






我的课程笔记,欢迎关注:https://github.com/BBuf/how-to-optim-algorithm-in-cuda/tree/master/cuda-mode
CUDA-MODE 第一课课后实战(下)
Nsight Compute Profile结果分析
继续对Nsight Compute的Profile结果进行分析,
Details部分
接在上篇的 Warp State Statistics 部分 之后。
Compute Workload Analysis 部分
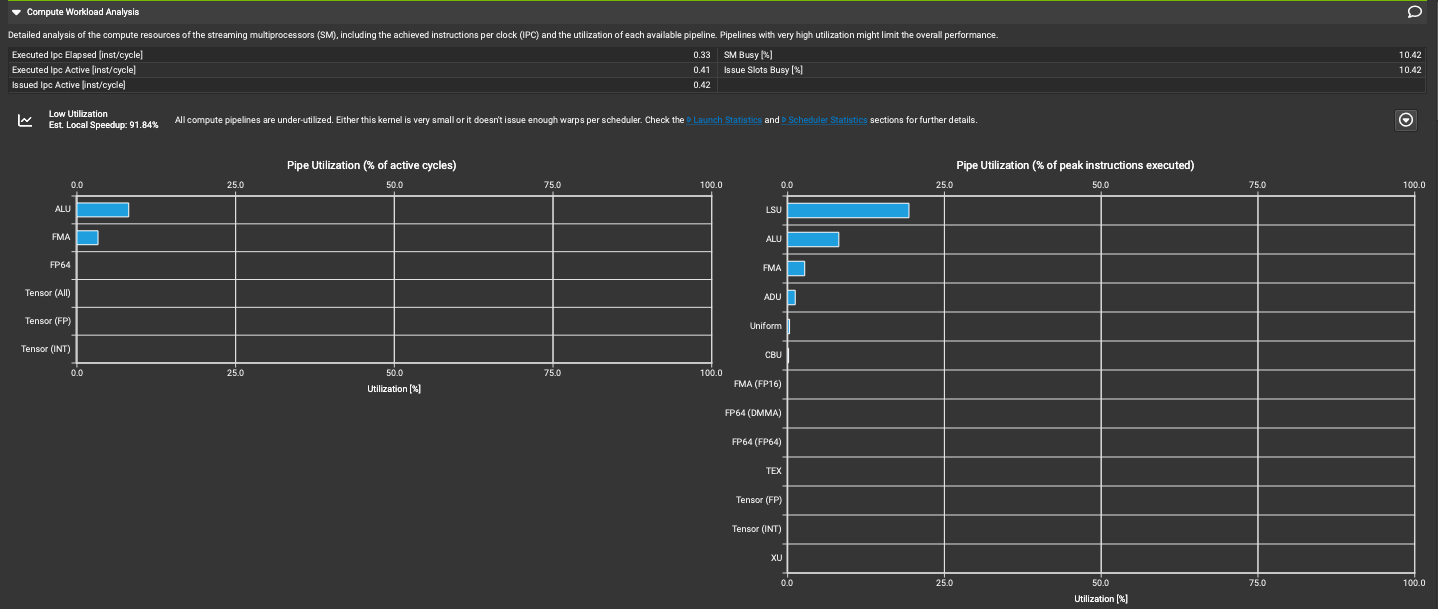
Detailed analysis of the compute resources of the streaming multiprocessors (SM), including the achieved instructions per clock (IPC) and the utilization of each available pipeline. Pipelines with very high utilization might limit the overall performance.
