







前置准备
- 安装NVIDIA Nsight Compute。 安装好后选择使用管理员权限启动
- 下载官方 Demo 代码
- 官方博客
- Shuffle warp
1. 任务介绍及CPU版本
1.1 任务介绍
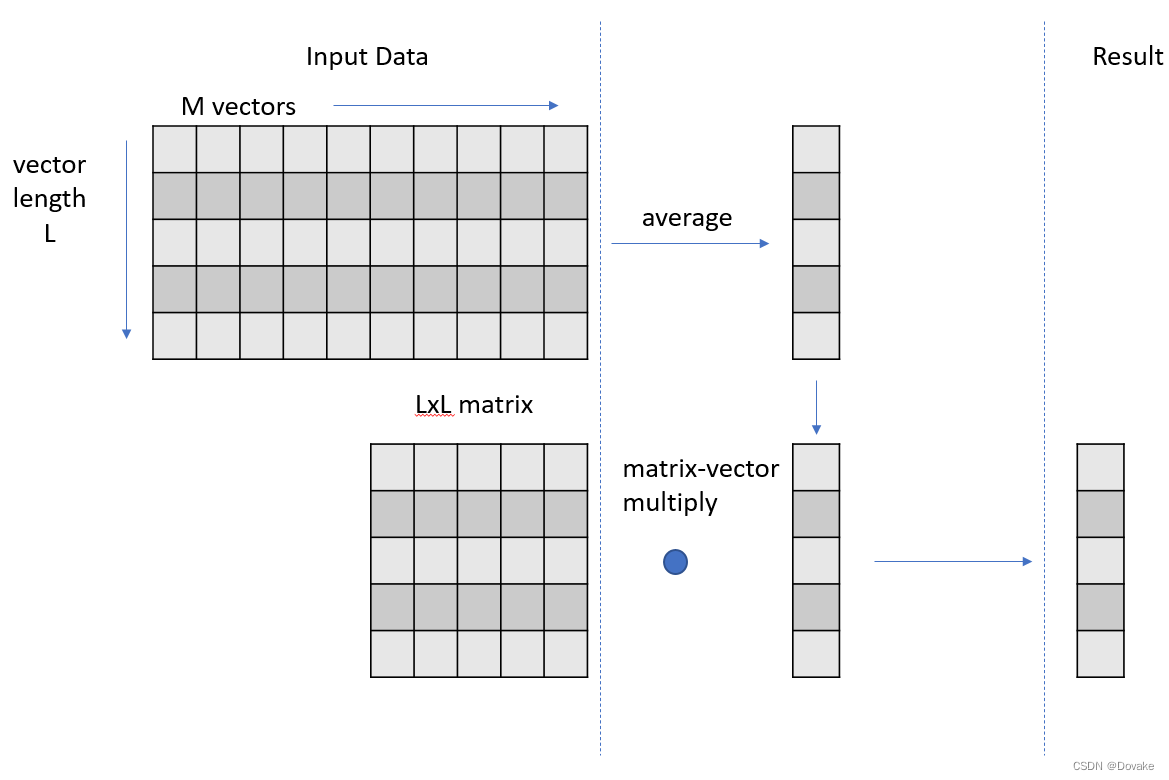
任务理解:
- 有一个 L x M 的矩阵 M 1 M_1 M1 对其每行取平均值 得到 V 1 ∈ R L × 1 V_1 \in \mathbb{R}^{L \times 1} V1∈RL×1 的列向量
- 有一个 L x L 的矩阵 M 2 M_2 M2 与 V 1 V_1 V1做矩阵乘法,最后得到 V 2 ∈ R L × 1 V_2 \in \mathbb{R}^{L \times 1} V2∈RL×1 的列向量
1.2 CPU版本实现
/**
input: input 矩阵,维度为(N, L, M) N为Batch
output: ouput 矩阵,维度为(N, L)
matrix: matrix 维度为(L, L)
*/
template <typename T>
void cpu_version1(T *input, T *output, T *matrix, int L, int M, int N){
#pragma omp parallel for
for (int k = 0; k < N; k++){ // repeat the following, N times
std::vector<T> v1(L); // vector length of L
for (int i = 0; i < M; i++) // compute average vector over M input vectors
for (int j = 0; j < L; j++)
v1[j] += input[k*M*L+j*M+i];
for (int j = 0; j < L; j++)
v1[j] /= M;
for (int i = 0; i < L; i++) // matrix-vector multiply
for (int j = 0; j < L; j++)
output[i*N+k] += matrix[i*L+j]*v1[j];
}
}
1.3 计时逻辑
#include <time.h>
#ifdef __linux__
#define USECPSEC 1000000ULL
#include <sys/time.h>
unsigned long long dtime_usec(unsigned long long start){
timeval tv;
gettimeofday(&tv, 0);
return ((tv.tv_sec*USECPSEC)+tv.tv_usec)-start;
}
#elif defined(WIN32)
