









目录
基于梅老师《智能风控 原理、算法与工程实践》的理解。
1. 特征工程
信用评分模型的主要目的是衡量一个用户的信用风险。因此,特征的构造也要围绕着反映用户信用等级的数据展开。特征构造主要是时间维度的聚合统计及跨时间维度的特征比较。比如,计算一个用户的历史消费数据,可能会分别统计借款时间点之前的每一个月用户的消费金额,然后再计算最近一个月相比于之前几个月的均值是否有显著变化;或者计算历史6个月内,用户每个月的消费金额的增长量,从而得到5个特征,用来度量用户某一维度特征的稳定性。
1.1 数据维度
通常衡量一个用户的还款能力和还款意愿,主要从以下几个角度出发:
个人基本信息:个人基本信息是每个场景下都一定会有的数据,比较典型的信息有年龄、性别、家庭情况等。基本思路是年龄太小和太大都有风险,因为太小没有收入来源,太大有寿命风险。对于性别,女性通常还款意愿强。对于家庭情况,亲戚朋友少的人,逾期时较难向其施压。
金融信息:直接反映用户偿还能力的数据,比如收入、家庭资产等。
多头信息:多头是指用户在多家借款平台贷款的情况。当用户借款平台较多时,会被判断为有负债严重的倾向,这类人通常被认为偿还能力较差。这些可能会被作为策略使用。达到或超过某一阈值,比如15家借款平台,这样的用户是无法通过申请的。
消费信息:典型的消费信息有电商数据、出行数据、外卖数据、点评数据等,这反映了用户在某一段时间内的消费水平。可以尝试计算用户过去一个月在每一种消费上所付出的金额,从而计算出他的购买力。还可以与用户的收入进行对比来估计用户的负债情况。消费过高或过低,或者近期有大幅度开销的情况都需要引起注意。
历史平台表现:用户在借款平台上可能会有一些历史表现。比如,在B卡中,用户有历史还款表现,这是可以直接体现用户还款意愿的特征。可以通过计算用户历史最大、最小逾期天数,以及历史借款的金额之和来估计用户的情况。
埋点数据:App埋点数据也是使用较多的数据之一,用于记录用户点击App上每一个按钮的具体时间和频次。据此可以做一些聚合特征,或者计算不同点击之间的时间间隔。类似的字段在欺诈检测中使用得尤为频繁。
外部征信数据:市场上有很多种征信数据,这些数据对于衡量用户的信用风险会比较有帮助。通常征信公司不会将具体的征信分计算逻辑告诉甲方公司。这里通常直接提取征信分数作为特征,还可以将多条历史征信数据取出来计算均值方差,或者估计增降趋势。
稳定性:除了通过一些固定的维度来看用户的近期表现外,还可将用户上述的每一种维度的变化趋势做成特征,用来衡量用户现在处于生命周期的哪个阶段。比如,电商数据中用户每个月购买总金额的方差一直比较小,就说明客户处于一个稳定的状态。如果贷款前期突然有了巨大开销,那么最近一周消费总金额除以最近一个月消费总金额所得的特征值就会显著增大,这可能会被识别为信用降低的信号。类似的特征还有很多,比如每两个月之间特征的比值,最近一个月单项特征与之前6个月单项特征的均值的比值,等等。
数据密度:在用户的多头记录中,一个用户在一天之内在10家公司贷款和10天每天在一家公司贷款是两种完全不同的概念,按照月份粗粒度统计是不能体现这种信息的。这时候就可以考虑用数据密度来衡量用户的借贷密集程度。数据密度是一种特殊的特征构造方式。比如对多头数据进行月度聚合,可以衍生出另外几个字段:一个月内有多头数据的天数/30,一个月内申请的多头数量/一个月内有申请的天数,等等。这本质上是希望将用户的行为活动所覆盖的时间维度考虑进来。
1.2 特征衍生
特征衍生方案有以下两种:
通过算法自动进行特征交叉,虽然不可以解释但是可以将特征挖掘得较为深入和透彻。可以很轻松地从基础的几百维度衍生至任意维度,比如可以通过XGBoost对特征进行离散,或者通过FM算法进行特征交叉,也可以通过神经网络进行表征学习,然后将内部的参数取出来作为模型的输入。总之,只要是升高了特征维度,再和原始特征合并一起建模,都可以看成是特征衍生。
通过一些跨时间维度的计算逻辑对特征进行时间维度的比较,从而衍生出具有业务含义的特定字段。这种做法会具有更强的解释性,是早些年银行或者信用卡中心惯用的衍生方法之一。例如,现在计算每个用户的额度使用率,记为特征ft。按照时间轴以月份为切片展开,得到申请前30天内的额度使用率ft1,申请前30~60天内的额度使用率ft2,申请前60~90天内的额度使用率ft3,…,申请前330~360天内的额度使用率ft12,于是得到一个用户的12个特征。
1.3 离散处理
将描述性变量(性别、学历……)转换为数值变量。
1.3.1 one-hot编码
对特征类别进行编码,一般一个类别为k个的特征(无序变量)需要编码为一组k-1个衍生哑变量。(避免引起多重共线性)
1.3.1.1 有序分类变量
若分类变量是有序的,直接转换为数值
import pandas as pd
from sklearn import preprocessing
le = preprocessing.LabelEncoder()
df = pd.DataFrame([
['green' , 'A'],
['red' , 'C'],
['blue' , 'B']])
df.columns = ['color', 'class']
#将描述变量自动转换为数值型变量,并将转换后的数据附加到原始数据上
def to_num(data,cat_vars):
for col in cat_vars:
tran = le.fit_transform(data[col].tolist())
tran_df = pd.DataFrame(tran,columns=['num_'+col])
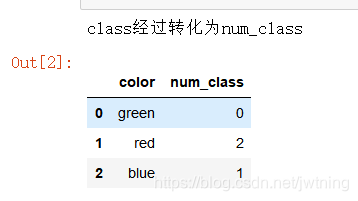
print('{col}经过转化为{num_col}'.format(col=col,num_col='num_'+col))
data = pd.concat([data, tran_df], axis=1)
del data[col] #删除原来的列
return data
cat_vars = ['class']
df = to_num(df,cat_vars)
df结果:
1.3.1.2 无序分类变量
1)使用onehot方法
# 先用LabelEncoder把color、class,这个属性列里面的离散属性用数字来表示
import pandas as pd
df = pd.DataFrame([
['green' , 'A'],
['red' , 'C'],
['blue' , 'B']])
df.columns = ['color', 'class']
df
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import OneHotEncoder
for col in df.columns:
le = LabelEncoder()
le_col = le.fit(df[col])
label = le_col.transform(df[col])
df[col] = label
df
#再用one-hot
ohe = OneHotEncoder()
ohe.fit_transform(df).toarray()结果:

2)使用get_dummies()方法
import pandas as pd
df = pd.DataFrame([
['green' , 'A'],
['red' , 'B'],
['blue' , 'C']])
df.columns = ['color', 'class']
df
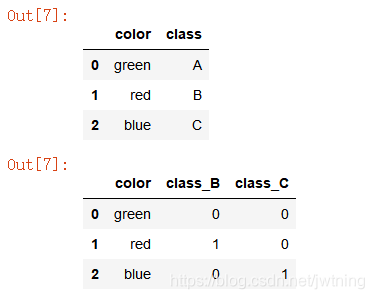
#get_dummies(),法二
for col in df.columns.to_list():
onehot_tran1 = pd.get_dummies(df[col],prefix=col)
onehot_tran2 = pd.get_dummies(df[col],prefix=col,drop_first = True)
df2 = df.join(onehot_tran2)#将one-hot后的数据添加到data中
del df2[col]#删除原来的列
df2结果:
one-hot编码方式很直观,但是有两个缺点:
1)维度爆炸。矩阵的每一维长度都是字典的长度,例如字典包含10 000个单词,那么每个单词对应的one-hot向量就是1×10 000的向量,而这个向量只有一个位置为1,其余都是0,浪费空间。这种高维稀疏数据很多风控领域常用的模型都难以学习,在第7章中会介绍一种对稀疏数据不敏感的模型。
2)关系丢失。one-hot矩阵相当于只简单地给每个单词编了个号,单词和单词之间的关系完全体现不出来。
1.3.2 WOE编码
WOE(Weight of Evidence,证据权重)是一种对原始自变量进行编码的形式。它的定义为:
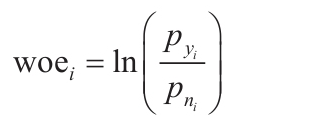
其中,pyi是这个分组中响应客户占样本中所有响应客户的比例,pni是这个分组中未响应客户占样本中所有未响应客户的比例。
WOE实际上表示的是“当前分组中响应客户占样本中所有响应客户的比例”和“当前分组中没有响应的客户占样本中所有没有响应的客户的比例”之间的差异。
WOE也可以理解为,当前分组中响应客户和未响应客户的比值与所有样本中这一比值之间的差异。这个差异是用对这两个比值的比值取对数来表示的。WOE越大,这种差异越大,这个分组里的样本响应的可能性就越大;WOE越小,差异越小,这个分组里的样本响应的可能性就越小。
在对短文本类型的变量进行转换时,WOE映射的效果相比于one-hot编码和词嵌入(Embedding)技术要更有效。其实在最早的评分卡中,无论是对字符型变量还是对数值型变量都要进行WOE映射。对数值型变量进行WOE映射主要是为了弱化极值影响、增加模型鲁棒性。但树模型对极值和变量分布波动并不敏感,因此在XGBoost评分卡中只对字符型变量进行WOE映射。
在实现WOE映射的过程中,最重要的一点是分箱的逻辑,显然分箱不同,得到的WOE映射值会有很大不同。这里使用基于负样本占比差异最大化的分箱原则。所期望得到的分箱结果应该是,箱的总数在5箱以内(可以适当调整,通常不超过10箱),并且每一箱之间的负样本占比差值尽可能大(箱合并原则),每一箱的样本量不能小于整体样本的5%(可以自己根据分箱结果调整,原则是不要太小)。换言之,主要通过控制划分后的总箱数,来迭代进行箱的合并。分箱个数以及最小样本占比需要使用者根据实际情况进行微调。
由于实际建模过程中通常使用3个数据集——训练集(Develop)、测试集(Valuation)、时间外样本集(Out of Time,OOT),所以在本章中默认使用3个数据集进行建模,并通过数据集之间的指标对比进行特征调整与模型调优。需要注意的是,在数据量足够大的情况下,百分比采样得到的测试集和训练集没有明显差异,实际建模中不一定需要保留。
XGBoost等树模型只关心数值的排序,对变量的分布和取值范围并不敏感,所以不需要过多地进行归一化处理。为保证树模型的精度,本案例对数值型变量也未做分箱处理。
1.4 特征筛选
直接根据XGBoost算法的特征重要度少于某一阈值对特征进行筛选,有一定的不合理性:当某些低重要度特征被删除后,其余低重要度特征的重要度会有所上升。本节首先介绍两个用于评价模型表现的函数solveKS和solvePSI,然后使用一种基于迭代思想的特征筛选方法来完成特征筛选的第一个环节。这样做的目的是削弱特征间的相互影响。
1.4.1 solveKS
solveKS函数用来计算当前模型在某数据集上的KS。KS值对模型的评价不受样本不均衡问题的干扰,但仅限于模型评价。如果想获得表现更好的模型,还需要针对不均衡问题进行优化。
def sloveKS(self, model, X, Y, Weight):
Y_predict = [s[1] for s in model.predict_proba(X)]
nrows = X.shape[0]
#还原权重
lis = [(Y_predict[i], Y.values[i], Weight[i]) for i in range(nrows)]
#按照预测概率倒序排列