对流式多处理器(SM)的计算资源进行详细分析,包括实际达到的每时钟周期指令数(IPC)以及每个可用流水线的利用率。利用率非常高的流水线可能会限制整体性能。
下面对这里涉及到的表格指标的知识库进行翻译(后面和第一个指标Executed Ipc Elapsed相同部分的翻译就省掉了):
- Executed Ipc Elapsed[inst/cycle]

执行的warp指令数
sm_inst_executed.avg.per_cycle_elapsed
(此计数器指标表示所有子单元实例中每个执行周期的平均操作数)
sm: 流式多处理器以32个线程为一组(称为warps)来处理内核的执行。
Warps进一步分组为协作线程数组(CTA),在CUDA中称为块。
一个CTA的所有warps在同一个SM上执行。
CTA在其线程之间共享各种资源,例如共享内存。
warp: CTA内32个线程的组。
一个warp被分配到一个子分区,并从启动到完成都驻留在该子分区。
instructions: 一条汇编(SASS)指令。
每条执行的指令可能生成零个或多个请求。
- SM Busy

sm_instruction_throughput.avg.pct_of_peak_sustained_active
假设SMSP间理想负载平衡的SM核心指令吞吐量
(此吞吐量指标表示在所有子单元实例的活动周期内达到的峰值持续率的百分比)
SMSPs: 每个SM被划分为四个处理块,称为SM子分区。
SM子分区是SM上的主要处理元素。
一个子分区管理固定大小的warp池。
- Executed Ipc Active[inst/cycle]

sm_inst_executed.avg.per_cycle_active
执行的warp指令数
(此计数器指标表示所有子单元实例中每个活动周期的平均操作数)
- Issue Slots Busy

sm_inst_issued.avg.pct_of_peak_sustained_active
发出的warp指令数
(此计数器指标表示在所有子单元实例的活动周期内达到的峰值持续率的平均百分比)
- Issued Ipc Active[inst/cycle]

sm_inst_issued.avg.per_cycle_active
发出的warp指令数
(此计数器指标表示所有子单元实例中每个活动周期的平均操作数)
接着对后半部分的图标进行分析:
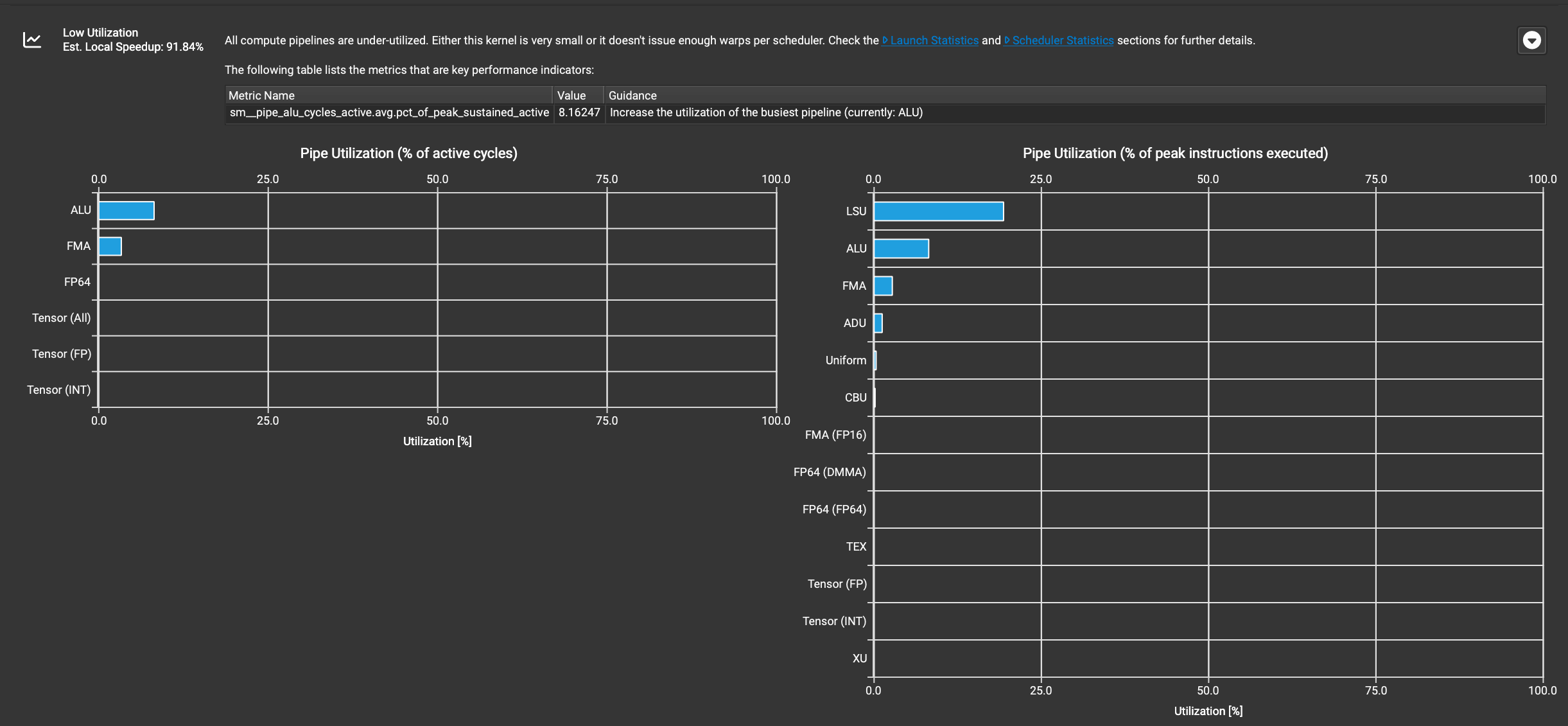
这里提示低利用率(Low Utilization)并且预估加速比可以到91.84%。所有计算Pipline都未被充分利用。这可能是因为内核太小,或者每个调度器没有发出足够的warps。
由于这是个访存密集型算子,计算利用率低其实是正常的,这里的预估加速是一个粗略的计算,不能完全参考。Compute Workload Analysis部分需要结合Memory Workload Analysis 部分来看。
