









前言
最近感觉对SSE已经算是熟练度更加好了一点了,这一节就来探讨图像处理中一个常见的算法,就是颜色通道转换问题。关于RGB和YUV图像的原理可以在我这篇博客找到:https://blog.csdn.net/just_sort/article/details/87102898 。本篇文章可以看做是读了这篇文章的扩展和总结:https://www.cnblogs.com/Imageshop/p/8405517.html
RGB2YUV朴素实现
void RGBToYUV(unsigned char *RGB, unsigned char *Y, unsigned char *U, unsigned char *V, int Width, int Height, int Stride)
{
const int Shift = 13;
const int HalfV = 1 << (Shift - 1);
const int Y_B_WT = 0.114f * (1 << Shift), Y_G_WT = 0.587f * (1 << Shift), Y_R_WT = (1 << Shift) - Y_B_WT - Y_G_WT;
const int U_B_WT = 0.436f * (1 << Shift), U_G_WT = -0.28886f * (1 << Shift), U_R_WT = -(U_B_WT + U_G_WT);
const int V_B_WT = -0.10001 * (1 << Shift), V_G_WT = -0.51499f * (1 << Shift), V_R_WT = -(V_B_WT + V_G_WT);
for (int YY = 0; YY < Height; YY++)
{
unsigned char *LinePS = RGB + YY * Stride;
unsigned char *LinePY = Y + YY * Width;
unsigned char *LinePU = U + YY * Width;
unsigned char *LinePV = V + YY * Width;
for (int XX = 0; XX < Width; XX++, LinePS += 3)
{
int Blue = LinePS[0], Green = LinePS[1], Red = LinePS[2];
LinePY[XX] = (Y_B_WT * Blue + Y_G_WT * Green + Y_R_WT * Red + HalfV) >> Shift;
LinePU[XX] = ((U_B_WT * Blue + U_G_WT * Green + U_R_WT * Red + HalfV) >> Shift) + 128;
LinePV[XX] = ((V_B_WT * Blue + V_G_WT * Green + V_R_WT * Red + HalfV) >> Shift) + 128;
}
}
}
RGB转YUV的SSE初级优化
void RGBToYUVSSE_1(unsigned char *RGB, unsigned char *Y, unsigned char *U, unsigned char *V, int Width, int Height, int Stride) {
const int Shift = 13;
const int HalfV = 1 << (Shift - 1);
const int Y_B_WT = 0.114f * (1 << Shift), Y_G_WT = 0.587f * (1 << Shift), Y_R_WT = (1 << Shift) - Y_B_WT - Y_G_WT;
const int U_B_WT = 0.436f * (1 << Shift), U_G_WT = -0.28886f * (1 << Shift), U_R_WT = -(U_B_WT + U_G_WT);
const int V_B_WT = -0.10001 * (1 << Shift), V_G_WT = -0.51499f * (1 << Shift), V_R_WT = -(V_B_WT + V_G_WT);
__m128i Weight_YB = _mm_set1_epi32(Y_B_WT), Weight_YG = _mm_set1_epi32(Y_G_WT), Weight_YR = _mm_set1_epi32(Y_R_WT);
__m128i Weight_UB = _mm_set1_epi32(U_B_WT), Weight_UG = _mm_set1_epi32(U_G_WT), Weight_UR = _mm_set1_epi32(U_R_WT);
__m128i Weight_VB = _mm_set1_epi32(V_B_WT), Weight_VG = _mm_set1_epi32(V_G_WT), Weight_VR = _mm_set1_epi32(V_R_WT);
__m128i C128 = _mm_set1_epi32(128);
__m128i Half = _mm_set1_epi32(HalfV);
__m128i Zero = _mm_setzero_si128();
const int BlockSize = 16, Block = Width / BlockSize;
for (int YY = 0; YY < Height; YY++) {
unsigned char *LinePS = RGB + YY * Stride;
unsigned char *LinePY = Y + YY * Width;
unsigned char *LinePU = U + YY * Width;
unsigned char *LinePV = V + YY * Width;
for (int XX = 0; XX < Block * BlockSize; XX += BlockSize, LinePS += BlockSize * 3) {
__m128i Src1, Src2, Src3, Blue, Green, Red;
Src1 = _mm_loadu_si128((__m128i *)(LinePS + 0));
Src2 = _mm_loadu_si128((__m128i *)(LinePS + 16));
Src3 = _mm_loadu_si128((__m128i *)(LinePS + 32));
// 以下操作把16个连续像素的像素顺序由 B G R B G R B G R B G R B G R B G R B G R B G R B G R B G R B G R B G R B G R B G R B G R B G R
// 更改为适合于SIMD指令处理的连续序列 B B B B B B B B B B B B B B B B G G G G G G G G G G G G G G G G R R R R R R R R R R R R R R R R
