






我的课程笔记,欢迎关注:https://github.com/BBuf/how-to-optim-algorithm-in-cuda/tree/master/cuda-mode
CUDA-MODE 第一课课后实战(上)
Nsight Compute简介
Nsight Compute是一个CUDA kernel分析器,它通过硬件计数器和软件收集指标。它使用内置的专业知识来检测kernel常见的性能问题并指出发生这些问题的位置并给出一些解决方法的建议。这一内置规则集和指南就是我们所说的Guided Analysis。下面就结合Lecture1的例子来深入了解下Nsight Compute。
在Nsight Compute中,如果我们把鼠标悬停在各个指标上,我们能获得对应的讲解。
Nsight Compute Profile流程
这里就使用 Lecture 1讲义中的 Triton 实现的矩阵开方代码使用Nsight Compute进行Profile,看一下当前Nsight Compute可以帮助我们获得哪些关键信息。Nsight Compute安装包在 https://developer.nvidia.com/tools-overview/nsight-compute/get-started 可以获得。Nsight Compute提供了Windows/Linux/MacOS等多种操作系统的支持,我们可以根据自己的操作系统选择合适的版本进行安装。我这里选择的方式就是分别在Linux服务器和本地Mac上进行安装,在服务器上使用Nsight Compute Profile之后把生产的xxx.ncu-rep文件在本地Mac上用Nsight Compute打开。
Profile的代码如下所示,命名为 triton_sample.py:
# Adapted straight from https://triton-lang.org/main/getting-started/tutorials/02-fused-softmax.html
import triton
import triton.language as tl
import torch
# if @triton.jit(interpret=True) does not work, please use the following two lines to enable interpret mode
# import os
# os.environ["TRITON_INTERPRET"] = "1"
@triton.jit
def square_kernel(output_ptr, input_ptr, input_row_stride, output_row_stride, n_cols, BLOCK_SIZE: tl.constexpr):
# The rows of the softmax are independent, so we parallelize across those
row_idx = tl.program_id(0)
# The stride represents how much we need to increase the pointer to advance 1 row
row_start_ptr = input_ptr + row_idx * input_row_stride
# The block size is the next power of two greater than n_cols, so we can fit each
# row in a single block
col_offsets = tl.arange(0, BLOCK_SIZE)