#include <windows.h>
double dtime_usec(double start) {
LARGE_INTEGER frequency; // ticks per second
LARGE_INTEGER t1; // ticks
double elapsedTime;
// get ticks per second
QueryPerformanceFrequency(&frequency);
// get current time
QueryPerformanceCounter(&t1);
// compute the elapsed time in micro-second resolution(毫秒)
elapsedTime = (t1.QuadPart - start) * 1000000.0 / frequency.QuadPart;
return elapsedTime;
}
#endif
1.4 main函数
typedef double ft;
int main(){
ft *d_input, *h_input, *d_output, *h_outputc, *h_outputg, *d_matrix, *h_matrix;
int L = my_L; int M = my_M; int N = my_N;
// host allocations
h_input = new ft[N*L*M];
h_matrix = new ft[L*L];
h_outputg = new ft[N*L];
h_outputc = new ft[N*L];
// data initialization
for (int i = 0; i < N*L*M; i++) h_input[i] = (rand()&1)+1; // 1 or 2
for (int i = 0; i < L*L; i++) h_matrix[i] = (rand()&1)+1; // 1 or 2
// create result to test for correctness
LARGE_INTEGER st;
double dt;
QueryPerformanceCounter(&st); // 获取起始时间点
cpu_version1(h_input, h_outputc, h_matrix, L, M, N);
dt = dtime_usec(st.QuadPart);
std::cout << "CPU execution time: \t" << dt / 1000.0f << "ms" << std::endl;
// device allocations
cudaMalloc(&d_input, N*L*M*sizeof(ft));
cudaMalloc(&d_output, N*L*sizeof(ft));
cudaMalloc(&d_matrix, L*L*sizeof(ft));