Blue = _mm_shuffle_epi8(Src1, _mm_setr_epi8(0, 3, 6, 9, 12, 15, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1));
Blue = _mm_or_si128(Blue, _mm_shuffle_epi8(Src2, _mm_setr_epi8(-1, -1, -1, -1, -1, -1, 2, 5, 8, 11, 14, -1, -1, -1, -1, -1)));
Blue = _mm_or_si128(Blue, _mm_shuffle_epi8(Src3, _mm_setr_epi8(-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, 1, 4, 7, 10, 13)));
Green = _mm_shuffle_epi8(Src1, _mm_setr_epi8(1, 4, 7, 10, 13, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1));
Green = _mm_or_si128(Green, _mm_shuffle_epi8(Src2, _mm_setr_epi8(-1, -1, -1, -1, -1, 0, 3, 6, 9, 12, 15, -1, -1, -1, -1, -1)));
Green = _mm_or_si128(Green, _mm_shuffle_epi8(Src3, _mm_setr_epi8(-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, 2, 5, 8, 11, 14)));
Red = _mm_shuffle_epi8(Src1, _mm_setr_epi8(2, 5, 8, 11, 14, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1));
Red = _mm_or_si128(Red, _mm_shuffle_epi8(Src2, _mm_setr_epi8(-1, -1, -1, -1, -1, 1, 4, 7, 10, 13, -1, -1, -1, -1, -1, -1)));
Red = _mm_or_si128(Red, _mm_shuffle_epi8(Src3, _mm_setr_epi8(-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, 0, 3, 6, 9, 12, 15)));
// 以下操作将三个SSE变量里的字节数据分别提取到12个包含4个int类型的数据的SSE变量里,以便后续的乘积操作不溢出
__m128i Blue16L = _mm_unpacklo_epi8(Blue, Zero);
__m128i Blue16H = _mm_unpackhi_epi8(Blue, Zero);
__m128i Blue32LL = _mm_unpacklo_epi16(Blue16L, Zero);
__m128i Blue32LH = _mm_unpackhi_epi16(Blue16L, Zero);
__m128i Blue32HL = _mm_unpacklo_epi16(Blue16H, Zero);
__m128i Blue32HH = _mm_unpackhi_epi16(Blue16H, Zero);
__m128i Green16L = _mm_unpacklo_epi8(Green, Zero);
__m128i Green16H = _mm_unpackhi_epi8(Green, Zero);
__m128i Green32LL = _mm_unpacklo_epi16(Green16L, Zero);
__m128i Green32LH = _mm_unpackhi_epi16(Green16L, Zero);
__m128i Green32HL = _mm_unpacklo_epi16(Green16H, Zero);
__m128i Green32HH = _mm_unpackhi_epi16(Green16H, Zero);
__m128i Red16L = _mm_unpacklo_epi8(Red, Zero);
__m128i Red16H = _mm_unpackhi_epi8(Red, Zero);
__m128i Red32LL = _mm_unpacklo_epi16(Red16L, Zero);
__m128i Red32LH = _mm_unpackhi_epi16(Red16L, Zero);
__m128i Red32HL = _mm_unpacklo_epi16(Red16H, Zero);
__m128i Red32HH = _mm_unpackhi_epi16(Red16H, Zero);
// 以下操作完成:Y[0 - 15] = (Y_B_WT * Blue[0 - 15]+ Y_G_WT * Green[0 - 15] + Y_R_WT * Red[0 - 15] + HalfV) >> Shift;
__m128i LL_Y = _mm_srai_epi32(_mm_add_epi32(_mm_add_epi32(_mm_mullo_epi32(Blue32LL, Weight_YB), _mm_add_epi32(_mm_mullo_epi32(Green32LL, Weight_YG), _mm_mullo_epi32(Red32LL, Weight_YR))), Half), Shift);
__m128i LH_Y = _mm_srai_epi32(_mm_add_epi32(_mm_add_epi32(_mm_mullo_epi32(Blue32LH, Weight_YB), _mm_add_epi32(_mm_mullo_epi32(Green32LH, Weight_YG), _mm_mullo_epi32(Red32LH, Weight_YR))), Half), Shift);
__m128i HL_Y = _mm_srai_epi32(_mm_add_epi32(_mm_add_epi32(_mm_mullo_epi32(Blue32HL, Weight_YB), _mm_add_epi32(_mm_mullo_epi32(Green32HL, Weight_YG), _mm_mullo_epi32(Red32HL, Weight_YR))), Half), Shift);
__m128i HH_Y = _mm_srai_epi32(_mm_add_epi32(_mm_add_epi32(_mm_mullo_epi32(Blue32HH, Weight_YB), _mm_add_epi32(_mm_mullo_epi32(Green32HH, Weight_YG), _mm_mullo_epi32(Red32HH, Weight_YR))), Half), Shift);
_mm_storeu_si128((__m128i*)(LinePY + XX), _mm_packus_epi16(_mm_packus_epi32(LL_Y, LH_Y), _mm_packus_epi32(HL_Y, HH_Y))); // 4个包含4个int类型的SSE变量重新打包为1个包含16个字节数据的SSE变量