点开Low Utilization最右边那个按钮之后可以看到关键的性能指标以及指导建议。
最下面的Pipline利用率图表分为两部分,分别显示了不同类型pipline的利用率。
此外,图中还建议查看"Launch Statistics"和"Scheduler Statistics"部分以获取更多详细信息,这可能有助于理解为什么Pipline利用率如此之低。
Launch Statistics部分

这里的具体指标的知识库不再赘述,直接看一下Tail Effect部分,这里说的是 Wave 是指可以在目标GPU上并行执行的最大块数。在这个内核中,2个完整Wave和一个部分Wave(包含433个线程块)被执行。假设所有线程块的执行时间均匀,部分Wave可能占总内核运行时间的33.3%,而完整占用度为24.0%。
图中建议尝试启动没有部分 Wave 的网格。减少尾效应也可以减少执行完整网格所需的 Wave 数量。建议查看硬件模型描述以获取更多关于启动配置的详细信息。
Scheduler Statistics部分
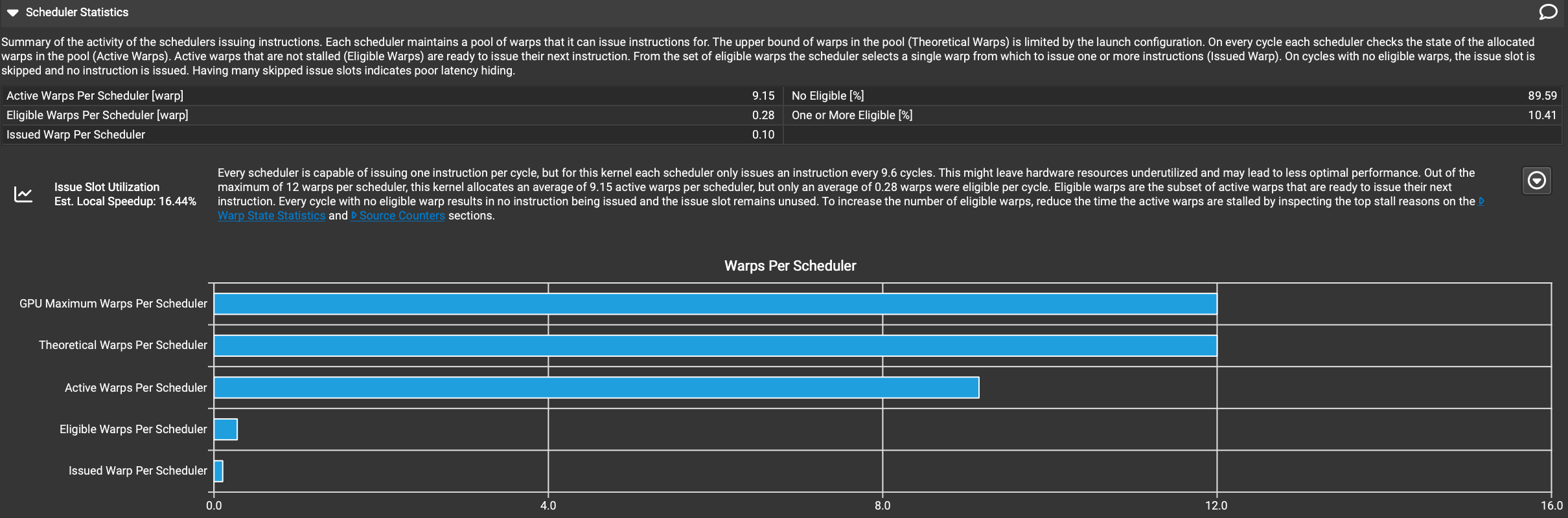
Summary of the activity of the schedulers issuing instructions. Each scheduler maintains a pool of warps that it can issue instructions for. The upper bound of warps in the pool (Theoretical Warps) is limited by the launch configuration. On every cycle each scheduler checks the state of the allocated warps in the pool (Active Warps). Active warps that are not stalled (Eligible Warps) are ready to issue their next instruction. From the set of eligible warps the scheduler selects a single warp from which to issue one or more instructions (Issued Warp). On cycles with no eligible warps, the issue slot is skipped and no instruction is issued. Having many skipped issue slots indicates poor latency hiding.