input_ptrs = row_start_ptr + col_offsets
# Load the row into SRAM, using a mask since BLOCK_SIZE may be > than n_cols
row = tl.load(input_ptrs, mask=col_offsets < n_cols, other=-float('inf'))
square_output = row * row
# Write back output to DRAM
output_row_start_ptr = output_ptr + row_idx * output_row_stride
output_ptrs = output_row_start_ptr + col_offsets
tl.store(output_ptrs, square_output, mask=col_offsets < n_cols)
def square(x):
n_rows, n_cols = x.shape
# The block size is the smallest power of two greater than the number of columns in `x`
BLOCK_SIZE = triton.next_power_of_2(n_cols)
# Another trick we can use is to ask the compiler to use more threads per row by
# increasing the number of warps (`num_warps`) over which each row is distributed.
# You will see in the next tutorial how to auto-tune this value in a more natural
# way so you don't have to come up with manual heuristics yourself.
num_warps = 4
if BLOCK_SIZE >= 2048:
num_warps = 8
if BLOCK_SIZE >= 4096:
num_warps = 16
# Allocate output
y = torch.empty_like(x)
# Enqueue kernel. The 1D launch grid is simple: we have one kernel instance per row o
# f the input matrix
square_kernel[(n_rows, )](
y,
x,
x.stride(0),
y.stride(0),
n_cols,
num_warps=num_warps,
BLOCK_SIZE=BLOCK_SIZE,
)
return y
torch.manual_seed(0)
x = torch.randn(1823, 781, device='cuda')
y_triton = square(x)
y_torch = torch.square(x)
assert torch.allclose(y_triton, y_torch), (y_triton, y_torch)
Profile的命令为:
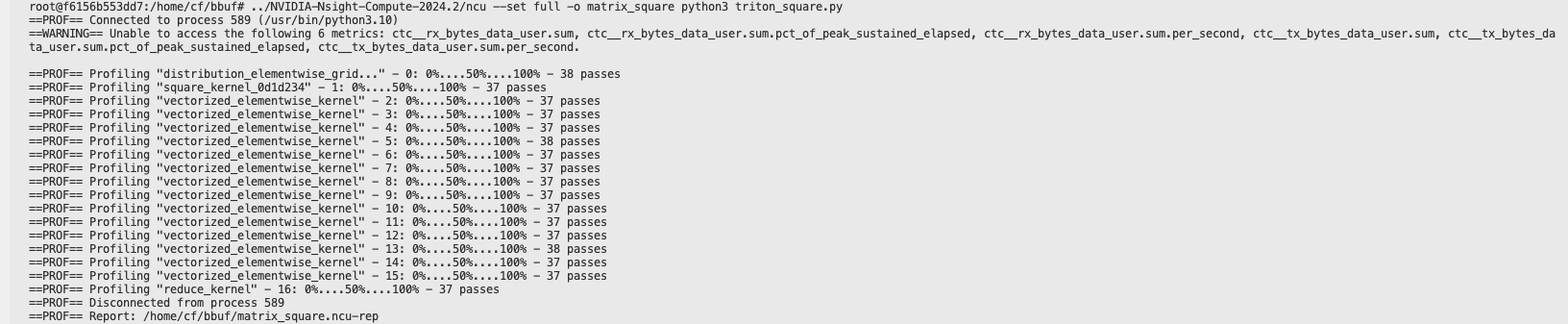
../NVIDIA-Nsight-Compute-2024.2/ncu --set full -o matrix_square python3 triton_sample.py
当出现如下界面并且生成了maxtrix_square.ncu-rep时就说明Profile程序成功运行,我们就可以分析这个文件了。
Nsight Compute Profile结果分析
我们不仅仅可以利用Nsight Compute对程序进行Profile,还可以通过NSight Compute来学习到CUDA的编程模型以及内存模型等等。
Summary部分
Nsight Compute打开maxtrix_square.ncu-rep后的第一页长这样:
-
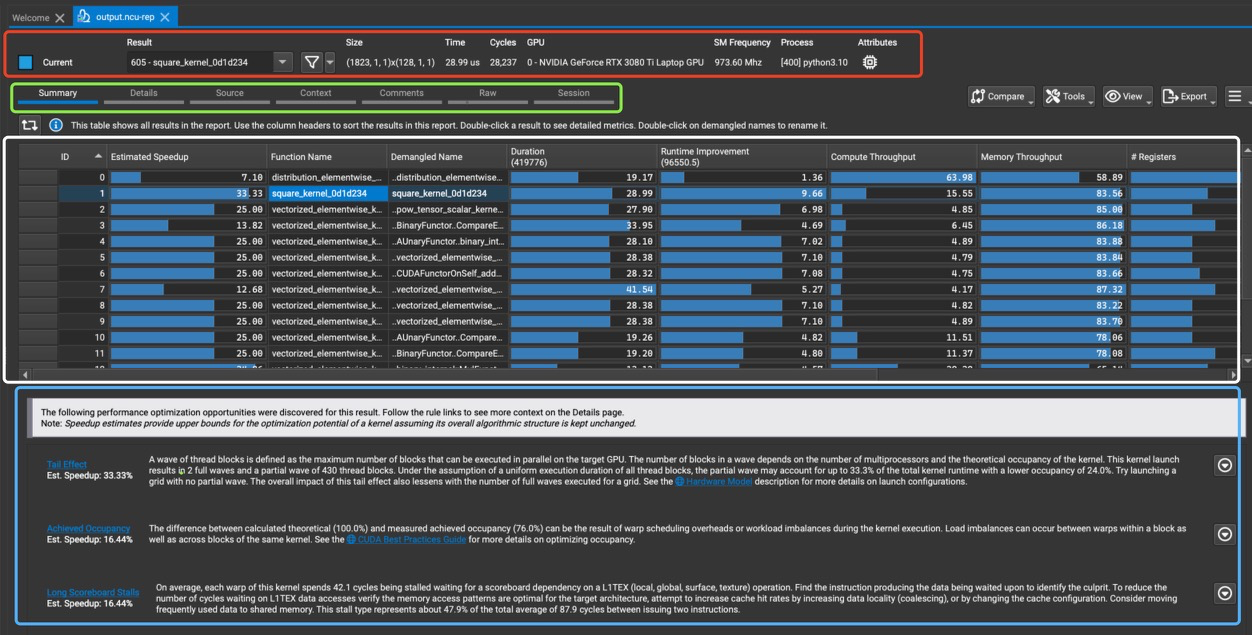
第一个红框部分是顶部的工具栏,Result表示当前选定的Kernel名字是
605 - square_kernel_0d1d234。Size表示的是这个Kernel的启动参数,即Grid Size和Block Size。Time, Cycles, GPU分 别表示执行时间是 28.99 us,周期数是28,327,使用的GPU是NVIDIA GeForce RTX 3080 Ti Laptop GPU。SM Frequency, Process, Attributes分别表示 SM 频率是973.60 MHz,进程ID是[400],运行的程序是python3.10。 -
第二个绿色框部分有多种选择,比如Summary,Details,Source等,一般只关心前3种选择。
-
第三个白色框部分表示这个Summary选择下可以看到的Profile程序里面有哪些Kernel,可以通过光标来选择查看具体的Kernel,比如从Function Name这一栏可以看到当前选择的是
605 - square_kernel_0d1d234这个Kernel。列一下这个表格的所有列:
- ID: 每个函数的唯一标识符。
- Estimated Speedup: 估计的加速比,表示如果优化这个函数可能带来的速度提升。
- Function Name: 函数的名称。
- Demangled Name: 去掉修饰符的函数名称。
- Duration: 函数执行时间(以ns为单位)。
- Runtime Improvement: 估计的运行时间提示(以ns为单位),表示如果优化这个函数可能带来的运行时间提升。
- Compute Throughput: 计算吞吐量。
- Memory Throughput: 内存吞吐量。
- Registers: 每个线程使用的寄存器数量。
- GridSize:kernel启动的网格大小
- BlockSize:每个Block的线程数
- Cycles:指令周期。
当我们鼠标悬停在Compute Throughput这一列时,会显示如下界面:
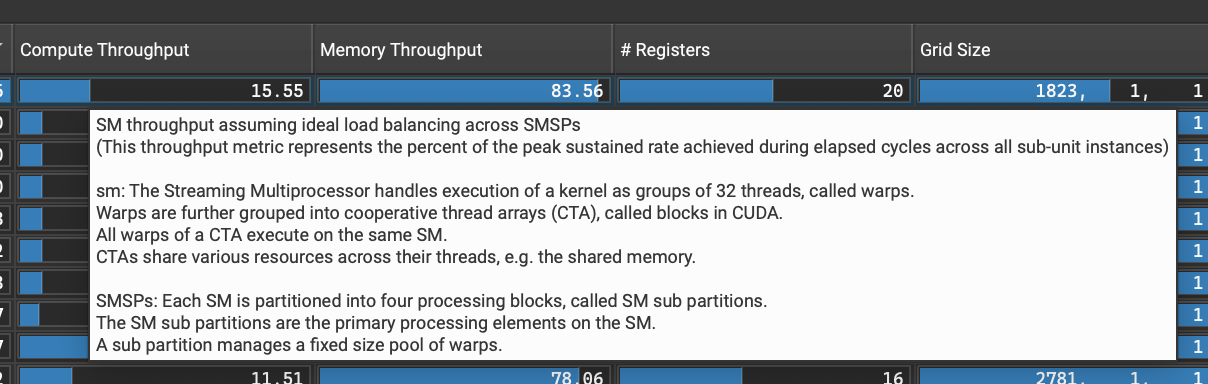
SM 吞吐量假设在 SMSPs 间负载平衡理想的情况下
(此吞吐量指标表示在所有子单元实例的经过周期内达到的峰值持续率的百分比)
sm:流式多处理器(Streaming Multiprocessor)以32个线程为一组执行kernel,称为warp。
warp 进一步分组为合作线程数组(CTA),在CUDA中称为块。
CTA 的所有warp在同一个SM上执行。
CTA 在其线程间共享各种资源,例如共享内存。