// 以下操作完成: U[0 - 15] = ((U_B_WT * Blue[0 - 15]+ U_G_WT * Green[0 - 15] + U_R_WT * Red[0 - 15] + HalfV) >> Shift) + 128;
__m128i LL_U = _mm_add_epi32(_mm_srai_epi32(_mm_add_epi32(_mm_add_epi32(_mm_mullo_epi32(Blue32LL, Weight_UB), _mm_add_epi32(_mm_mullo_epi32(Green32LL, Weight_UG), _mm_mullo_epi32(Red32LL, Weight_UR))), Half), Shift), C128);
__m128i LH_U = _mm_add_epi32(_mm_srai_epi32(_mm_add_epi32(_mm_add_epi32(_mm_mullo_epi32(Blue32LH, Weight_UB), _mm_add_epi32(_mm_mullo_epi32(Green32LH, Weight_UG), _mm_mullo_epi32(Red32LH, Weight_UR))), Half), Shift), C128);
__m128i HL_U = _mm_add_epi32(_mm_srai_epi32(_mm_add_epi32(_mm_add_epi32(_mm_mullo_epi32(Blue32HL, Weight_UB), _mm_add_epi32(_mm_mullo_epi32(Green32HL, Weight_UG), _mm_mullo_epi32(Red32HL, Weight_UR))), Half), Shift), C128);
__m128i HH_U = _mm_add_epi32(_mm_srai_epi32(_mm_add_epi32(_mm_add_epi32(_mm_mullo_epi32(Blue32HH, Weight_UB), _mm_add_epi32(_mm_mullo_epi32(Green32HH, Weight_UG), _mm_mullo_epi32(Red32HH, Weight_UR))), Half), Shift), C128);
_mm_storeu_si128((__m128i*)(LinePU + XX), _mm_packus_epi16(_mm_packus_epi32(LL_U, LH_U), _mm_packus_epi32(HL_U, HH_U)));
// 以下操作完成:V[0 - 15] = ((V_B_WT * Blue[0 - 15]+ V_G_WT * Green[0 - 15] + V_R_WT * Red[0 - 15] + HalfV) >> Shift) + 128;
__m128i LL_V = _mm_add_epi32(_mm_srai_epi32(_mm_add_epi32(_mm_add_epi32(_mm_mullo_epi32(Blue32LL, Weight_VB), _mm_add_epi32(_mm_mullo_epi32(Green32LL, Weight_VG), _mm_mullo_epi32(Red32LL, Weight_VR))), Half), Shift), C128);
__m128i LH_V = _mm_add_epi32(_mm_srai_epi32(_mm_add_epi32(_mm_add_epi32(_mm_mullo_epi32(Blue32LH, Weight_VB), _mm_add_epi32(_mm_mullo_epi32(Green32LH, Weight_VG), _mm_mullo_epi32(Red32LH, Weight_VR))), Half), Shift), C128);
__m128i HL_V = _mm_add_epi32(_mm_srai_epi32(_mm_add_epi32(_mm_add_epi32(_mm_mullo_epi32(Blue32HL, Weight_VB), _mm_add_epi32(_mm_mullo_epi32(Green32HL, Weight_VG), _mm_mullo_epi32(Red32HL, Weight_VR))), Half), Shift), C128);
__m128i HH_V = _mm_add_epi32(_mm_srai_epi32(_mm_add_epi32(_mm_add_epi32(_mm_mullo_epi32(Blue32HH, Weight_VB), _mm_add_epi32(_mm_mullo_epi32(Green32HH, Weight_VG), _mm_mullo_epi32(Red32HH, Weight_VR))), Half), Shift), C128);
_mm_storeu_si128((__m128i*)(LinePV + XX), _mm_packus_epi16(_mm_packus_epi32(LL_V, LH_V), _mm_packus_epi32(HL_V, HH_V)));
}
for (int XX = Block * BlockSize; XX < Width; XX++, LinePS += 3) {
int Blue = LinePS[0], Green = LinePS[1], Red = LinePS[2];
LinePY[XX] = (Y_B_WT * Blue + Y_G_WT * Green + Y_R_WT * Red + HalfV) >> Shift;
LinePU[XX] = ((U_B_WT * Blue + U_G_WT * Green + U_R_WT * Red + HalfV) >> Shift) + 128;
LinePV[XX] = ((V_B_WT * Blue + V_G_WT * Green + V_R_WT * Red + HalfV) >> Shift) + 128;
}
}
}
这个代码十分简单,就是把上面的C语言代码翻译到SSE代码来执行,这里将BGR图像拆解成B,G,R分别连续排列的原理可以看我之前这篇文章:https://blog.csdn.net/just_sort/article/details/95998524 。
RGB转YUV的SSE高级优化
这样直接翻译为SSE的代码加速比大概为2.2倍。看来加速比不够大啊。考虑一下我们是否可以通过减少指令的个数来加快速度呢?在SSE中有一个函数_mm_madd_epi16,这个函数的功能为:
r0 := (a0 * b0) + (a1 * b1)
r1 := (a2 * b2) + (a3 * b3)
r2 := (a4 * b4) + (a5 * b5)
r3 := (a6 * b6) + (a7 * b7)
如果我们能用这个指令代替我们上面的疯狂加和,或许速度会有一定提高?开干!
