







什么是循环神经网络RNN What is Recurrent Neural Networks(RNN)?
作者:徐志强
链接:https://zhuanlan.zhihu.com/p/22266022
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
循环神经网络(RNN)是非常流行的模型,在NLP的很多任务中已经展示出了很大的威力。但与此相对的是,能完整解释RNN是如何工作,如何实现的资源非常有限。这也是本教程所要做的事情,本教程打算覆盖下面几个方面的内容:
1. RNN简介(本篇)
2. 用python和theano实现一个RNN
3. 理解随时间反向传播算法(BPTT)和梯度消失问题
4. 实现一个GRU/LSTM RNN
作为本教程的一部分,将会实现一个基于RNN的语言模型(rnnlm)。语言模型有两个方面的应用:一,基于每个序列在现实世界中出现的可能性对其进行打分,这实际上提供了一个针对语法和语义正确性的度量,语言模型通常为作为机器翻译系统的一部分。二,语言模型可以用来生成新文本。根据莎士比亚的作品训练语言模型可以生成莎士比亚风格的文本。这篇博客(The Unreasonable Effectiveness of Recurrent Neural Networks)说明了基于RNN的字符级别的语言模型能做什么。
这里假设你已经熟悉一些基本的神经网络。否则的话,你可以先浏览一下这篇文章(Implementing A Neural Network From Scratch),它会带你了解非循环神经网络的一些思想和具体实现。
RNN是什么?
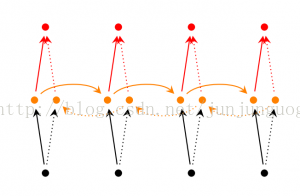
RNN背后的思想是利用顺序信息。在传统的神经网络中,我们假设所有的输入(包括输出)之间是相互独立的。对于很多任务来说,这是一个非常糟糕的假设。如果你想预测一个序列中的下一个词,你最好能知道哪些词在它前面。RNN之所以循环的,是因为它针对系列中的每一个元素都执行相同的操作,每一个操作都依赖于之前的计算结果。换一种方式思考,可以认为RNN记忆了到当前为止已经计算过的信息。理论上,RNN可以利用任意长的序列信息,但实际中只能回顾之前的几步。下面是RNN的一个典型结构图:

上面的图中展示了RNN被展开成一个全网络后的结构。这里展开的意思是把针对整个序列的网络结构表示出来。例如,如果这里我们关心的是一个包含5个词的句子,那这里网络将会被展开成一个5层的网络,每个词对应一层。在RNN中进行的计算公式如下:
 是
是 时刻的输入。例如,
时刻的输入。例如, 是句子中第二个词的one hot编码向量。
是句子中第二个词的one hot编码向量。
 是对应时刻的隐藏状态,是网络的记忆单元。通过前一步的隐藏状态和当前时刻的输入得到:
是对应时刻的隐藏状态,是网络的记忆单元。通过前一步的隐藏状态和当前时刻的输入得到: 。函数
。函数 通常是非线性的,例如tanh和ReLU。
通常是非线性的,例如tanh和ReLU。 通常用来计算第一个隐藏状态,会被全0初始化。
通常用来计算第一个隐藏状态,会被全0初始化。
 是时刻的输出。例如,如果想要预测句子中的下一个词,那么它就会是包含词表中所有词的一个概率向量,
是时刻的输出。例如,如果想要预测句子中的下一个词,那么它就会是包含词表中所有词的一个概率向量, 。
。
这里有一些需要注意的地方:
- 你可以认为隐藏状态
 是网络的记忆单元。可以捕捉到之前所有时刻产生的信息。输出仅仅依赖于时刻的记忆。就像之前提到的那样,在实际中是比较复杂的,因为通常难以捕捉许多时刻之前的信息。
是网络的记忆单元。可以捕捉到之前所有时刻产生的信息。输出仅仅依赖于时刻的记忆。就像之前提到的那样,在实际中是比较复杂的,因为通常难以捕捉许多时刻之前的信息。
- 与传统深度神经网络中每一层使用不同的参数的做法不同,RNN在所有时刻中共享相同的参数
 。这反应了在每一步中都在执行相同的任务,只是用了不同的输入。这极大地减少了需要学习的参数的个数。
。这反应了在每一步中都在执行相同的任务,只是用了不同的输入。这极大地减少了需要学习的参数的个数。 - 上面的图中每一时刻都有输出,在具体的任务中,这可能是不必要的。例如,在预测一句话的情感时,我们关心的可能只是最终的输出,并不是每一个词之后的情感。相似地,可能并不是每一时刻都需要输入。RNN的主要特征是它的隐藏状态,可以捕捉一句话中的信息。
RNN能做什么?
RNN在NLP的很多任务中都取得了很大的成功。这里我要提下最常用的RNN类型是LSTM,相比于普通的RNN,它更擅长于捕捉长期依赖。但是不要担心,LSTM和我们这个教程里要介绍的RNN本质上是相同的,只是使用了一种不同的方式来计算隐藏状态。在后面的文章中,将会更详细的介绍LSTM。下面是RNN在NLP中的一些应用例子。
语言模型和文本生成
给定一个词的序列,我们想预测在前面的词确定之后,每个词出现的概率。语言模型可以度量一个句子出现的可能性,这可以作为机器翻译的一个重要输入(因为出现概率高的句子通常是正确的)。能预测下一个词所带来的额外效果是我们得到了一个生成模型,这可以让我们通过对输出概率采样来生成新的文本。根据训练数据的具体内容,我们可以生成任意东西。在语言模型中,输入通常是词的序列(编码成one hot向量),输出是预测得到的词的序列。在训练网络是,设置 ,因为我们想要的时刻的输出是下一个词。
,因为我们想要的时刻的输出是下一个词。
关于语言模型和文本生成的研究论文:
- Recurrent neural network based language model
- Extensions of Recurrent neural network based language model
- Generating Text with Recurrent Neural Networks
机器翻译
机器翻译与语言模型相似,输入是源语言中的一个词的序列(例如,德语),输出是目标语言(例如,英语)的一个词的序列。一个关键不同点在于在接收到了完整的输入后才会开始输出,因为我们要翻译得到的句子的第一个词可能需要前面整个输入序列的信息。