SMSPs:每个SM被划分为四个处理块,称为SM子分区。
SM子分区是SM上的主要处理单元。
一个子分区管理一个固定大小的warp池。
当我们鼠标悬停在Memory Throughput这一列时,会显示如下界面:

计算内存管道吞吐量
(此吞吐量指标表示在所有子单元实例的经过周期内达到的峰值持续率的百分比)
gpu:整个图形处理单元。
同样,当我们鼠标悬停在 #Registers 这一列时,会显示如下界面:

每个线程分配的寄存器数量。
寄存器:每个子分区有一组32位寄存器,由硬件以固定大小的块分配。
线程:在GPU的一个SM单元上运行的单个线程。
最后,对Cycles上的界面的翻译为:

在 GPC 上经过的周期数
(此计数器指标表示所有子单元实例中的最大值)
gpc:通用处理集群(General Processing Cluster)包含以 TPC(纹理处理集群)形式存在的 SM、纹理和 L1 缓存。
它在芯片上被多次复制。
从这里展示的细节,我们可以更加详细的了解到到CUDA的编程模型。
- 第4个蓝色框部分都是根据目前kernel的指标给出的粗浅调优建议,比如这里第一条就是因为活跃wave太低给出的调整grid_size和block_size的建议。第二条是计算的理论occupancy(100.0%)和实测的实际occupancy占用(76.0%)之间的差异可能是由于 kernel 执行期间的warp调度开销或工作负载不平衡导致的。在同一kernel 的不同块之间以及块内的不同 warps 之间都可能发生负载不平衡。 第三条则是需要验证内存访问模式是否最优,是否需要使用Shared Memory。
Details部分
SOL部分
首先是 GPU Speed Of Light Throughput部分,它通常位于Details部分的顶部。它清晰的描述了GPU资源的利用情况。在下面的截图中,我们同样可以通过鼠标悬停的方式去看每个指标的细节,这里就不再赘述了。
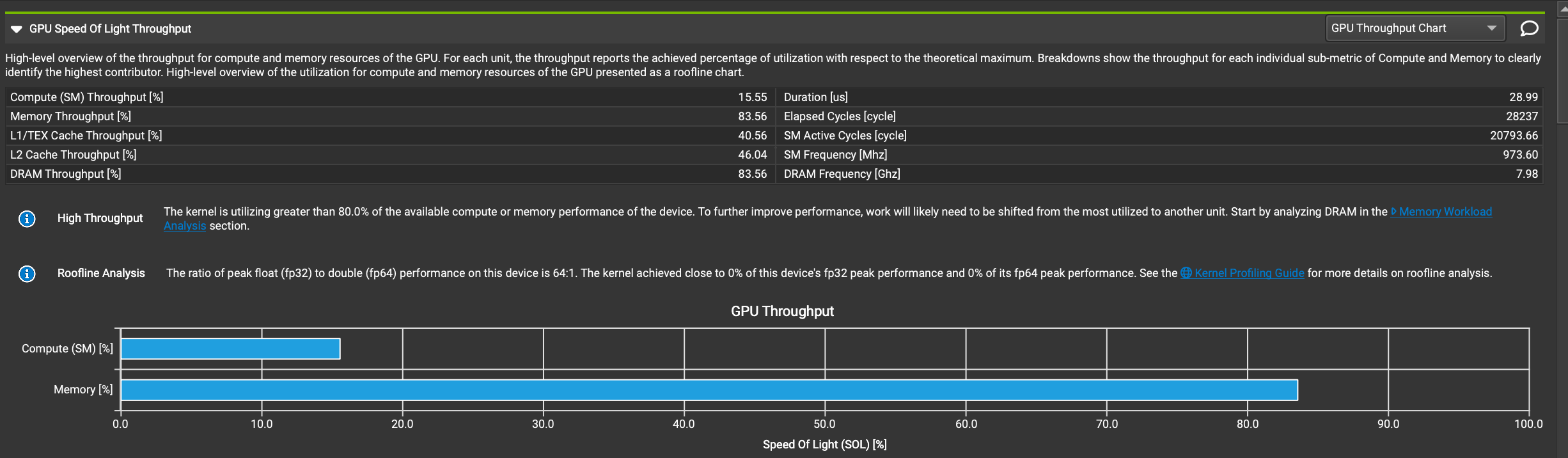
从这个结果可以看出:
- 内存吞吐量(83.56%)远高于计算吞吐量(15.55%),表明这可能是一个内存密集型任务。
- L1/TEX和L2缓存吞吐量相对较低,可能存在优化空间。
- DRAM吞吐量与总体内存吞吐量相同,说明主要的内存操作直接与DRAM交互。
Memory Workload Analysis 部分
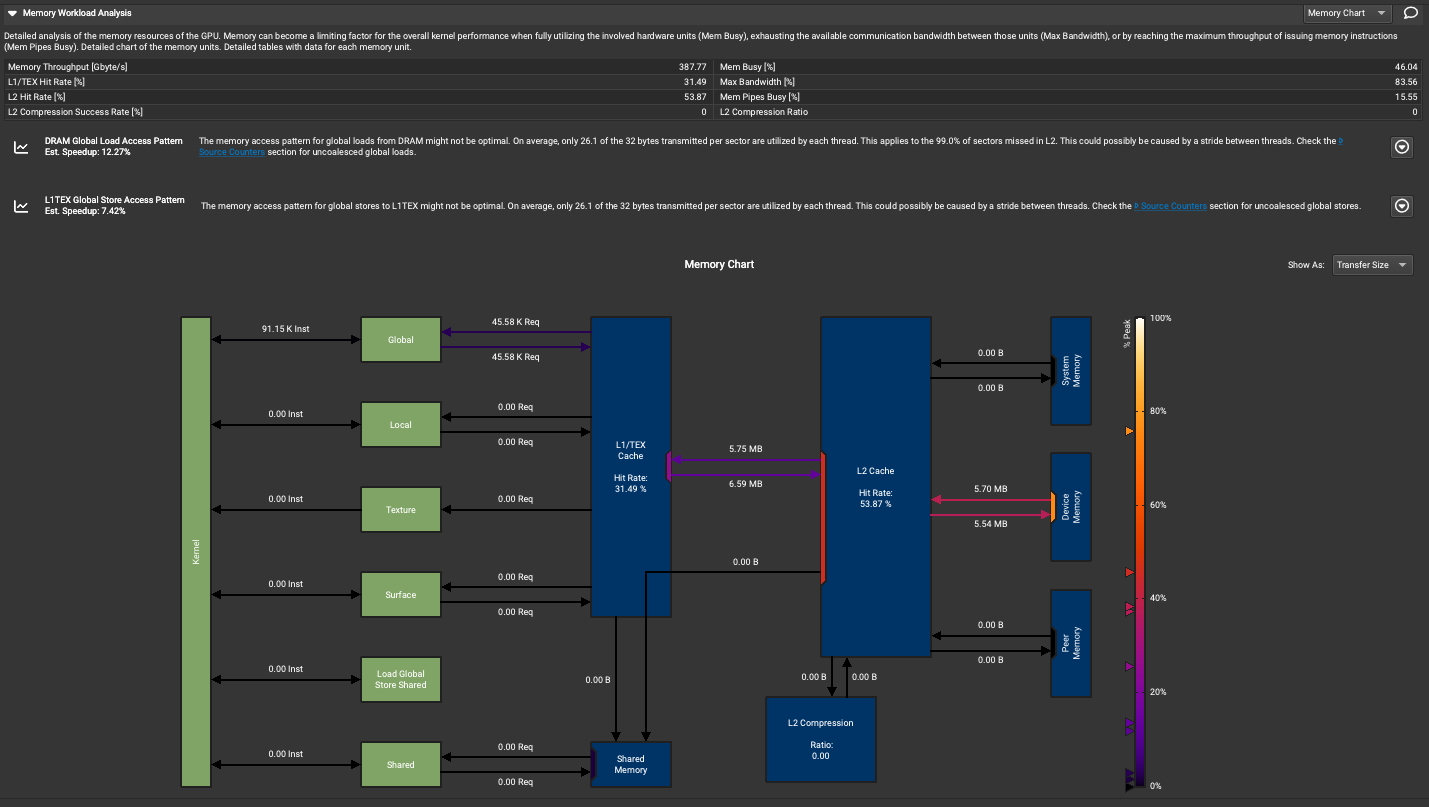
从上到下对每个部分解析一下:
顶部性能指标
Detailed analysis of the memory resources of the GPU. Memory can become a limiting factor for the overall kernel performance when fully utilizing the involved hardware units (Mem Busy), exhausting the available communication bandwidth between those units (Max Bandwidth), or by reaching the maximum throughput of issuing memory instructions (Mem Pipes Busy). Detailed chart of the memory units. Detailed tables with data for each memory unit.