ks_lis = sorted(lis, key=lambda x: x[0], reverse=True)
KS = list()
bad = sum([w for (p, y, w) in ks_lis if y > 0.5])
good = sum([w for (p, y, w) in ks_lis if y <= 0.5])
bad_cnt, good_cnt = 0, 0
for (p, y, w) in ks_lis:
if y > 0.5:
#1*w 即加权样本个数
bad_cnt += w
else:
#1*w 即加权样本个数
good_cnt += w
ks = abs((bad_cnt/bad)-(good_cnt/good))
KS.append(ks)
return max(KS) 1.4.2 solvePSI
solvePSI函数在本例中用于计算模型在训练集与时间外样本集上的稳定度指标(Population Stability Index,PSI)。风控从业者经常使用PSI衡量模型或特征的稳定性。PSI还是一种主要的模型监控指标。因为模型部署上线后,模型的拒绝率越高,其线上KS值越低,也就越无法体现模型的真实效果,所以通常使用PSI监控线上模型与线下模型的差异,从侧面展示模型真实效果与预期效果的偏差。
PSI的计算中同样涉及分箱,实践证明,等频分箱的效果要好于等距分箱,因此本书中PSI的计算使用等频分箱,即首先在参照分布(训练集)上等频分箱,然后计算测试集与时间外样本集,相比于参照分布的PSI。
def slovePSI(self, model, dev_x, val_x):
dev_predict_y = [s[1] for s in model.predict_proba(dev_x)]
dev_nrows = dev_x.shape[0]
dev_predict_y.sort()
#等频分箱成10份
cutpoint = [-100] + [dev_predict_y[int(dev_nrows/10*i)]
for i in range(1, 10)] + [100]
cutpoint = list(set(cutpoint))
cutpoint.sort()
val_predict_y = [s[1] for s in list(model.predict_proba(val_x))]
val_nrows = val_x.shape[0]
PSI = 0
#每一箱之间分别计算PSI
for i in range(len(cutpoint)-1):
start_point, end_point = cutpoint[i], cutpoint[i+1]
dev_cnt = [p for p in dev_predict_y
if start_point <= p < end_point]
dev_ratio = len(dev_cnt) / dev_nrows + 1e-10
val_cnt = [p for p in val_predict_y
if start_point <= p < end_point]
val_ratio = len(val_cnt) / val_nrows + 1e-10
psi = (dev_ratio - val_ratio) * math.log(dev_ratio/val_ratio)
PSI += psi
return PSI 1.4.3 迭代特征筛选
因为风控建模本身是一种极度不平衡的场景,需要使用一些方法对模型进行调优。这部分在后续章节中进行介绍。本方案中的样本权重weight与代价敏感学习中的权重作用并不相同。考虑到通常建模中会对样本进行抽样,为了反映真实场景下的KS值和PSI,需要使用采样比例的倒数作为权重,进行样本量还原。因此本方案中权重只参与KS值和PSI的计算,不参与模型训练。
本初步筛选方案的精华在于,使用min_score参数控制每一次删除的特征重要性,使用max_del_var_nums控制每一次循环删除特征的个数。这在一定程度上避免了特征之间的干扰。
除了基于模型贡献度的筛选方式外,业务同样需要模型具备一定的稳定性。因为信用评分模型的稳定性很大程度上取决于模型中每个变量分布的稳定性,为保证模型上线后的稳定性,需要对模型中稳定性较差的变量进行筛选。在传统评分卡中,通常还会根据三个建模数据集上每一个特征的信息值(Information Value,IV)、最大信息系数(Maximal Information Coefficient,MIC)、PSI等指标对特征进行筛选(PSI既可用于模型评价又可用于特征筛选,当单变量PSI值大于0.02时,需要对该 特征做调整或者直接删除此特征)。XGBoost模型中同样可以使用这些方法。
需要注意的是,IV通常用于衡量单特征对区分任务的贡献程度,并不考虑特征的组合效果。因此在XGBoost这种具备特征交叉能力的模型中,IV值通常只用于粗筛选。
import xgboost as xgb
from xgboost import plot_importance
class xgBoost(object):
def __init__(self, datasets, uid, dep, weight,
var_names, params, max_del_var_nums=0):
self.datasets = datasets
#样本唯一标识,不参与建模
self.uid = uid
#二分类标签
self.dep = dep
#样本权重
self.weight = weight
#特征列表
self.var_names = var_names
#参数字典,未指定字段使用默认值
self.params = params
#单次迭代最多删除特征的个数
self.max_del_var_nums = max_del_var_nums
self.row_num = 0
self.col_num = 0
def training(self, min_score=0.0001, modelfile="", output_scores=list()):