这是调度器发出指令活动的总结。每个调度器维护一个可以为其发出指令的warp池。池中warp的上限(理论warp数)受启动配置的限制。在每个周期,每个调度器检查池中分配的warp的状态(活跃warps)。未被停滞的活跃warps(Eligible warps)准备好发出它们的下一条指令。从Eligible warps集合中,调度器选择一个warp来发出一条或多条指令(已发射的warp)。在没有Eligible warps的周期中,发射槽被跳过,不发出任何指令。有许多被跳过的发射槽表明延迟隐藏效果不佳。
下面是对指标的知识库进行翻译
- Active Warps Per Scheduler[warp]

smsp__warps_active.avg_per_cycle_active
累计活跃的线程组数量
(该计数器度量了每个活跃周期中所有子单元实例的平均线程组数量)
smsp: 每个SM(流多处理器)被划分为四个处理块,称为SM子分区。
SM子分区是SM上的主要处理单元。
每个子分区管理一个固定大小的线程组池。
warps: 一个CTA(合作线程阵列)中有32个线程。
一个线程组被分配到一个子分区并驻留在该子分区直到完成。
- No Eligible[%]

smsp__issue_inst0.avg.pct_of_peak_sustained_active
在活跃周期中没有指令被发出的活跃周期的百分比。这个计数器指标表示在所有子单元实例中,达到峰值持续活跃状态期间的平均百分比。
instructions: 一个汇编(SASS)指令。
每个执行的指令可能产生零个或多个请求。
