样,虽然单个实例不如在某些单线程处理器系统上跑的快,但是,就整体而言,系统的吞吐量却能够取得质的飞跃。具体的技术我们会在后面介绍。 第四点,由于在CMT的每个处理器内核中,多个硬线程会共享核内的某些部件,所以某一个线程的性能会受到其他运行线程的影响,这些影响可以是正面的,也可能是负面的。下面列举了一些典型的情况:
4.5 什么样的程序适合在CMT处理器上运行 CMT处理器适应于追求吞吐量的应用,特别是面向Web和商用事务处理的应用。那么是不是只有基于多线程技术的应用程序才能够利用CMT处理器的特征,提升性能呢?答案并不是这么简单。我们在下面列举了一系列适用于CMT处理器的应用类型。
从这里可以回答我们前面提出的问题:对于单线程的应用,通过运行应用的多个实例,同样可以让它们在CMT上飞速运作! 当然,CMT也并非是万能的,不是所有的应用程序都适合运行在CMT系统上。某些应用程序如果不能将负载很好的在CMT架构上很好的分布,就不能够利用CMT的特性。例如:
随着CMT技术日臻成熟,当前业界对于CMT应用的一个主要问题自然而然的落在软件方面:必须要有一个同CMT相配套的操作系统为用户提供使用CMT强大功能的良好接口;同时还要考虑到许多传统软件的存在,能否将传统软件无缝的移植到支持CMT技术的操作系统上;第三就是良好的开发环境,为用户提供方便的软件开发包,充分利用CMT的高线程并发能力。 在本系列的第一篇文章中,我们向大家介绍了CMT的提出背景,TLP技术,CMT技术的实质、性能优势以及所适用的场合。在第二篇中,我们将向大家展示采用CMT技术的第一款商用处理器,UltraSPARC T1的技术特色。 参考文献: 作者简介: | |||||||||||||||||||||||||||||||||||||||||||||||||
利用CMT技术,倍增服务器吞吐量——介绍Sun公司的UltraSPARC T1处理器 (引用)
2007-05-03 22:42

















 2788
2788

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