我们来看一下原始的转换公式:
LinePY[XX] = (Y_B_WT * Blue + Y_G_WT * Green + Y_R_WT * Red + HalfV) >> Shift;
LinePU[XX] = ((U_B_WT * Blue + U_G_WT * Green + U_R_WT * Red + HalfV) >> Shift) + 128;
LinePV[XX] = ((V_B_WT * Blue + V_G_WT * Green + V_R_WT * Red + HalfV) >> Shift) + 128;
注意到其中HalfV=1<<(Shift-1),我们得到:
LinePY[XX] = (Y_B_WT * Blue + Y_G_WT * Green + Y_R_WT * Red + 1 * HalfV) >> Shift;
LinePU[XX] = (U_B_WT * Blue + U_G_WT * Green + U_R_WT * Red + 257 * HalfV) >> Shift;
LinePV[XX] = (V_B_WT * Blue + V_G_WT * Green + V_R_WT * Red + 257 * HalfV) >> Shift;
通过这样变形,我们就可以只用2个_mm_madd_epi16指令就可以代替之前的大量乘加指令。看下这个指令的描述:Multiplies the 8 signed 16-bit integers from a by the 8 signed 16-bit integers from b,即参与计算的数必须是有符号的16位数据,所以Shift必须取15,由于下面YUV2RGB有点特殊,只能取到13,这里为了保持一致,我在RGB2YUV的过程也把Shift取成了13。
这里比较难实现的一个地方在于这里使用_mm_madd_epi16这里的系数是交叉的,比如我们变量b里面保存了交叉的B和G分量的权重,那么变量a就保存了Blue和Green的像素值,这里有2个实现方法:
1、我们上述代码里已经获得了Blue和Green分量的连续排列变量,这个时候只需要使用unpacklo和unpackhi就能分别获取低8位和高8位的交叉结果。
2、注意到获取Blue和Green分量的连续排列变量时是用的shuffle指令,我们也可以采用不同的shuffle系数直接获取交叉后的结果。
这里采用了第二种方法,速度比较快。
void RGBToYUVSSE_2(unsigned char *RGB, unsigned char *Y, unsigned char *U, unsigned char *V, int Width, int Height, int Stride)
{
const int Shift = 13; // 这里没有绝对值大于1的系数,最大可取2^15次方的放大倍数。
const int HalfV = 1 << (Shift - 1);
const int Y_B_WT = 0.114f * (1 << Shift), Y_G_WT = 0.587f * (1 << Shift), Y_R_WT = (1 << Shift) - Y_B_WT - Y_G_WT, Y_C_WT = 1;
const int U_B_WT = 0.436f * (1 << Shift), U_G_WT = -0.28886f * (1 << Shift), U_R_WT = -(U_B_WT + U_G_WT), U_C_WT = 257;
const int V_B_WT = -0.10001 * (1 << Shift), V_G_WT = -0.51499f * (1 << Shift), V_R_WT = -(V_B_WT + V_G_WT), V_C_WT = 257;
__m128i Weight_YBG = _mm_setr_epi16(Y_B_WT, Y_G_WT, Y_B_WT, Y_G_WT, Y_B_WT, Y_G_WT, Y_B_WT, Y_G_WT);
__m128i Weight_YRC = _mm_setr_epi16(Y_R_WT, Y_C_WT, Y_R_WT, Y_C_WT, Y_R_WT, Y_C_WT, Y_R_WT, Y_C_WT);
__m128i Weight_UBG = _mm_setr_epi16(U_B_WT, U_G_WT, U_B_WT, U_G_WT, U_B_WT, U_G_WT, U_B_WT, U_G_WT);
__m128i Weight_URC = _mm_setr_epi16(U_R_WT, U_C_WT, U_R_WT, U_C_WT, U_R_WT, U_C_WT, U_R_WT, U_C_WT);
__m128i Weight_VBG = _mm_setr_epi16(V_B_WT, V_G_WT, V_B_WT, V_G_WT, V_B_WT, V_G_WT, V_B_WT, V_G_WT);
__m128i Weight_VRC = _mm_setr_epi16(V_R_WT, V_C_WT, V_R_WT, V_C_WT, V_R_WT, V_C_WT, V_R_WT, V_C_WT);
__m128i Half = _mm_setr_epi16(0, HalfV, 0, HalfV, 0, HalfV, 0, HalfV);
__m128i Zero = _mm_setzero_si128();
int BlockSize = 16, Block = Width / BlockSize;
for (int YY = 0; YY < Height; YY++)
{
unsigned char *LinePS = RGB + YY * Stride;
unsigned char *LinePY = Y + YY * Width;
unsigned char *LinePU = U + YY * Width;
unsigned char *LinePV = V + YY * Width;
for (int XX = 0; XX < Block * BlockSize; XX += BlockSize, LinePS += BlockSize * 3)
{
__m128i Src1 = _mm_loadu_si128((__m128i *)(LinePS + 0));
__m128i Src2 = _mm_loadu_si128((__m128i *)(LinePS + 16));
__m128i Src3 = _mm_loadu_si128((__m128i *)(LinePS + 32));
// Src1 : B1 G1 R1 B2 G2 R2 B3 G3 R3 B4 G4 R4 B5 G5 R5 B6
// Src2 : G6 R6 B7 G7 R7 B8 G8 R8 B9 G9 R9 B10 G10 R10 B11 G11
// Src3 : R11 B12 G12 R12 B13 G13 R13 B14 G14 R14 B15 G15 R15 B16 G16 R16
// BGL : B1 G1 B2 G2 B3 G3 B4 G4 B5 G5 B6 0 0 0 0 0