- Eligible Warps Per Scheduler[warp]

smsp__issue_active.avg.per_cycle_active
在每个活跃周期中发出1条指令的周期数。这个计数器指标代表所有子单元实例中每个活跃周期的平均操作数。
- One or More Eligible[%]
smsp__issue_active.avg.pct_of_peak_sustained_active
在活跃周期中发出一条指令活跃周期的百分比。这个计数器指标表示在所有子单元实例中,达到峰值持续活跃状态期间的平均百分比。这个指标和No Eligible[%]互补。
后续的分析结果:

- 每个调度器(scheduler)每个周期都可以发出一条指令,但是这个内核每9.6个周期才会发出一条指令。这可能会造成硬件资源的浪费,影响性能表现。
- 每个调度器最多可以分配12个线程组(warp),但这个内核平均只分配了9.15个活跃的线程组。然而,每个周期里平均只有0.28个线程组是可以发出指令的(eligible)。
- 可以发出指令的线程组(eligible warps)是活跃线程组(active warps)的子集,它们是准备好发出下一条指令的。
- 每个周期如果没有可以发出指令的线程组,就会导致调度插槽(issue slot)被浪费,没有发出任何指令。
- 为了提高可以发出指令的线程组数量,需要减少活跃线程组被阻塞的时间。可以查看"Warp State Statistics"和"Source Counters"部分,找出导致线程组被阻塞的主要原因。