lis = self.var_names[:]
dev_data = self.datasets.get("dev", "") #训练集
val_data = self.datasets.get("val", "") #测试集
off_data = self.datasets.get("off", "") #跨时间验证集
#从字典中查找参数值,没有则使用第二项作为默认值
model = xgb.XGBClassifier(
learning_rate=self.params.get("learning_rate", 0.1),
n_estimators=self.params.get("n_estimators", 100),
max_depth=self.params.get("max_depth", 3),
min_child_weight=self.params.get("min_child_weight", 1),subsample=self.params.get("subsample", 1),
objective=self.params.get("objective",
"binary:logistic"),
nthread=self.params.get("nthread", 10),
scale_pos_weight=self.params.get("scale_pos_weight", 1),
random_state=0,
n_jobs=self.params.get("n_jobs", 10),
reg_lambda=self.params.get("reg_lambda", 1),
missing=self.params.get("missing", None) )
while len(lis) > 0:
#模型训练
model.fit(X=dev_data[self.var_names], y=dev_data[self.dep])
#得到特征重要性
scores = model.feature_importances_
#清空字典
lis.clear()
'''
当特征重要性小于预设值时,
将特征放入待删除列表。
当列表长度超过预设最大值时,跳出循环。
即一次只删除限定个数的特征。
'''
for (idx, var_name) in enumerate(self.var_names):
#小于特征重要性预设值则放入列表
if scores[idx] < min_score:
lis.append(var_name)
#达到预设单次最大特征删除个数则停止本次循环
if len(lis) >= self.max_del_var_nums:
break
#训练集KS
devks = self.sloveKS(model, dev_data[self.var_names],
dev_data[self.dep], dev_data[self.weight])
#初始化ks值和PSI
valks, offks, valpsi, offpsi = 0.0, 0.0, 0.0, 0.0
#测试集KS和PSI
if not isinstance(val_data, str):
valks = self.sloveKS(model,
val_data[self.var_names],
val_data[self.dep],
val_data[self.weight])
valpsi = self.slovePSI(model,
dev_data[self.var_names],
val_data[self.var_names])
#跨时间验证集KS和PSI
if not isinstance(off_data, str):
offks = self.sloveKS(model,
off_data[self.var_names],
off_data[self.dep],
off_data[self.weight])
offpsi = self.slovePSI(model,
dev_data[self.var_names],
off_data[self.var_names])
#将三个数据集的KS和PSI放入字典
dic = {"devks": float(devks),
"valks": float(valks),
"offks": offks,
"valpsi": float(valpsi),
"offpsi": offpsi}
print("del var: ", len(self.var_names),
"-->", len(self.var_names) - len(lis),
"ks: ", dic, ",".join(lis))
self.var_names = [var_name for var_name in self.var_names if var_name not in lis]
plot_importance(model)
#重新训练,准备进入下一循环
model = xgb.XGBClassifier(
learning_rate=self.params.get("learning_rate", 0.1),
n_estimators=self.params.get("n_estimators", 100),
max_depth=self.params.get("max_depth", 3),
min_child_weight=self.params.get("min_child_weight",1),
subsample=self.params.get("subsample", 1),
objective=self.params.get("objective",
"binary:logistic"),
nthread=self.params.get("nthread", 10),
scale_pos_weight=self.params.get("scale_pos_weight",1),
random_state=0,
n_jobs=self.params.get("n_jobs", 10),