cudaCheckErrors("cudaMalloc failure");
// copy input data from host to device
cudaMemcpy(d_input, h_input, N*L*M*sizeof(ft), cudaMemcpyHostToDevice);
cudaMemcpy(d_matrix, h_matrix, L*L*sizeof(ft), cudaMemcpyHostToDevice);
cudaMemset(d_output, 0, N*L*sizeof(ft));
cudaCheckErrors("cudaMemcpy/Memset failure");
// run on device and measure execution time
QueryPerformanceCounter(&st); // 获取起始时间点
gpu_version1<<<1, L>>>(d_input, d_output, d_matrix, L, M, N);
cudaCheckErrors("kernel launch failure");
cudaDeviceSynchronize();
cudaCheckErrors("kernel execution failure");
dt = dtime_usec(st.QuadPart);
cudaMemcpy(h_outputg, d_output, N*L*sizeof(ft), cudaMemcpyDeviceToHost);
cudaCheckErrors("cudaMemcpy failure");
for (int i = 0; i < N*L; i++) if (h_outputg[i] != h_outputc[i]) {std::cout << "Mismatch at " << i << " was: " << h_outputg[i] << " should be: " << h_outputc[i] << std::endl; return 0;}
std::cout << "Kernel execution time: \t" << dt / 1000.0f << "ms" << std::endl;
return 0;
}
2. GPU version1
2.1 实现
template<typename T>
__global__ void gpu_version1(
const T * __restrict__ input,
T * __restrict__ output,
const T * __restrict__ matrix,
const int L,
const int M,
const int N
)
{
___shared__ T smem[L];
int idx = threadIdx.x;
// 以此处理N个Batch
for(int k = 0; k < N; i++)
