







声明: 文章所引用的数据禁止用于商业用途
业务需求描述:
某部门今年的核心指标是司机留存率, 司机留存是指司机有完单 。 所以为了提高司机留存,需要预测出下周哪些司机完单量是0 , 从而城市的同学及时干预,促进司机完单, 提高司机留存率。
所以本需求简述为:
给你91万司机, 滴滴数据库的数据随便取,但是必须是第N周的数据, 请预测第N+1周,哪些司机没有完单量。
下面是本次建模的基本流程
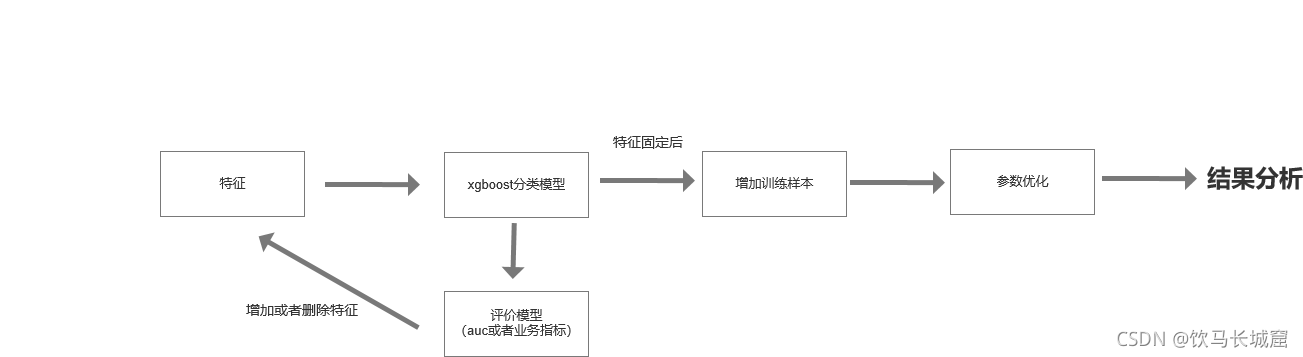
第一步:确定特征
如何司机下周不干了, 他这周有什么行动表现吗, 或者这周发生了什么事情, 会造成司机下周不想干了。 弄清楚这一步,是预测模型搭建的第一步,结合之前运营同学做的调研问卷,如下
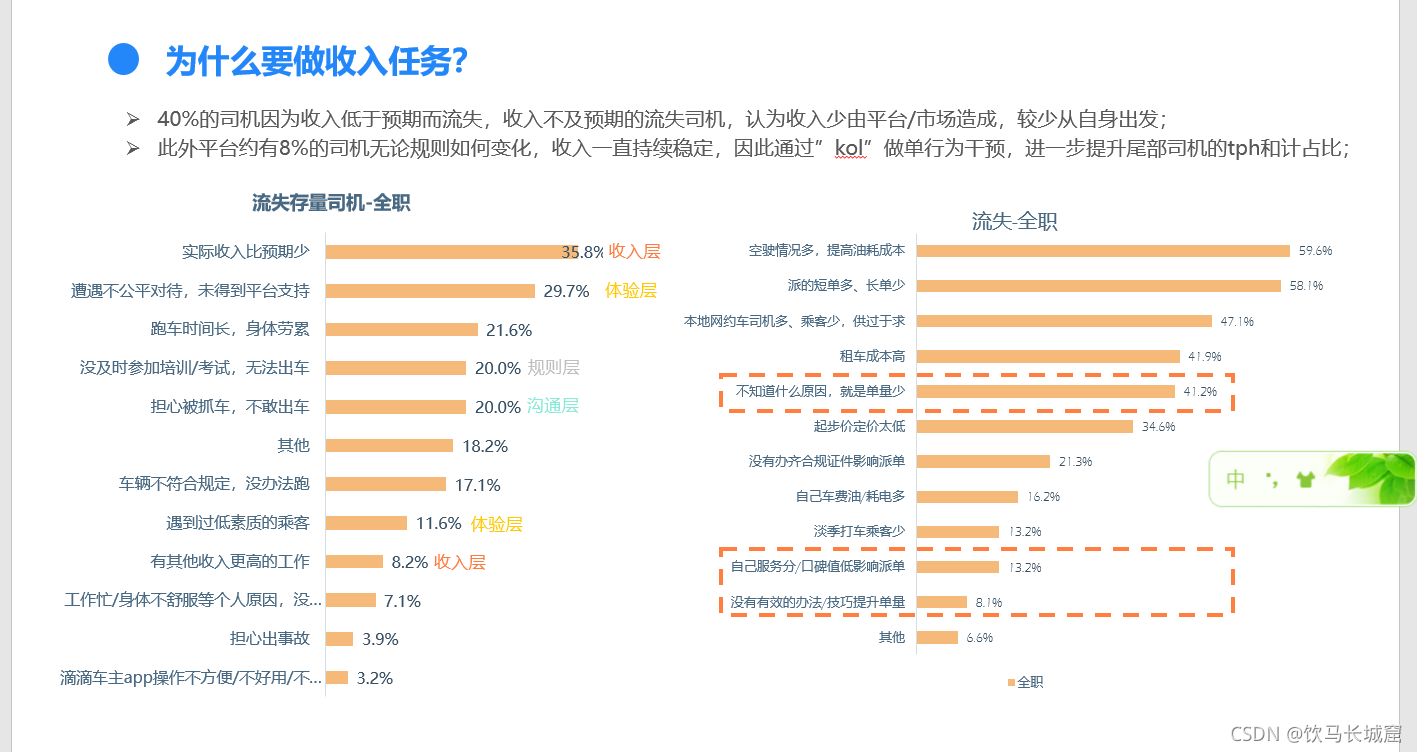
通过以上线下调研数据的分析,和作者多年的工作经验,最终锁定以下字段当做第一批训练模型的指标:
[ '年龄', '合作时长', '司机双证合规状态','司机合作类型', '常驻城市', '全兼职类型',
'车辆级别', '在线时长', '剔除只听预约单的在线时长','应答预约单数', '连续30分钟听不到单次数', '应答数','等待时长', '司机取消订单数', '单均距离', '完单量', 'gmv','单均价格', 'B补贴']
这只是第一步,后续在优化模型的时候,我们可以更换标签,或者对标签进行处理,达到更好的区分效果。
第二步: xgboost分类预测模型
将上面的特征写到pandas的dataframe里面, 然后开始xgboost训练。
代码参见:
名称:sss 链接:Cooper
密码:点赞后索取
模型的auc是0.93说明模型可靠,接下来看业务衡量指标,业务上更看重预测出多少流失司机, 所以我们用下面两个指标
①覆盖度: 如果下周100个司机流失, 我们预测出70个,覆盖度就是70%
②准确度: 如果我们给的140个司机,实际上只有70个是流失的, 另外70个没流失,准确度就是50%
第一批特征输进去之后,覆盖度是67%,准确度70% ,所以我们想了使用什么字段可以更好的优化,一个字段一个字段的尝试,
第三步参数优化:
①删除特征: xgboost对会自动给特征权重,所以这种方法效果不好
②参数优化: 样本量比较大的时候有用, 样本量较小的时候用处不大,本次参数优化的结果是:
model = XGBClassifier( max_depth=9,subsample=0.5) 的时候效果最好
③样本的周期性,司机流失本月预测下月的效果没有本周预测下周效果好, 说明司机流失是一个短周期的行为,过长的时间周期,掩盖了有效的特征
④特征降维处理,最后结果收入类的F值接近,感兴趣的可以做一下PCA处理特征,或许效果更好,这里我没做。
⑤最有效的方式还是代入实际上影响司机流失的特征,就是客观世界A因素会造成司机流失, 那么找到A因素,才会对模型的效果提升较大。
第四步结果分析
最后得到的效果如图:

可以看到我们通过本周的数据,能预测出下周74%的流失司机。
另外我们也输出了各个特征对分类结果的贡献,也就是哪些因素会造成司机流失
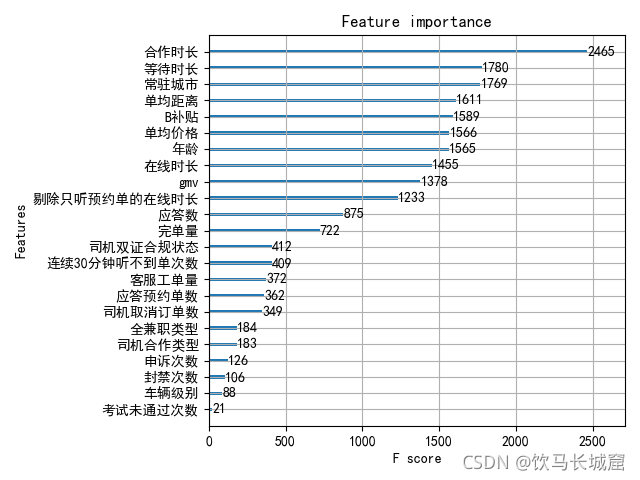
结论:
看来司机流失最大的一个影响因素还是司机的司龄,时间越久,流失风险越低
另外每单的等待时长和单均价格,单均距离 B补都是影响司机流失
同时司机流失的特征,具有很大的城市特异性。
以下是代码:
预测真实数据的脚本
#!/usr/bin/env python
# encoding: utf-8
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score,precision_score
from xgboost import XGBClassifier