reg_lambda=self.params.get("reg_lambda", 1),
missing=self.params.get("missing", None)) 1.4.4 自动化调参
业内普遍使用的调参策略是基于随机搜索、遗传算法、贝叶斯优化等形式实现的,本节则介绍一种基于业务指标实现调参的思路,并通过代码实现自动化的参数搜索。
注意,本节中的函数均建立在上一步中的xgBoost类之下,代码中的self均指代由父类xgBoost定义的self。
1.4.4.1 自动化调参策略
业务期望模型的训练集KS值和时间外样本集KS值足够接近,且时间外样本集的KS值足够大。前者用于保证模型的跨时间稳定性不会很差,而后者用于保证模型的精度足够高。因此给出调参目标为两者的组合。
def target_value(self,old_devks,old_offks,target,devks,offks,w=0.2):
'''
如果参数设置为"best",使用最优调参策略,
否则使用跨时间测试集KS最大策略。
'''
if target == "best":
return offks-abs(devks-offks)*w
else:
return offks 注意,KS值的分配权重w可以根据实际情况进行调节。比如当业务稳定性较差时,应更多关注两者KS值的差值,因此需要将w从默认的0.2改为一个更大的值。
1.4.4.2 参数搜索方案
参数搜索方案使用的是一种针对目标KS值的贪心搜索方法。每一次只考虑单个参数,进行前向和后向搜索,当对目标KS值有提高时,继续搜索,否则停止该方向的搜索。
def check_params(self, dev_data, off_data, params, param, train_number, step, target,
targetks, old_devks, old_offks):
'''
当前向搜索对调参策略有提升时,
继续前向搜索。
否则进行后向搜索
'''
while True:
try:
if params[param] + step > 0:
params[param] += step
model = xgb.XGBClassifier(
max_depth=params.get("max_depth", 3),
learning_rate=params.get("learning_rate", 0.05),
n_estimators=params.get("n_estimators", 100),
min_child_weight=params.get(
"min_child_weight", 1),
subsample=params.get("subsample", 1),
scale_pos_weight=params.get(
"scale_pos_weight", 1),
nthread=10,n_jobs=10, random_state=0)
model.fit(dev_data[self.var_names],
dev_data[self.dep],
dev_data[self.weight])
devks = self.sloveKS(model,
dev_data[self.var_names],
dev_data[self.dep],
dev_data[self.weight])
offks = self.sloveKS(model,
off_data[self.var_names],
off_data[self.dep],
off_data[self.weight])
train_number += 1
targetks_n = self.target_value(
old_devks=old_devks,
old_offks=old_offks,
target=target,
devks=devks,
offks=offks)
if targetks < targetks_n:
targetks = targetks_n
old_devks = devks
old_offks = offks
else:
break
else:
break
except:
break
params[param] -= step
return params, targetks, train_number
def auto_choose_params(self, target="offks"):
"""
"mzh1": offks + (offks - devks) * 0.2 最大化
"mzh2": (offks + (offks - devks) * 0.2)**2 最大化
其余取值均使用跨时间测试集offks 最大化
当业务稳定性较差时,应将0.2改为更大的值
"""
dev_data = self.datasets.get("dev", "")
off_data = self.datasets.get("off", "")
#设置参数初始位置
params = {
"max_depth": 5,
"learning_rate": 0.09,
"n_estimators": 120,
"min_child_weight": 50,
"subsample": 1,
"scale_pos_weight": 1,
"reg_lambda": 21
}
model = xgb.XGBClassifier(max_depth=params.get("max_depth", 3),
learning_rate=params.get("learning_rate", 0.05),
n_estimators=params.get("n_estimators", 100),
min_child_weight=params.get("min_child_weight",1),
subsample=params.get("subsample", 1),
scale_pos_weight=params.get("scale_pos_weight",1),
reg_lambda=params.get("reg_lambda", 1),