{
T v = 0;
for(int i = 0; i < M; ++i)
{
v += input[K * M * L + M * idx + i]
}
v /= M;
for(int row = 0; row < L; ++row)
{
smem[idx] = v * M[idx * L + row];
// 对矩阵乘法求和
for(int s = blockDim.x >> 1; s > 0; s >>=1)
{
__syncthreads();
if (idx < s) smem[threadIdx.x] += smem[threadIdx.x + s];
}
if (!threadIdx.x) ouput[i*N + row] = smem[0];
}
}
}
const int L = 512; // maximum 1024
const int M = 512;
const int N = 1024;
// 调用核函数
gpu_version1<<<1, L>>>(d_input, d_output, d_matrix, L, M, N);
2.2 时间对比
CPU execution time: 1630.98ms
Kernel execution time: 704.29ms
Accelerate rate: 2.31577
2.3 Nsight 分析
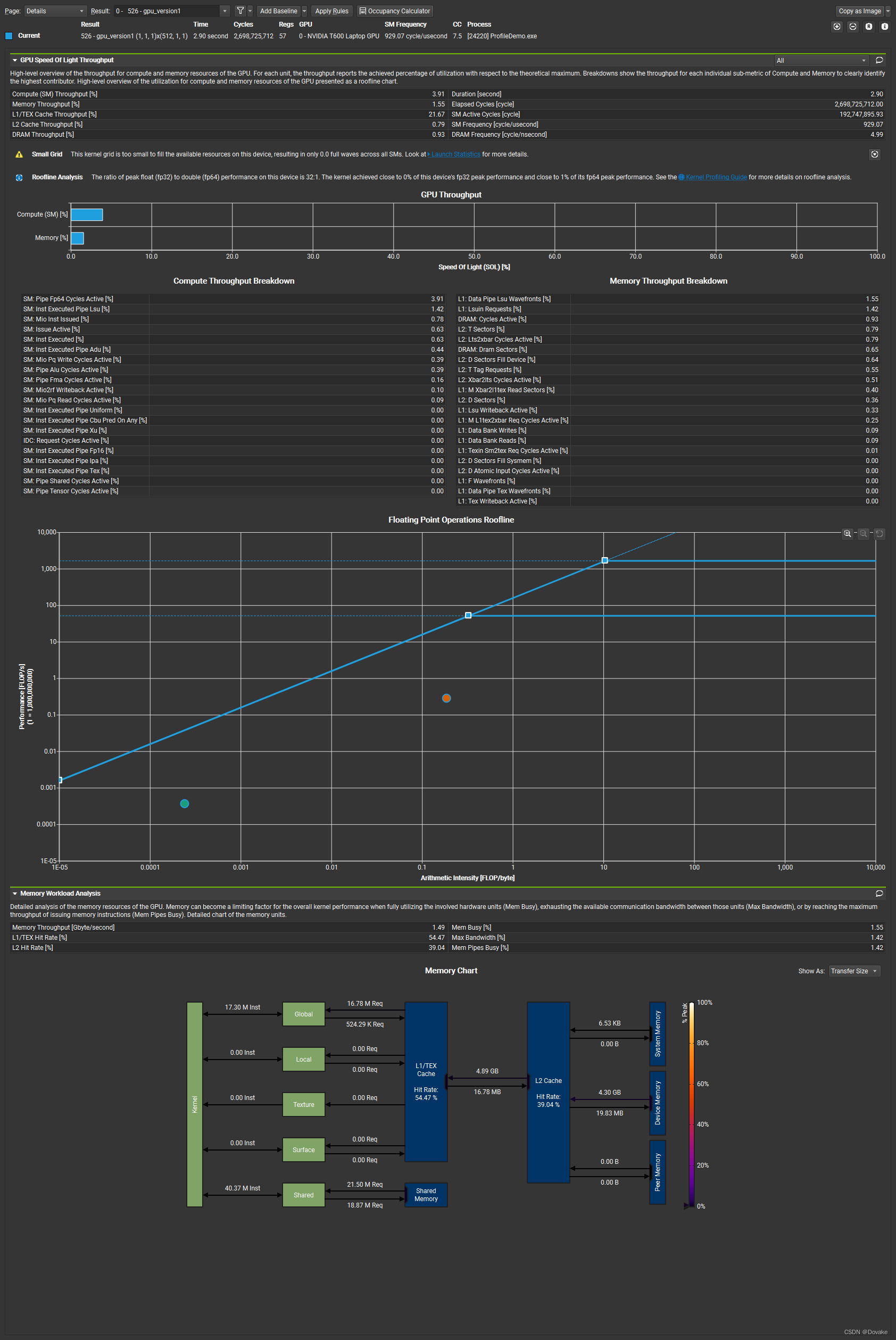
可以看到,这里This kernel grid is too small to fill the available resources on this device, resulting in only 0.0 full waves across all SMs.这里说我们的 grid size 设置得太小了,没有充分利用SM。下一版我们增大 Graid size
3. 增加GridSize
3.1 实现
分析上一个核函数调用:
gpu_version1<<<1, L>>>(d_input, d_output, d_matrix, L, M, N);
这里grid size是1,这里可以考虑把这个设置为 Batch size 即 N
gpu_version1<<<N, L>>>(d_input, d_output, d_matrix, L, M, N);
对应得核函数修改, 其实就是 把k 替换成了 blockIdx.x
template <typename T>
__global__ void gpu_version2(const T* __restrict__ input, T* __restrict__ output, const T* __restrict__ matrix, const int L, const int M, const int N) {
// parallelize threadIdx.x over vector length, and blockIdx.x across k (N)