import pandas as pd
import numpy as np
df=pd.read_csv(r'D:\work\2\liushi\week1to2.csv')
df=df.set_index(['driver_id'])
print(df.head())
y=df[['yue1_wandan_flag']]
x=df[[ 'age', 'cooperate_dur', 'net_compliance_status',
'driver_participate_way_id', 'resident_city_id', 'full_part_time',
'driver_car_level', 'online_dur', 'except_sub_online_dur',
'answer_sub_cnt', 'continue_no_listen_order_cnt', 'answer_cnt',
'wait_dur', 'dri_cancel_cnt', 'danjun_juli', 'finish_cnt', 'gmv',
'danjiage', 'subsidy_b', 'gongdans', 'events', 'fengjins',
'exams', 'shensus' ]]
y=y.values
x=x.values
###------------------------------------------------------
df_yue2=pd.read_csv(r'D:\work\2\liushi\week2to3.csv')
print(df_yue2.head())
x2=df_yue2[[ 'age', 'cooperate_dur', 'net_compliance_status',
'driver_participate_way_id', 'resident_city_id', 'full_part_time',
'driver_car_level', 'online_dur', 'except_sub_online_dur',
'answer_sub_cnt', 'continue_no_listen_order_cnt', 'answer_cnt',
'wait_dur', 'dri_cancel_cnt', 'danjun_juli', 'finish_cnt', 'gmv',
'danjiage', 'subsidy_b', 'gongdans', 'events', 'fengjins',
'exams', 'shensus' ]]
x2=x2.values
#X_train, X_test, Y_train, Y_test = train_test_split(x, y, test_size=0.033, random_state=7)
model = XGBClassifier( max_depth=9,subsample=0.5)
model.fit(x, y)
# Y_pred = model.predict(X_test)
Y_pred_yu3=model.predict(x2)
predictions = [round(value) for value in Y_pred_yu3]
df_res=pd.DataFrame({
'res':predictions
})
df_res.to_csv('res_of_biaoqian4.csv')训练脚本
#!/usr/bin/env python
# encoding: utf-8
#!/usr/bin/env python
# encoding: utf-8
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score,precision_score