__m128i BGL = _mm_shuffle_epi8(Src1, _mm_setr_epi8(0, 1, 3, 4, 6, 7, 9, 10, 12, 13, 15, -1, -1, -1, -1, -1));
// BGL : B1 G1 B2 G2 B3 G3 B4 G4 B5 G5 B6 G6 B7 G7 B8 G8
BGL = _mm_or_si128(BGL, _mm_shuffle_epi8(Src2, _mm_setr_epi8(-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, 0, 2, 3, 5, 6)));
// BGH : B9 G9 B10 G10 B11 G11 0 0 0 0 0 0 0 0 0 0
__m128i BGH = _mm_shuffle_epi8(Src2, _mm_setr_epi8(8, 9, 11, 12, 14, 15, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1));
// BGH : B9 G9 B10 G10 B11 G11 B12 G12 B13 G13 B14 G14 B15 G15 B16 G16
BGH = _mm_or_si128(BGH, _mm_shuffle_epi8(Src3, _mm_setr_epi8(-1, -1, -1, -1, -1, -1, 1, 2, 4, 5, 7, 8, 10, 11, 13, 14)));
// RCL : R1 0 R2 0 R3 0 R4 0 R5 0 0 0 0 0 0 0
__m128i RCL = _mm_shuffle_epi8(Src1, _mm_setr_epi8(2, -1, 5, -1, 8, -1, 11, -1, 14, -1, -1, -1, -1, -1, -1, -1));
// RCL : R1 0 R2 0 R3 0 R4 0 R5 0 R6 0 R7 0 R8 0
RCL = _mm_or_si128(RCL, _mm_shuffle_epi8(Src2, _mm_setr_epi8(-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, 1, -1, 4, -1, 7, -1)));
// RCH : R9 0 R10 0 0 0 0 0 0 0 0 0 0 0 0 0
__m128i RCH = _mm_shuffle_epi8(Src2, _mm_setr_epi8(10, -1, 13, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1));
// RCH : R9 0 R10 0 R11 0 R12 0 R13 0 R14 0 R15 0 R16 0
RCH = _mm_or_si128(RCH, _mm_shuffle_epi8(Src3, _mm_setr_epi8(-1, -1, -1, -1, 0, -1, 3, -1, 6, -1, 9, -1, 12, -1, 15, -1)));
// BGLL : B1 0 G1 0 B2 0 G2 0 B3 0 G3 0 B4 0 G4 0
__m128i BGLL = _mm_unpacklo_epi8(BGL, Zero);
// BGLH : B5 0 G5 0 B6 0 G6 0 B7 0 G7 0 B8 0 G8 0
__m128i BGLH = _mm_unpackhi_epi8(BGL, Zero);
// RCLL : R1 Half Half Half R2 Half Half Half R3 Half Half Half R4 Half Half Half
__m128i RCLL = _mm_or_si128(_mm_unpacklo_epi8(RCL, Zero), Half);
// RCLH : R5 Half Half Half R6 Half Half Half R7 Half Half Half R8 Half Half Half
__m128i RCLH = _mm_or_si128(_mm_unpackhi_epi8(RCL, Zero), Half);
// BGHL : B9 0 G9 0 B10 0 G10 0 B11 0 G11 0 B12 0 G12 0
__m128i BGHL = _mm_unpacklo_epi8(BGH, Zero);
// BGHH : B13 0 G13 0 B14 0 G14 0 B15 0 G15 0 B16 0 G16 0
__m128i BGHH = _mm_unpackhi_epi8(BGH, Zero);
// RCHL : R9 Half Half Half R10 Half Half Half R11 Half Half Half R12 Half Half Half
__m128i RCHL = _mm_or_si128(_mm_unpacklo_epi8(RCH, Zero), Half);
// RCHH : R13 Half Half Half R14 Half Half Half R15 Half Half Half R16 Half Half Half
__m128i RCHH = _mm_or_si128(_mm_unpackhi_epi8(RCH, Zero), Half);
//
__m128i Y_LL = _mm_srai_epi32(_mm_add_epi32(_mm_madd_epi16(BGLL, Weight_YBG), _mm_madd_epi16(RCLL, Weight_YRC)), Shift);
__m128i Y_LH = _mm_srai_epi32(_mm_add_epi32(_mm_madd_epi16(BGLH, Weight_YBG), _mm_madd_epi16(RCLH, Weight_YRC)), Shift);
__m128i Y_HL = _mm_srai_epi32(_mm_add_epi32(_mm_madd_epi16(BGHL, Weight_YBG), _mm_madd_epi16(RCHL, Weight_YRC)), Shift);
__m128i Y_HH = _mm_srai_epi32(_mm_add_epi32(_mm_madd_epi16(BGHH, Weight_YBG), _mm_madd_epi16(RCHH, Weight_YRC)), Shift);
_mm_storeu_si128((__m128i*)(LinePY + XX), _mm_packus_epi16(_mm_packus_epi32(Y_LL, Y_LH), _mm_packus_epi32(Y_HL, Y_HH)));