翻译:GPU内存资源的详细分析。当完全利用相关硬件单元(Mem Busy),耗尽这些单元之间可用的通信带宽(最大带宽),或达到发出内存指令的最大吞吐量(内存管道忙碌度)时,内存可能成为整体kernel性能的限制因素。内存单元的详细图表。每个内存单元的详细数据表如下。
- Memory Throughput: 387.77 Gbyte/s
- L1/TEX Hit Rate: 31.49%
- L2 Hit Rate: 53.87%
- L2 Compression Success Rate: 0%
- Mem Busy: 46.04%
- Max Bandwidth: 83.56%
- Mem Pipe Busy: 13.55%
- L2 Compression Ratio: 0
可以通过鼠标悬停的方式看到每个指标的详细信息。
- Memory Throughput

dram__bytes.sum.per_second
在DRAM中访问的字节数
(此计数器度量表示每秒所有子单元实例的操作数总和)
dram:设备(主要)内存,GPU的全局和本地内存所在的位置。
- Mem Busy

gpu_compute_memory_access_throughput.avg.pct_of_peak_sustained_elapsed
计算内存管道:缓存和DRAM内部活动的吞吐量
(这个吞吐量指标表示在所有子单元实例的经过周期内达到的峰值持续速率的百分比)
gpu:整个图形处理单元。
DRAM:设备(主)内存,GPU的全局和本地内存所在位置。
- L1/TEX Hit Rate

l1tex_t_sector_hit_rate.pct
每个sector的sector命中次数
(这个比率指标表示跨所有子单元实例的值,以百分比表示)
l1tex:一级(L1)/纹理缓存位于GPC内部。
它可以用作定向映射的共享内存和/或在其缓存部分存储全局、本地和纹理数据。
l1tex_t 指的是其标签阶段。
l1tex_m 指的是其未命中阶段。
l1tex_d 指的是其数据阶段。
sector:缓存线或设备内存中对齐的32字节内存块。
一个L1或L2缓存线是四个sector,即128字节。
如果标签存在且sector数据在缓存线内,则sector访问被归类为命中。
标签未命中和标签命中但数据未命中都被归类为未命中。
- Max Bandwidth

gpu_compute_memory_request_throughput.avg.pct_of_peak_sustained_elapsed
计算内存管道:SM<->缓存<->DRAM之间互连的吞吐量
(这个吞吐量指标表示在所有子单元实例的经过周期内达到的峰值持续速率的百分比)
gpu:整个图形处理单元。
request:向硬件单元发出的执行某些操作的命令,例如从某个内存位置加载数据。
每个请求访问一个或多个sector。
- L2 Hit Rate

l2s_t_sector_hit_rate.pct
L2sector查找命中的比例
(这个比率指标表示跨所有子单元实例的值,以百分比表示)
l2s:二级(L2)缓存切片是二级缓存的一个子分区。
l2s_t 指的是其标签阶段。
l2s_m 指的是其未命中阶段。
l2s_d 指的是其数据阶段。