__shared__ T smem[my_L];
int idx = threadIdx.x;
int k = blockIdx.x;
T v1 = 0;
for (int i = 0; i < M; i++)
v1 += input[k * M * L + idx * M + i];
v1 /= M;
for (int i = 0; i < L; i++) {
__syncthreads();
smem[threadIdx.x] = v1 * matrix[i * L + idx];
for (int s = blockDim.x >> 1; s > 0; s >>= 1) {
__syncthreads();
if (threadIdx.x < s) smem[threadIdx.x] += smem[threadIdx.x + s];
}
if (!threadIdx.x) output[k + i * N] = smem[0];
}
}
3.2 时间对比
CPU execution time: 1984.43ms
Kernel execution time: 132.216ms
Accelerate rate: 15.009
可以看到相对v1 提高了15倍 +
3.3 Nsight 分析
3.3.1 概览
相比上一个版本,SM和memory的利用率明显提高了。
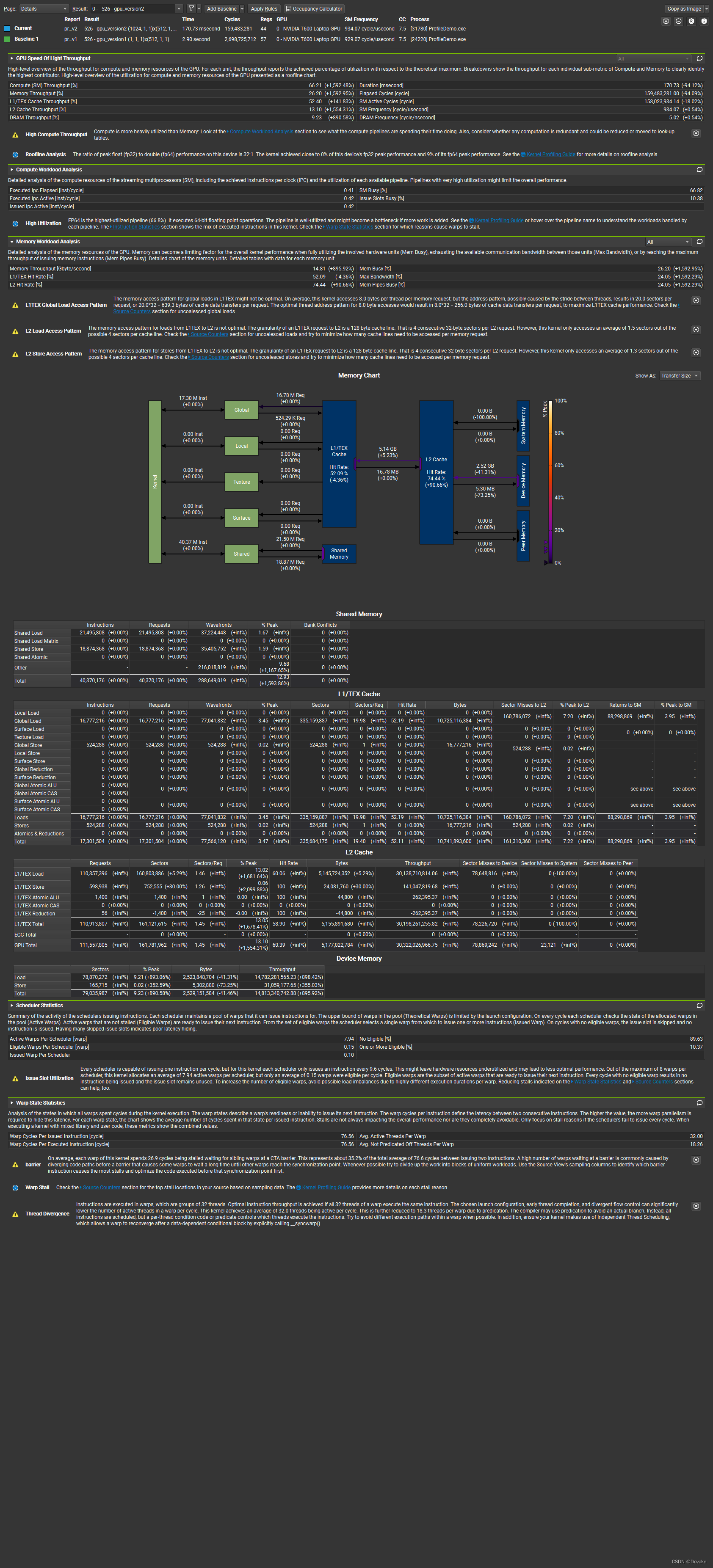
3.3.2 Memoy Workload Analysis
The memory access pattern for global loads in L1TEX might not be optimal. On average, this kernel accesses 8.0 bytes per thread per memory request; but the address pattern, possibly caused by the stride between threads, results in 20.0 sectors per request, or 20.032 = 639.3 bytes of cache data transfers per request. The optimal thread address pattern for 8.0 byte accesses would result in 8.032 = 256.0 bytes of cache data transfers per request, to maximize L1TEX cache performance. Check the Source Counters section for uncoalesced global loads.