nthread=8, n_jobs=8, random_state=7)
model.fit(dev_data[self.var_names],
dev_data[self.dep],
dev_data[self.weight])
devks = self.sloveKS(model,
dev_data[self.var_names],
dev_data[self.dep],
dev_data[self.weight])
offks = self.sloveKS(model,
off_data[self.var_names],
off_data[self.dep],
off_data[self.weight])
train_number = 0
#设置调参步长
dic = {
"learning_rate": [0.05, -0.05],
"max_depth": [1, -1],
"n_estimators": [20, 5, -5, -20],
"min_child_weight": [20, 5, -5, -20],
"subsample": [0.05, -0.05],
"scale_pos_weight": [20, 5, -5, -20],
"reg_lambda": [10, -10]
}
#启用调参策略
targetks = self.target_value(old_devks=devks,
old_offks=offks, target=target,
devks=devks, offks=offks)
old_devks = devks
old_offks = offks
#按照参数字典,双向搜索最优参数
while True:
targetks_lis = []
for (key, values) in dic.items():
for v in values:
if v + params[key] > 0:
params, targetks, train_number = \
self.check_params(dev_data,
off_data, params,
key, train_number,
v, target, targetks,
old_devks, old_offks)
targetks_n = self.target_value(
old_devks=old_devks,
old_offks=old_offks,
target=target,
devks=devks, offks=offks)
if targetks < targetks_n:
old_devks = devks
old_offks = offks
targetks_lis.append(targetks)
if not targetks_lis:
break
print("Best params: ", params)
model = xgb.XGBClassifier(max_depth=params.get("max_depth", 3),
learning_rate=params.get("learning_rate", 0.05),
n_estimators=params.get("n_estimators", 100),
min_child_weight=params.get("min_child_weight",1),
subsample=params.get("subsample", 1),
scale_pos_weight=params.get("scale_pos_weight",1),
reg_lambda=params.get("reg_lambda", 1),
nthread=10, n_jobs=10, random_state=0)
model.fit(dev_data[self.var_names],
dev_data[self.dep], dev_data[self.weight]) def auto_delete_vars(self):
dev_data = self.datasets.get("dev", "")
off_data = self.datasets.get("off", "")
params = self.params
model = xgb.XGBClassifier(max_depth=params.get("max_depth", 3),
learning_rate=params.get("learning_rate", 0.05),
n_estimators=params.get("n_estimators", 100),
min_child_weight=params.get("min_child_weight",1),
subsample=params.get("subsample", 1),
scale_pos_weight=params.get("scale_pos_weight",1),
reg_lambda=params.get("reg_lambda", 1),
nthread=8, n_jobs=8, random_state=7)
model.fit(dev_data[self.var_names],
dev_data[self.dep], dev_data[self.weight])
offks = self.sloveKS(model, off_data[self.var_names],
off_data[self.dep], off_data[self.weight])
train_number = 0
print("train_number: %s, offks: %s" % (train_number, offks))
del_list = list()
oldks = offks
while True:
bad_ind = True
for var_name in self.var_names:
#遍历每一个特征
model=xgb.XGBClassifier(
max_depth=params.get("max_depth", 3),