sector:缓存线或设备内存中对齐的32字节内存块。
一个L1或L2缓存线是四个sector,即128字节。
如果标签存在且sector数据在缓存线内,则sector访问被归类为命中。
标签未命中和标签命中但数据未命中都被归类为未命中。
其它几个指标就不再列出。
内存访问模式分析

这里显示了两种内存访问模式的性能分析结果:
- DRAM全局加载访问模式
- 问题: 每个线程平均只利用了每个sector传输的32字节中的26.1字节
- 这适用于L2缓存中99.0%的未命中sector
- 可能由线程间的步幅造成
- 估计的加速比为12.27%
- L1TEX全局存储访问模式
- 问题: 每个线程平均只利用了每个sector传输的32字节中的26.1字节
- 可能由线程间的步幅造成
- 估计的加速比为7.42%
两种情况下都建议查看"Source Counters"部分以获取更多关于未合并的全局加载或存储的信息。Source Counters部分请看下一节。
Memory Chart图分析
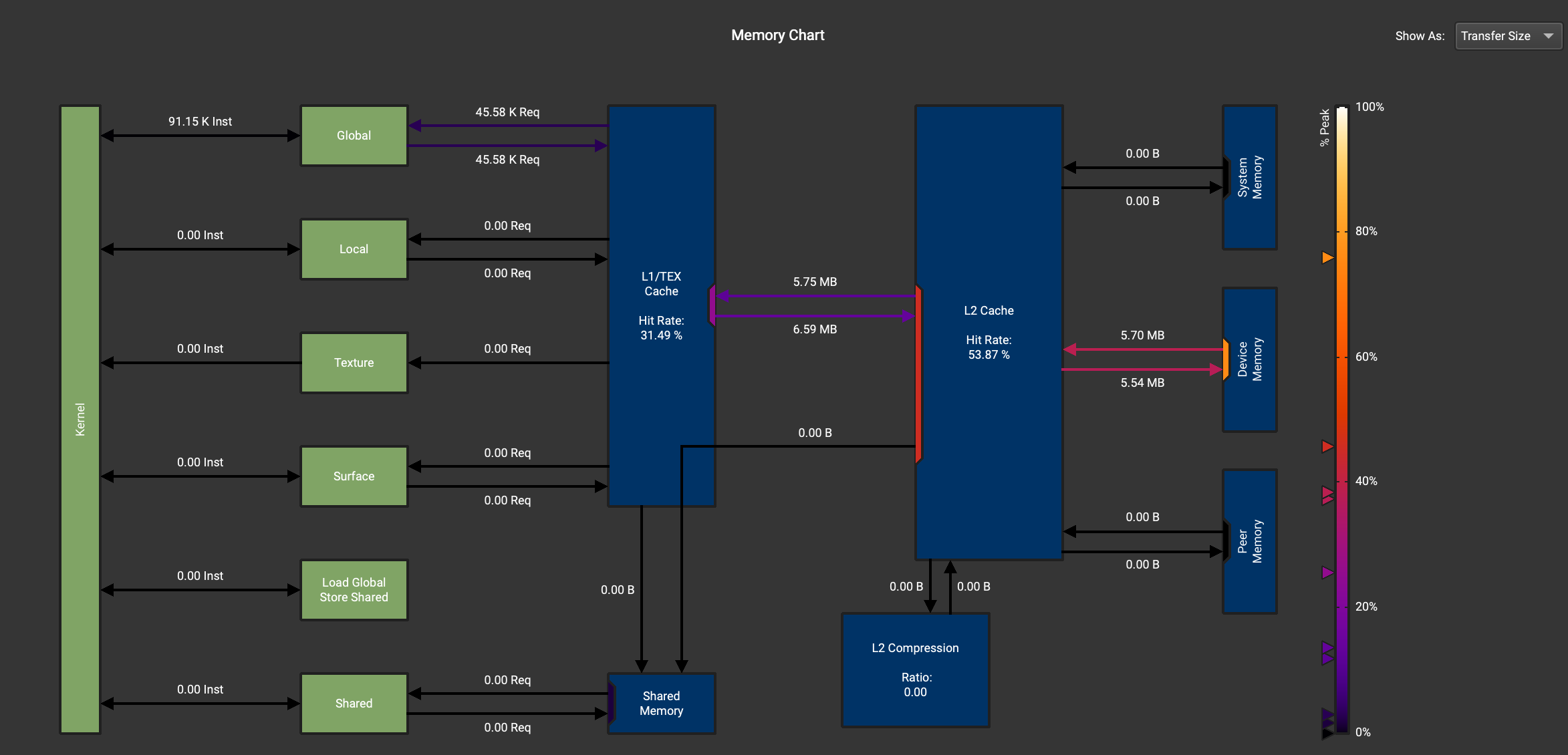
首先程序的输入为x = torch.randn(1823, 781, device='cuda'),也就是需要读写的数据应该是1823*781*4/1024/1024=5.43MB,算上一些local memory读写数据大致是符合预期的,这里我们看不出什么端倪。需要指出的是,我们可以从这个图里面观测自己的kernel从Device Memory读写的数据是否正常来判断程序的优化是否生效。
Source Counters部分
下面这张图展示Source Counters部分的详细信息:
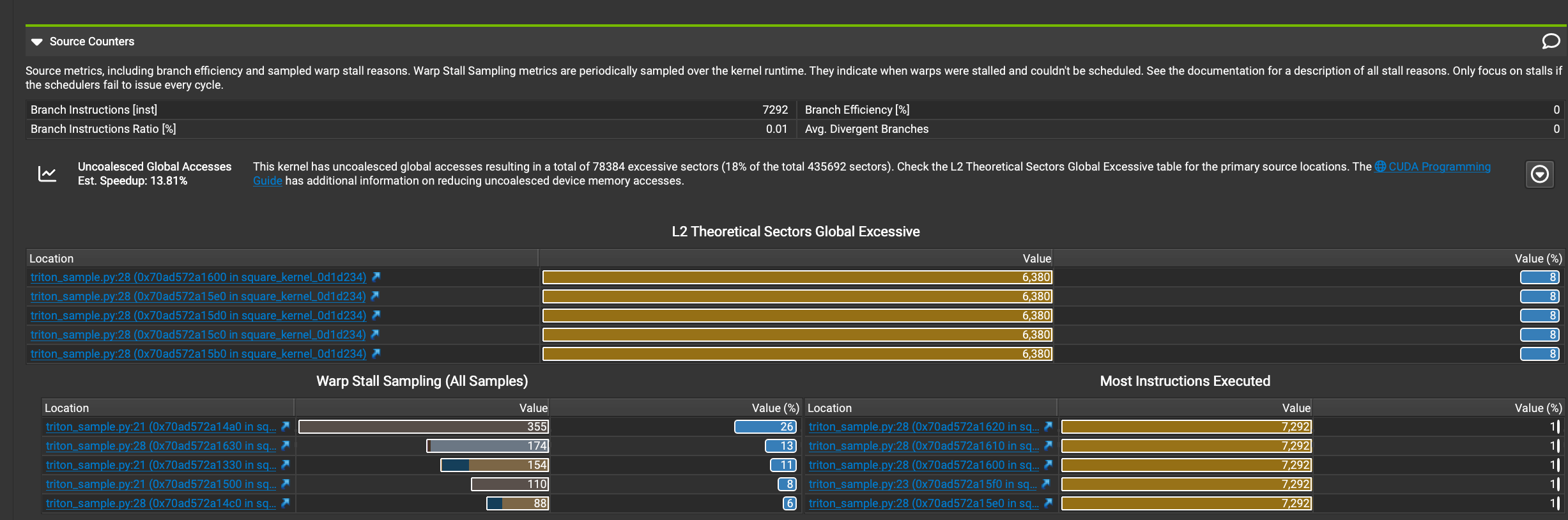
以及源码:
接下来分析下这些信息:
- 分支指令:
- 分支指令数量:7292
- 分支指令比率:0.01%
- 分支效率和平均发散分支都是0,这表明分支预测效果很好。
- 未合并的全局访问:
- 此内核有未合并的全局访问,导致78384个多余的sector(占总sector435692的18%)。
- 估计的加速比:13.81%
- 建议查看L2 Theoretical Sectors Global Excessive表格以获取主要源位置。
- L2 Theoretical Sectors Global Excessive:
- 显示了5个主要的问题位置,都在triton_sample.py文件的第28行,但在不同的内核位置。
- 每个位置的值都是6380,占比均为8%。
- Warp Stall Sampling:
- 显示了warp停滞的主要原因和位置。
- 最严重的停滞发生在triton_sample.py的第21行,值为358,占比27%。
- 其他停滞位置的值分别为171、154、110和88,占比从13%到6%不等。
- Most Instructions Executed:
- 列出了执行指令最多的位置。
- 前5个位置都在triton_sample.py的第28行,每个位置执行了7292条指令,各占1%。