关于机器翻译的研究论文:
- A Recursive Recurrent Neural Network for Statistical Machine Translation
- Sequence to Sequence Learning with Neural Networks
- Joint Language and Translation Modeling with Recurrent Neural Networks
语音识别
给定一段从声波中产生的输入声学信号序列,我们想要预测一个语音片段序列及其概率。
关于语音识别的研究论文:
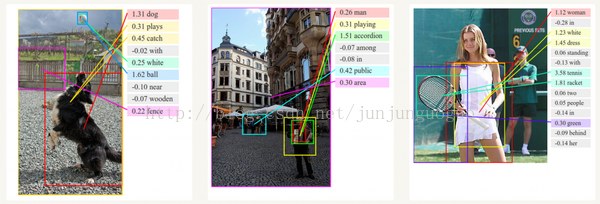
图像描述生成
和卷及神经网络一起,RNN可以作为生成无标注图像描述模型的一部分。对于这个如何工作的看起来非常令人惊讶。这个联合模型甚至可以对齐生成的词和图像中的特征。
RNN训练
训练RNN和训练传统神经网络相似,同样要使用反向传播算法,但会有一些变化。因为参数在网络的所有时刻是共享的,每一次的梯度输出不仅依赖于当前时刻的计算结果,也依赖于之前所有时刻的计算结果。例如,为了计算 时刻的梯度,需要反向传播3步,并把前面的所有梯度加和。这被称作随时间的反向传播(BPTT)。如果你现在没有理解,不要担心,后面会有关于更多细节的文章。现在,只要知道普通的用BPTT训练的RNN对于学习长期依赖(相距很长时间的依赖)是很困难的,因为这里存在梯度消失或爆炸问题。当然也存在一些机制来解决这些问题,特定类型的RNN(如LSTM)就是专门设计来解决这些问题的。
时刻的梯度,需要反向传播3步,并把前面的所有梯度加和。这被称作随时间的反向传播(BPTT)。如果你现在没有理解,不要担心,后面会有关于更多细节的文章。现在,只要知道普通的用BPTT训练的RNN对于学习长期依赖(相距很长时间的依赖)是很困难的,因为这里存在梯度消失或爆炸问题。当然也存在一些机制来解决这些问题,特定类型的RNN(如LSTM)就是专门设计来解决这些问题的。
RNN扩展
这些年来,研究者们已经提出了更加复杂的RNN类型来克服普通RNN模型的缺点,在后面的博客中会更详细的介绍它们,这一节只是一个简单的概述让你能够熟悉模型的类别。
Bidirectional RNN的思想是时刻的输出不仅依赖于序列中之前的元素,也依赖于之后的元素。例如,要预测一句话中缺失的词,你可能需要左右上下文。Bidirecrtional RNN很直观,只是两个RNN相互堆叠在一起,输出是由两个RNN的隐藏状态计算得到的。
Deep (Bidirectional)RNN和Bidirectional RNN相似,只是在每个时刻会有多个隐藏层。在实际中会有更强的学习能力,但也需要更多的训练数据。
LSTM network最近非常流行,上面也简单讨论过。LSTM与RNN在结构上并没有本质的不同,只是使用了不同的函数来计算隐藏状态。LSTM中的记忆单元被称为细胞,你可以把它当作是黑盒,它把前一刻的状态 和当前输入
和当前输入 。内部这些细胞能确定什么被保存在记忆中,什么被从记忆中删除。这些细胞把之前的状态,当前的记忆和输入结合了起来,事实证明这些类型的单元对捕捉长期依赖十分有效。LSTM在刚开始时会让人觉得困惑,如果你想了解更多,这篇博客(Understanding LSTM Networks)有很好的解释。
。内部这些细胞能确定什么被保存在记忆中,什么被从记忆中删除。这些细胞把之前的状态,当前的记忆和输入结合了起来,事实证明这些类型的单元对捕捉长期依赖十分有效。LSTM在刚开始时会让人觉得困惑,如果你想了解更多,这篇博客(Understanding LSTM Networks)有很好的解释。

总结
到目前为止一切都很好,希望你已经对RNN是什么以及能做什么有了基本的了解,在接下来的文章中,我会使用python和theano实现RNN语言模型的第一个版本。
PS:本文是针对Recurrent Neural Networks Tutorial, Part 1这篇文章的中文翻译,主要是为了加深自己的理解,后面还会对后续的文章进行翻译,如果有什么翻译的不好的地方,请参见原文。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