__m128i U_LL = _mm_srai_epi32(_mm_add_epi32(_mm_madd_epi16(BGLL, Weight_UBG), _mm_madd_epi16(RCLL, Weight_URC)), Shift);
__m128i U_LH = _mm_srai_epi32(_mm_add_epi32(_mm_madd_epi16(BGLH, Weight_UBG), _mm_madd_epi16(RCLH, Weight_URC)), Shift);
__m128i U_HL = _mm_srai_epi32(_mm_add_epi32(_mm_madd_epi16(BGHL, Weight_UBG), _mm_madd_epi16(RCHL, Weight_URC)), Shift);
__m128i U_HH = _mm_srai_epi32(_mm_add_epi32(_mm_madd_epi16(BGHH, Weight_UBG), _mm_madd_epi16(RCHH, Weight_URC)), Shift);
_mm_storeu_si128((__m128i*)(LinePU + XX), _mm_packus_epi16(_mm_packus_epi32(U_LL, U_LH), _mm_packus_epi32(U_HL, U_HH)));
__m128i V_LL = _mm_srai_epi32(_mm_add_epi32(_mm_madd_epi16(BGLL, Weight_VBG), _mm_madd_epi16(RCLL, Weight_VRC)), Shift);
__m128i V_LH = _mm_srai_epi32(_mm_add_epi32(_mm_madd_epi16(BGLH, Weight_VBG), _mm_madd_epi16(RCLH, Weight_VRC)), Shift);
__m128i V_HL = _mm_srai_epi32(_mm_add_epi32(_mm_madd_epi16(BGHL, Weight_VBG), _mm_madd_epi16(RCHL, Weight_VRC)), Shift);
__m128i V_HH = _mm_srai_epi32(_mm_add_epi32(_mm_madd_epi16(BGHH, Weight_VBG), _mm_madd_epi16(RCHH, Weight_VRC)), Shift);
_mm_storeu_si128((__m128i*)(LinePV + XX), _mm_packus_epi16(_mm_packus_epi32(V_LL, V_LH), _mm_packus_epi32(V_HL, V_HH)));
}
for (int XX = Block * BlockSize; XX < Width; XX++, LinePS += 3) {
int Blue = LinePS[0], Green = LinePS[1], Red = LinePS[2];
LinePY[XX] = (Y_B_WT * Blue + Y_G_WT * Green + Y_R_WT * Red + Y_C_WT * HalfV) >> Shift;
LinePU[XX] = (U_B_WT * Blue + U_G_WT * Green + U_R_WT * Red + U_C_WT * HalfV) >> Shift;
LinePV[XX] = (V_B_WT * Blue + V_G_WT * Green + V_R_WT * Red + V_C_WT * HalfV) >> Shift;
}
}
}
YUV2RGB的朴素实现
void YUVToRGB(unsigned char *Y, unsigned char *U, unsigned char *V, unsigned char *RGB, int Width, int Height, int Stride)
{
const int Shift = 13;
const int HalfV = 1 << (Shift - 1);
const int B_Y_WT = 1 << Shift, B_U_WT = 2.03211f * (1 << Shift), B_V_WT = 0;
const int G_Y_WT = 1 << Shift, G_U_WT = -0.39465f * (1 << Shift), G_V_WT = -0.58060f * (1 << Shift);
const int R_Y_WT = 1 << Shift, R_U_WT = 0, R_V_WT = 1.13983 * (1 << Shift);
for (int YY = 0; YY < Height; YY++)
{
unsigned char *LinePD = RGB + YY * Stride;
unsigned char *LinePY = Y + YY * Width;
unsigned char *LinePU = U + YY * Width;
unsigned char *LinePV = V + YY * Width;
for (int XX = 0; XX < Width; XX++, LinePD += 3)
{
int YV = LinePY[XX], UV = LinePU[XX] - 128, VV = LinePV[XX] - 128;
LinePD[0] = ClampToByte(YV + ((B_U_WT * UV + HalfV) >> Shift));
LinePD[1] = ClampToByte(YV + ((G_U_WT * UV + G_V_WT * VV + HalfV) >> Shift));
LinePD[2] = ClampToByte(YV + ((R_V_WT * VV + HalfV) >> Shift));
}
}
}
YUV2RGB的SSE初级实现
和上面一样,直接翻译为SSE代码,没什么技巧:
void YUVToRGBSSE_1(unsigned char *Y, unsigned char *U, unsigned char *V, unsigned char *RGB, int Width, int Height, int Stride) {
const int Shift = 13;
const int HalfV = 1 << (Shift - 1);
const int B_Y_WT = 1 << Shift, B_U_WT = 2.03211f * (1 << Shift), B_V_WT = 0;
const int G_Y_WT = 1 << Shift, G_U_WT = -0.39465f * (1 << Shift), G_V_WT = -0.58060f * (1 << Shift);
const int R_Y_WT = 1 << Shift, R_U_WT = 0, R_V_WT = 1.13983 * (1 << Shift);
__m128i Weight_B_Y = _mm_set1_epi32(B_Y_WT), Weight_B_U = _mm_set1_epi32(B_U_WT), Weight_B_V = _mm_set1_epi32(B_V_WT);
__m128i Weight_G_Y = _mm_set1_epi32(G_Y_WT), Weight_G_U = _mm_set1_epi32(G_U_WT), Weight_G_V = _mm_set1_epi32(G_V_WT);
__m128i Weight_R_Y = _mm_set1_epi32(R_Y_WT), Weight_R_U = _mm_set1_epi32(R_U_WT), Weight_R_V = _mm_set1_epi32(R_V_WT);
__m128i Half = _mm_set1_epi32(HalfV);
__m128i C128 = _mm_set1_epi32(128);
__m128i Zero = _mm_setzero_si128();
const int BlockSize = 16, Block = Width / BlockSize;