总结下来就是,代码中存在未合并的全局内存访问,这可能导致性能损失。分支效率很高,不是主要的性能瓶颈。主要的性能问题集中在triton_sample.py文件的第21行和第28行。warp停滞是一个值得关注的问题,特别是在第21行。
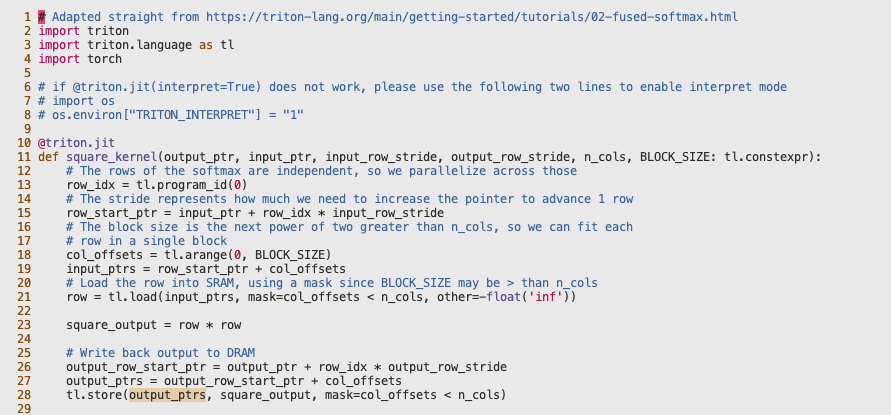
其中,21行代码为:row = tl.load(input_ptrs, mask=col_offsets < n_cols, other=-float('inf')) ,28行代码为:tl.store(output_ptrs, square_output, mask=col_offsets < n_cols) 。
由此可见,如果想继续提升 kernel 的带宽,我们是一定可以从这部分建议里面获得有用的信息。比如,当前代码在存储数据时使用了掩码 mask=col_offsets < n_cols,这可能导致未合并的内存访问,如果可能,将数据填充到 BLOCK_SIZE,这样就不需要使用掩码。或者尝试不同的BLOCK_SIZE获取更好的性能等等。
在下一篇文章里面我们可以看到这部分和Source部分的关联。
Warp State Statistics 部分
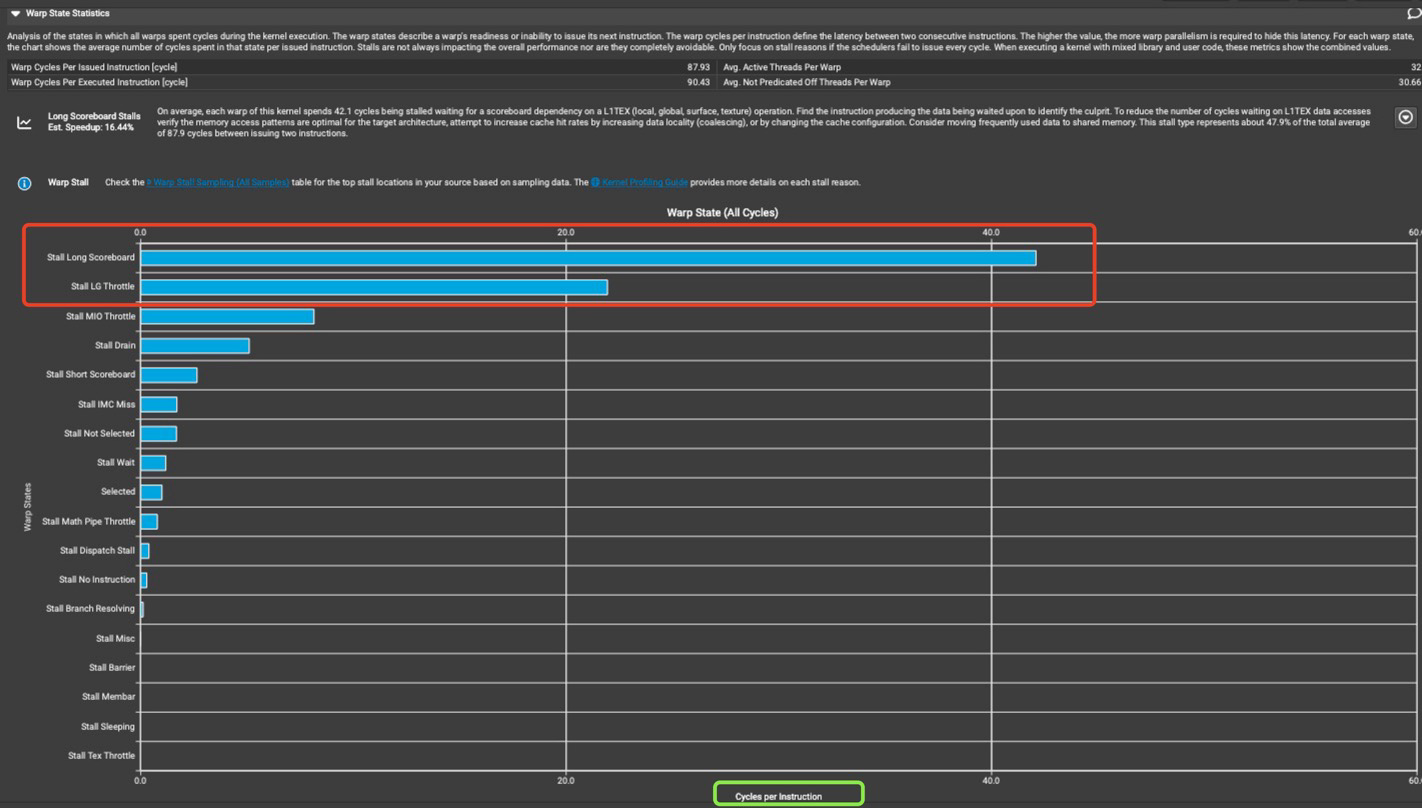
本部分提供了 Kernel 运行期间warp在各状态下消耗的周期,对于每种状态,图标都显示了每个发出指令在该状态下消耗的平均周期数。一般来说,在某种Stall状态中消耗的周期数越多,影响性能的可能性就越大。
On average, each warp of this kernel spends 42.1 cycles being stalled waiting for a scoreboard dependency on a L1TEX (local, global, surface, texture) operation. Find the instruction producing the data being waited upon to identify the culprit. To reduce the number of cycles waiting on L1TEX data accesses verify the memory access patterns are optimal for the target architecture, attempt to increase cache hit rates by increasing data locality (coalescing), or by changing the cache configuration. Consider moving frequently used data to shared memory. This stall type represents about 47.9% of the total average of 87.9 cycles between issuing two instructions.