from xgboost import XGBClassifier
import pandas as pd
import numpy as np
from xgboost import plot_importance
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
df=pd.read_csv(r'D:\work\2\liushi\week1to2.csv')
df=df.set_index(['driver_id'])
print(df.head())
y=df[['yue1_wandan_flag']]
x=df[[ 'age', 'cooperate_dur', 'net_compliance_status',
'driver_participate_way_id', 'resident_city_id', 'full_part_time',
'driver_car_level', 'online_dur', 'except_sub_online_dur',
'answer_sub_cnt', 'continue_no_listen_order_cnt', 'answer_cnt',
'wait_dur', 'dri_cancel_cnt', 'danjun_juli', 'finish_cnt', 'gmv',
'danjiage', 'subsidy_b', 'gongdans', 'events', 'fengjins',
'exams', 'shensus' ]]
y=y.values
x=x.values
X_train, X_test, Y_train, Y_test = train_test_split(x, y, test_size=0.33, random_state=7)
model = XGBClassifier( max_depth=9,subsample=0.5)
model.fit(X_train, Y_train)
Y_pred = model.predict(X_test)
predictions = [round(value) for value in Y_pred]
accuracy = accuracy_score(Y_test, predictions)
precision=precision_score(Y_test, predictions)
y2=[ value[0] for value in Y_test]
print(accuracy,precision)
df2=pd.DataFrame({
'Y_test':y2,
'Y_pred':predictions
})
s1=sum(df2['Y_test'])
s2=sum(df2[df2['Y_test']==1]['Y_pred'])
res=s2/s1
df2.to_csv('df2.csv')
print('测试集里面真的流失司机数%s,其中被预测出来流失的司机数%s, 覆盖度是%s'%(s1,s2,res))
model.get_booster().feature_names=[ '年龄', '合作时长', '司机双证合规状态',
'司机合作类型', '常驻城市', '全兼职类型',
'车辆级别', '在线时长', '剔除只听预约单的在线时长',
'应答预约单数', '连续30分钟听不到单次数', '应答数',
'等待时长', '司机取消订单数', '单均距离', '完单量', 'gmv',
'单均价格', 'B补贴', '客服工单量', '扣车次数', '封禁次数',
'考试未通过次数', '申诉次数' ]
plot_importance(model)
plt.show()

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