在 L1TEX中,全局加载的内存访问模式可能不是最优的。平均来说,这个kernel 每个线程每次内存请内存会访问8 字节,但是当前的地址模式,可能由于线程之间的跨度导致每次请求了20个 sectors, 每次请求的缓存传输为 20 * 32 = 649.3 字节。对于8字节的访问,最优的线程地址模式使用的缓存传输数据为 8 * 32 = 256字节,为了最大化L1TEX缓存性能,检查没有 coalesed (合并)访问的全局加载。
为什么会导致这么高 ? 可以通过 source页面
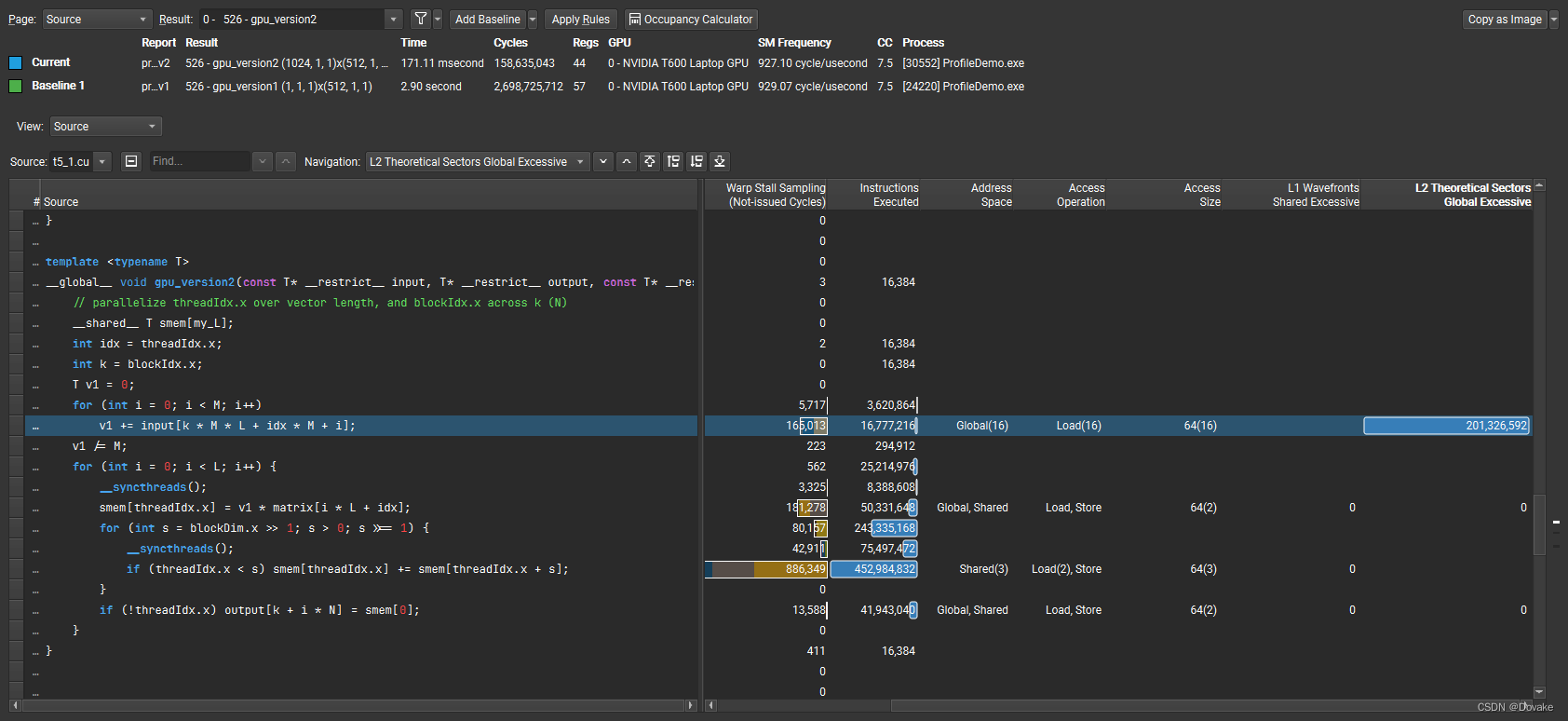
可以发现高亮的这一句进行了大量的L2 Cache访问操作,为什么这一句会导致访问不合并呢?