for (int YY = 0; YY < Height; YY++) {
unsigned char *LinePD = RGB + YY * Stride;
unsigned char *LinePY = Y + YY * Width;
unsigned char *LinePU = U + YY * Width;
unsigned char *LinePV = V + YY * Width;
for (int XX = 0; XX < Block * BlockSize; XX += BlockSize, LinePY += BlockSize, LinePU += BlockSize, LinePV += BlockSize) {
__m128i Blue, Green, Red, YV, UV, VV, Dest1, Dest2, Dest3;
YV = _mm_loadu_si128((__m128i *)(LinePY + 0));
UV = _mm_loadu_si128((__m128i *)(LinePU + 0));
VV = _mm_loadu_si128((__m128i *)(LinePV + 0));
//UV = _mm_sub_epi32(UV, C128);
//VV = _mm_sub_epi32(VV, C128);
__m128i YV16L = _mm_unpacklo_epi8(YV, Zero);
__m128i YV16H = _mm_unpackhi_epi8(YV, Zero);
__m128i YV32LL = _mm_unpacklo_epi16(YV16L, Zero);
__m128i YV32LH = _mm_unpackhi_epi16(YV16L, Zero);
__m128i YV32HL = _mm_unpacklo_epi16(YV16H, Zero);
__m128i YV32HH = _mm_unpackhi_epi16(YV16H, Zero);
__m128i UV16L = _mm_unpacklo_epi8(UV, Zero);
__m128i UV16H = _mm_unpackhi_epi8(UV, Zero);
__m128i UV32LL = _mm_unpacklo_epi16(UV16L, Zero);
__m128i UV32LH = _mm_unpackhi_epi16(UV16L, Zero);
__m128i UV32HL = _mm_unpacklo_epi16(UV16H, Zero);
__m128i UV32HH = _mm_unpackhi_epi16(UV16H, Zero);
UV32LL = _mm_sub_epi32(UV32LL, C128);
UV32LH = _mm_sub_epi32(UV32LH, C128);
UV32HL = _mm_sub_epi32(UV32HL, C128);
UV32HH = _mm_sub_epi32(UV32HH, C128);
__m128i VV16L = _mm_unpacklo_epi8(VV, Zero);
__m128i VV16H = _mm_unpackhi_epi8(VV, Zero);
__m128i VV32LL = _mm_unpacklo_epi16(VV16L, Zero);
__m128i VV32LH = _mm_unpackhi_epi16(VV16L, Zero);
__m128i VV32HL = _mm_unpacklo_epi16(VV16H, Zero);
__m128i VV32HH = _mm_unpackhi_epi16(VV16H, Zero);
VV32LL = _mm_sub_epi32(VV32LL, C128);
VV32LH = _mm_sub_epi32(VV32LH, C128);
VV32HL = _mm_sub_epi32(VV32HL, C128);
VV32HH = _mm_sub_epi32(VV32HH, C128);
__m128i LL_B = _mm_add_epi32(YV32LL, _mm_srai_epi32(_mm_add_epi32(Half, _mm_mullo_epi32(UV32LL, Weight_B_U)), Shift));
__m128i LH_B = _mm_add_epi32(YV32LH, _mm_srai_epi32(_mm_add_epi32(Half, _mm_mullo_epi32(UV32LH, Weight_B_U)), Shift));
__m128i HL_B = _mm_add_epi32(YV32HL, _mm_srai_epi32(_mm_add_epi32(Half, _mm_mullo_epi32(UV32HL, Weight_B_U)), Shift));
__m128i HH_B = _mm_add_epi32(YV32HH, _mm_srai_epi32(_mm_add_epi32(Half, _mm_mullo_epi32(UV32HH, Weight_B_U)), Shift));
Blue = _mm_packus_epi16(_mm_packus_epi32(LL_B, LH_B), _mm_packus_epi32(HL_B, HH_B));
__m128i LL_G = _mm_add_epi32(YV32LL, _mm_srai_epi32(_mm_add_epi32(Half, _mm_add_epi32(_mm_mullo_epi32(Weight_G_U, UV32LL), _mm_mullo_epi32(Weight_G_V, VV32LL))), Shift));
__m128i LH_G = _mm_add_epi32(YV32LH, _mm_srai_epi32(_mm_add_epi32(Half, _mm_add_epi32(_mm_mullo_epi32(Weight_G_U, UV32LH), _mm_mullo_epi32(Weight_G_V, VV32LH))), Shift));
__m128i HL_G = _mm_add_epi32(YV32HL, _mm_srai_epi32(_mm_add_epi32(Half, _mm_add_epi32(_mm_mullo_epi32(Weight_G_U, UV32HL), _mm_mullo_epi32(Weight_G_V, VV32HL))), Shift));
__m128i HH_G = _mm_add_epi32(YV32HH, _mm_srai_epi32(_mm_add_epi32(Half, _mm_add_epi32(_mm_mullo_epi32(Weight_G_U, UV32HH), _mm_mullo_epi32(Weight_G_V, VV32HH))), Shift));
Green = _mm_packus_epi16(_mm_packus_epi32(LL_G, LH_G), _mm_packus_epi32(HL_G, HH_G));