在这个例子中出现了Long Scoreboard Stalls的警告,并且预期改进的加速为16.44%。平均而言,这个内核的每个 warp 花费 42.1 个周期停滞等待 L1TEX(本地、全局、表面、纹理)操作的记分板依赖。找出产生被等待数据的指令以确定问题所在。为了减少等待 L1TEX 数据访问的周期数,请验证内存访问模式是否对目标架构最优,尝试通过提高数据局部性(合并访问)来增加缓存命中率,或者更改缓存配置。考虑将频繁使用的数据移至共享内存。这种停滞类型占发出两条指令之间总平均 87.9 个周期的约 47.9%。
在展示的结果中,会按照重要性进行排序,以便用户可以关注最重要的问题,因为最重要的问题最有可能产生最大的影响。这里,每条指令的Long Scoreboard Stalls平均占据了近42个周期。这些停滞和访问各个级别的内存层次结构需要的延迟有关。这种类型的内置专业知识可以让用户无需掌握硬件架构专业知识即可了解性能问题。
我们点击Warp Stall Sampling之后跳到了Source Counters部分,具体见上一节的分析。
另外,点击下方红色框的按钮后,我们可以可以看到一些内置规则信息,包括计算中使用了哪些硬件事件以及定义了哪些阈值来指示性能问题。

鼠标悬停到Stall Long Scoreboard或者其它状态上都可以看到对应的知识库,让我们看一下Stall Long Scoreboard的解释:

smsp_average_warps_issue_stalled_long_scoreboard_per_issue_active.ratio
每个发射周期中驻留的平均warp数,等待L1TEX(本地、全局、表面、纹理)操作的记分板依赖
(这个比率指标表示跨所有子单元实例的值)
Warp因等待L1TEX(本地、全局、表面、纹理)操作的记分板依赖而停滞。
要减少等待L1TEX数据访问的周期数,请验证内存访问模式是否适合目标架构。
此外,尝试通过增加数据局部性或更改缓存配置来提高缓存命中率,并考虑将经常使用的数据移至共享内存。
smsp: 每个SM被划分为四个处理块,称为SM子分区。
SM子分区是SM上的主要处理元素。
一个子分区管理固定大小的warp池。
warps: CTA内32个线程的组。
一个warp被分配到一个子分区,并从启动到完成都驻留在该子分区。
L1TEX: 一级(L1)/纹理缓存位于GPC内。
它可以用作直接映射的共享内存和/或在其缓存部分存储全局、本地和纹理数据。
l1tex_t指其标记阶段。
l1tex_m指其未命中阶段。
l1tex_d指其数据阶段。
global: 全局内存是49位虚拟地址空间,映射到设备上的物理内存、锁定的系统内存或对等内存。
全局内存对GPU中的所有线程可见。
全局内存通过SM L1和GPU L2访问。
surface: surface内存
shared: 共享内存位于芯片上,因此比本地或全局内存具有更高的带宽和更低的延迟。
共享内存可以在计算CTA内共享。
分界点
由于篇幅原因,CUDA-MODE 第一课课后实战(上)到此结束,请继续阅读CUDA-MODE 第一课课后实战(下)篇了解剩下的一些Nsight Compute性能分析工具。
- 推荐阅读:https://www.youtube.com/watch?v=04dJ-aePYpE















 1915
1915

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