是因为每次for循环都隔了 idx * M 个数据,导致缓存失效,如何解决这个问题呢?看下一节
4. Shuffle warp
4.1 介绍
高效的并行规约求和在相同的线程block中交换数据,在早期的硬件中这意味着使用共享内存,包括在共享内存中写入,同步,回写。开普勒架构的 shuffle 指令(SHFL)使得线程可以直接读另外一个在同一个warp中的线程的寄存器。这使得在同一个warp的线程可以集体的交换和广播数据。一共有四个这样的内建函数:
__shfl_sync(): 拷贝来自任意 lane id (0~31)线程里得值。_shfl_down()_sync():向下拷贝。__shfl_up()_sync()向上拷贝。shfl_xor_sync()()拷贝来自一个计算出来的lane id 更小的线程里的值。- 源线程和目标线程必须参与计算(不能有一个在if语句里),参数mask用来代表哪些线程需要参与计算。
在这里找到相关的介绍: CUDA C Programming Guide
这个函数的工作方式是:首先,它会计算一个"源 lane ID",这个 ID 是通过在调用该函数的线程的 lane ID(也就是这个线程在 warp 中的位置,从 0 到 31)上加上一个值 delta 得到的。然后,这个函数会返回源 lane ID 对应的线程持有的 var 的值。这就相当于把 var 的值沿着 warp 向下移动了 delta 个位置。
如果源 lane ID 超出了范围,或者源 lane ID 对应的线程已经退出,那么这个函数就会返回调用线程自己的 var 的值。
此外,源 lane ID 不会超过一个叫做 width 的值,所以在 width 之上的 delta 个线程的 var 值不会改变。
这个函数的一个限制是,width 的值必须是 2, 4, 8, 16, 32 中的一个。
虽然实际上 CUDA 的 warp 大小是 32,但是为了简化说明,接下来的示例只会展示 warp 中的 8 个线程。
int received_value = __shfl_down(sent_value, delta, width);
一个具体的例子:
int i = threadIdx.x % 32;
int j = __shfl_down(i, 2, 8);
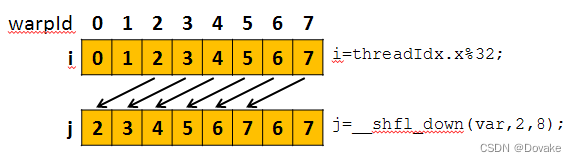
4.2 shuffle 提高访存效率
template<typename T>
__global__ void gpu_version3(const T* __restrict__ input, T* __restrict__ output, const T* __restrict__ matrix, const int L, const int M, const int N) {
__shared__ T smem[my_L];
int idx = threadIdx.x;
int idy = threadIdx.y;
int id = idy * warpSize + idx;
int k = blockIdx.x;
T v1;
for (int y = threadIdx.y; y < L; y += blockDim.y)
{
v1 = 0;
// v = [0,...,31, 32,...,63]
// v1 = v[0] + v[32] + v[64] + ...
// 把一行中的所有元素都加到一个warp里面
//!!! 在一个warp里的线程访存的时候cache命中率就增加了.
for (int x = threadIdx.x; x < M; x += warpSize)
{
v1 += input[k * M * L + y * M + x];
}
// 对warp 里的求和
for (int offset = warpSize >> 1; offset > 0; offset >>= 1)
{
// 读取同一个warp 中的其他线程的寄存器
v1 += __shfl_down_sync(0xFFFFFFFF, v1, offset);
}
//存储每一行的平均值
if (!threadIdx.x) smem[y] = v1 / M;
}
__syncthreads();
v1 = smem[id];
for (int i = 0; i < L; i++) { // matrix-vector multiply
__syncthreads();
smem[id] = v1 * matrix[i * L + id];
for (int s = (blockDim.x * blockDim.y) >> 1; s > 0; s >>= 1) {
__syncthreads();
if (id < s) smem[id] += smem[id + s];
}
if (!id) output[k + i * N] = smem[0];
}
}
4.3 时间对比
CPU execution time: 1497.31ms
Kernel execution time: 54.8245ms
Accelerate rate: 27.3109















 1481
1481

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