"Warp State Statistics"和"Source Counters"部分我们已经看过了,这里反应出的问题就是对Warp Stall现象的解释,是从调度器本身的角度来解释的。
Occupancy 部分
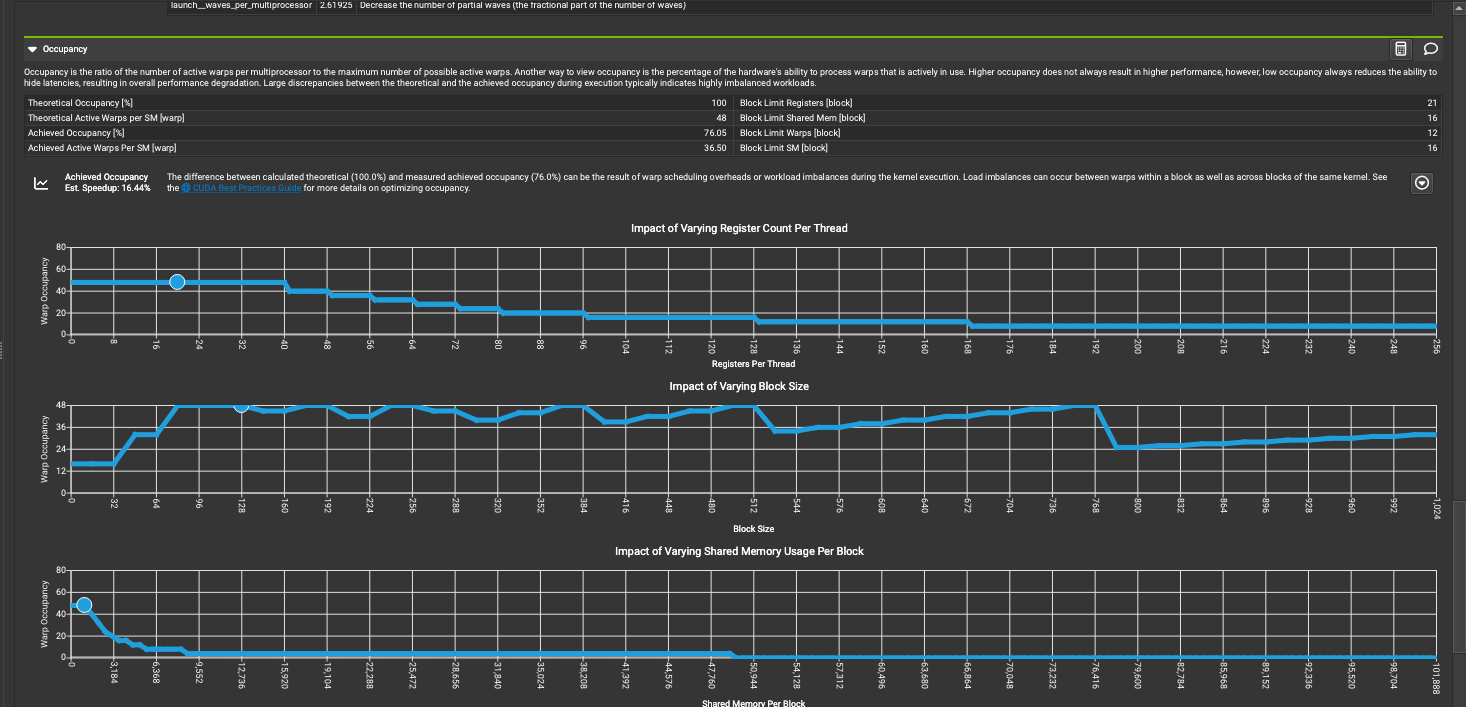
占用率(Occupancy)是指每个SM上活跃线程组(warp)的数量与可能的最大活跃线程组数量的比率。另一种看待占用率的方式是,它表示硬件处理线程组的能力中实际被使用的百分比。虽然较高的占用率并不总能带来更高的性能,但是低占用率会降低隐藏延迟的能力,从而导致整体性能下降。在执行过程中,理论占用率和实际达到的占用率之间存在较大差异,通常表示工作负载高度不均衡。占用率反映了GPU资源的利用情况,是评估CUDA程序性能的一个关键指标。过低的占用率会导致性能下降,需要分析并优化造成低占用率的原因。
首先,理论最大可能活跃线程组数为48个,实际达到的活跃线程组数为36.50个,占用率为76.04%。
然后,根据下面的三张小图可以看到,块大小对性能的影响,每块共享内存用量对性能的影响。
- 随着每线程寄存器数量的增加,性能先上升后下降,存在一个最优值。寄存器数量的增加会限制同时运行的线程数,需要权衡利弊。
- 块大小的变化也会影响性能表现,存在一个最优值。块大小过大会限制并行度,过小则会增加调度开销。
- 共享内存用量的增加会降低可同时运行的块数,从而影响性能。
Source部分
最后来到 Source 部分的解读。
在CUDA-MODE 第一课课后实战(上)中的Source Counters部分已经提到它和Souces部分有关联:
下面这张图展示Source Counters部分的详细信息:
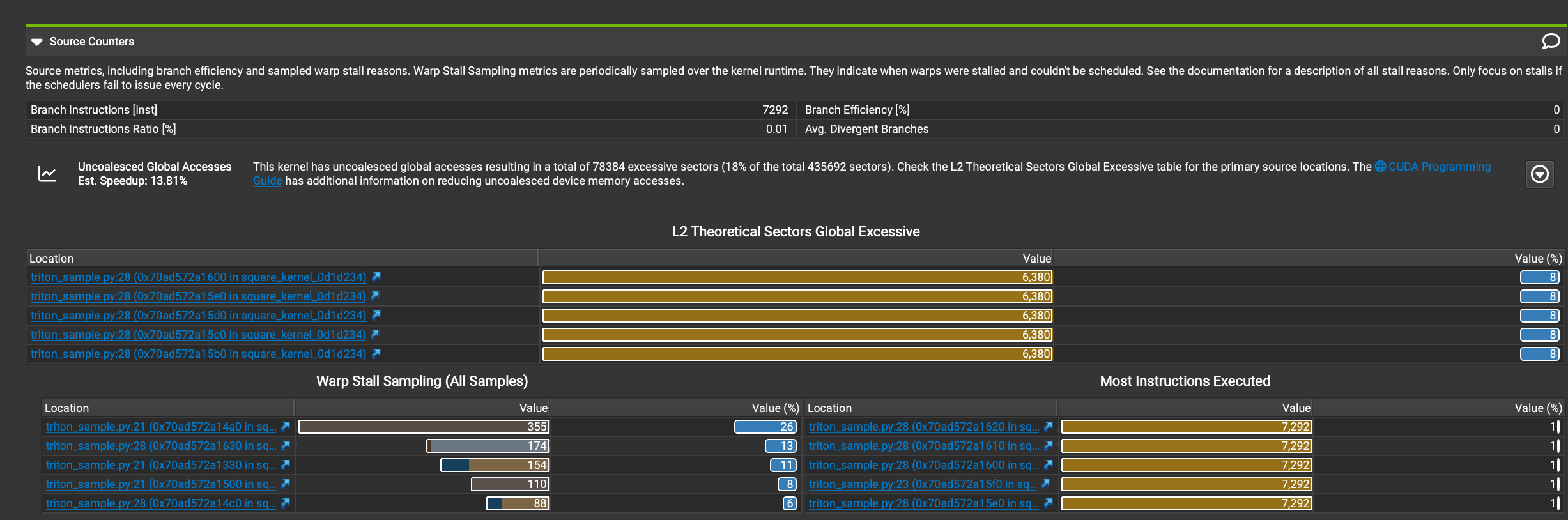
我们可以看到代码中存在未合并的全局内存访问,这可能导致性能损失。分支效率很高,不是主要的性能瓶颈。主要的性能问题集中在triton_sample.py文件的第21行和第28行。warp停滞是一个值得关注的问题,特别是在第21行。
当我们点击绿色的代码链接之后我们就可以跳转到Source部分,直接进入到导致问题的源代码行:
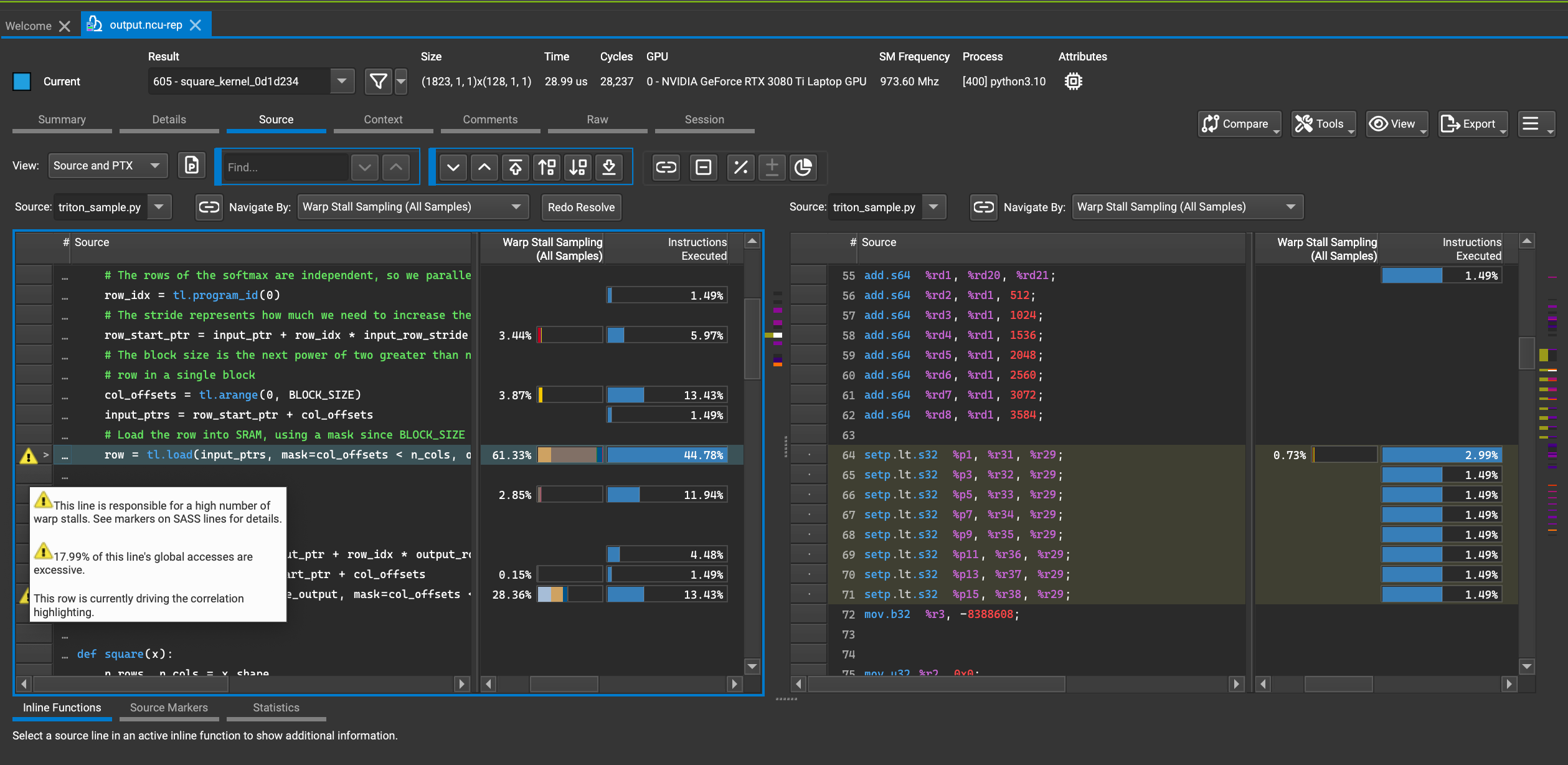
我们不仅可以查看产生问题的源代码,还可以查看编译器生成的PTX/SASS等格式的代码。定位到源代码并结合Source Counters部分给出的建议将对我们优化代码提供很大的帮助。
此外,当我们查看源代码对应的SASS汇编代码时,将鼠标悬停在指令上面,底下即会显示这条汇编的作用(部分指令不会显示)。
总结
通过对Nsight Compute的学习可以发现Nvidia的Profile工具易用性和专业性都非常强,对每个做CUDA开发的开发者来说它都是必不可少的。这两篇文章就是学习CUDA-MODE Lecture1之后在Nsight Compute的实践内容了。
- 推荐阅读:https://www.youtube.com/watch?v=04dJ-aePYpE















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