__m128i LL_R = _mm_add_epi32(YV32LL, _mm_srai_epi32(_mm_add_epi32(Half, _mm_mullo_epi32(VV32LL, Weight_R_V)), Shift));
__m128i LH_R = _mm_add_epi32(YV32LH, _mm_srai_epi32(_mm_add_epi32(Half, _mm_mullo_epi32(VV32LH, Weight_R_V)), Shift));
__m128i HL_R = _mm_add_epi32(YV32HL, _mm_srai_epi32(_mm_add_epi32(Half, _mm_mullo_epi32(VV32HL, Weight_R_V)), Shift));
__m128i HH_R = _mm_add_epi32(YV32HH, _mm_srai_epi32(_mm_add_epi32(Half, _mm_mullo_epi32(VV32HH, Weight_R_V)), Shift));
Red = _mm_packus_epi16(_mm_packus_epi32(LL_R, LH_R), _mm_packus_epi32(HL_R, HH_R));
Dest1 = _mm_shuffle_epi8(Blue, _mm_setr_epi8(0, -1, -1, 1, -1, -1, 2, -1, -1, 3, -1, -1, 4, -1, -1, 5));
Dest1 = _mm_or_si128(Dest1, _mm_shuffle_epi8(Green, _mm_setr_epi8(-1, 0, -1, -1, 1, -1, -1, 2, -1, -1, 3, -1, -1, 4, -1, -1)));
Dest1 = _mm_or_si128(Dest1, _mm_shuffle_epi8(Red, _mm_setr_epi8(-1, -1, 0, -1, -1, 1, -1, -1, 2, -1, -1, 3, -1, -1, 4, -1)));
Dest2 = _mm_shuffle_epi8(Blue, _mm_setr_epi8(-1, -1, 6, -1, -1, 7, -1, -1, 8, -1, -1, 9, -1, -1, 10, -1));
Dest2 = _mm_or_si128(Dest2, _mm_shuffle_epi8(Green, _mm_setr_epi8(5, -1, -1, 6, -1, -1, 7, -1, -1, 8, -1, -1, 9, -1, -1, 10)));
Dest2 = _mm_or_si128(Dest2, _mm_shuffle_epi8(Red, _mm_setr_epi8(-1, 5, -1, -1, 6, -1, -1, 7, -1, -1, 8, -1, -1, 9, -1, -1)));
Dest3 = _mm_shuffle_epi8(Blue, _mm_setr_epi8(-1, 11, -1, -1, 12, -1, -1, 13, -1, -1, 14, -1, -1, 15, -1, -1));
Dest3 = _mm_or_si128(Dest3, _mm_shuffle_epi8(Green, _mm_setr_epi8(-1, -1, 11, -1, -1, 12, -1, -1, 13, -1, -1, 14, -1, -1, 15, -1)));
Dest3 = _mm_or_si128(Dest3, _mm_shuffle_epi8(Red, _mm_setr_epi8(10, -1, -1, 11, -1, -1, 12, -1, -1, 13, -1, -1, 14, -1, -1, 15)));
_mm_storeu_si128((__m128i*)(LinePD + (XX / BlockSize) * BlockSize * 3), Dest1);
_mm_storeu_si128((__m128i*)(LinePD + (XX / BlockSize) * BlockSize * 3 + BlockSize), Dest2);
_mm_storeu_si128((__m128i*)(LinePD + (XX / BlockSize) * BlockSize * 3 + BlockSize * 2), Dest3);
}
for (int XX = Block * BlockSize; XX < Width; XX++, LinePU++, LinePV++, LinePY++) {
int YV = LinePY[XX], UV = LinePU[XX] - 128, VV = LinePV[XX] - 128;
LinePD[XX + 0] = ClampToByte(YV + ((B_U_WT * UV + HalfV) >> Shift));
LinePD[XX + 1] = ClampToByte(YV + ((G_U_WT * UV + G_V_WT * VV + HalfV) >> Shift));
LinePD[XX + 2] = ClampToByte(YV + ((R_V_WT * VV + HalfV) >> Shift));
}
}
}
YUV2RGB的SSE高级实现
基本思路和RGB2YUV的SSE高级实现一样,以LinePD[0]为例子,
LinePD[0] = ClampToByte(YV + ((B_U_WT * UV + HalfV) >> Shift))
展开:
LinePD[0] = ClampToByte(YV * (1 << Shift) + B_U_WT * UV + (1 << (Shift - 1))) >> Shift))
= ClampToByte((YV + 0.5) * (1 << Shift) + B_U_WT * UV) >> Shift))
= ClampToByte((YV * 2 + 1) * ((1 << Shift) >> 1) + B_U_WT * UV) >> Shift))
刚才Shift最大只能取13,是因为这里LinePD[0]的转换里面有个系数2.03>2,为了不数据溢出,只能取13了。这里的实现方法和RGB2YUV的SSE高级优化是一致的,这一部分我就不提供源码了。在ImageShop的博客中还看到一个想法就是,在复现论文或者实际工程中我们一般只会处理Y通道的数据,我们没有必要关注和转换U,V通道的数据,这样我们可以把整个算法处理得更快。
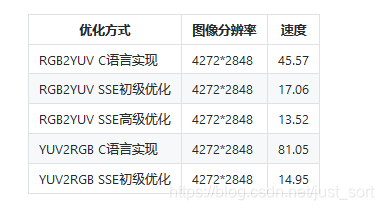
速度测试















 2855
2855











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