learning_rate=params.get("learning_rate",0.05),
n_estimators=params.get("n_estimators", 100),
min_child_weight=params.get("min_child_weight",1),
subsample=params.get("subsample", 1),
scale_pos_weight=params.get("scale_pos_weight",1),
reg_lambda=params.get("reg_lambda", 1),
nthread=10,n_jobs=10,random_state=7)
#将当前特征从模型中去掉
names = [var for var in self.var_names
if var_name != var]
model.fit(dev_data[names], dev_data[self.dep],
dev_data[self.weight])
train_number += 1
offks = self.sloveKS(model, off_data[names],
off_data[self.dep], off_data[self.weight])
'''
比较KS是否有提升,
如果有提升或者武明显变化,
则可以将特征去掉
'''
if offks >= oldks:
oldks = offks
bad_ind = False
del_list.append(var_name)
self.var_names = names
else:
continue
if bad_ind:
break
print("(End) train_n: %s, offks: %s del_list_vars: %s"
% (train_number, offks, del_list)) 2. 模型训练
import xgboost as xgb
data = pd.read_csv(r'G:\02_金融风控\数据集\02_A卡数据集\Acard.txt')
df_train = data[data.obs_mth != '2018-11-30'].reset_index().copy()
val = data[data.obs_mth == '2018-11-30'].reset_index().copy()
lst = ['person_info','finance_info','credit_info','act_info']
train = data[data.obs_mth != '2018-11-30'].reset_index().copy()
evl = data[data.obs_mth == '2018-11-30'].reset_index().copy()
x = train[lst]
y = train['bad_ind']
evl_x = evl[lst]
evl_y = evl['bad_ind']
#定义XGB函数
def XGB_test(train_x,train_y,test_x,test_y):
from multiprocessing import cpu_count
clf = xgb.XGBClassifier(
boosting_type='gbdt', num_leaves=31,
reg_Ap=0.0, reg_lambda=1,
max_depth=2, n_estimators=800,
max_features = 140,
subsample=0.7, colsample_bytree=0.7, subsample_freq=1,
learning_rate=0.05, min_child_weight=50,
random_state=None,n_jobs=cpu_count()-1,
num_iterations = 800 #迭代次数
)
clf.fit(train_x, train_y,eval_set=[(train_x, train_y),(test_x,test_y)],
eval_metric='auc',early_stopping_rounds=100)
return clf
#模型训练
xgb_model= XGB_test(x,y,evl_x,evl_y) 3.模型检验
3.1 KS、AUC
#训练集预测并计算KS
y_pred = xgb_model.predict_proba(x)[:,1]
fpr_xgb_train,tpr_xgb_train,_ = roc_curve(y,y_pred)
train_ks = abs(fpr_xgb_train - tpr_xgb_train).max()
print('train_ks : ',train_ks)
#跨时间验证集预测并计算KS
y_pred = xgb_model.predict_proba(evl_x)[:,1]
fpr_xgb,tpr_xgb,_ = roc_curve(evl_y,y_pred)
evl_ks = abs(fpr_xgb - tpr_xgb).max()
print('evl_ks : ',evl_ks)
#画出ROC曲线
from matplotlib import pyplot as plt
plt.plot(fpr_xgb_train,tpr_xgb_train,label = 'train LR')
plt.plot(fpr_xgb,tpr_xgb,label = 'evl LR')
plt.plot([0,1],[0,1],'k--')
plt.xlabel('False positive rate')
plt.ylabel('True positive rate')
plt.title('ROC Curve')
plt.legend(loc = 'best')
plt.show()
# 计算AUC
print ("AUC Score (Testing): %.3g" % metrics.roc_auc_score(val_y,y_pred))3.1 生成模型报告
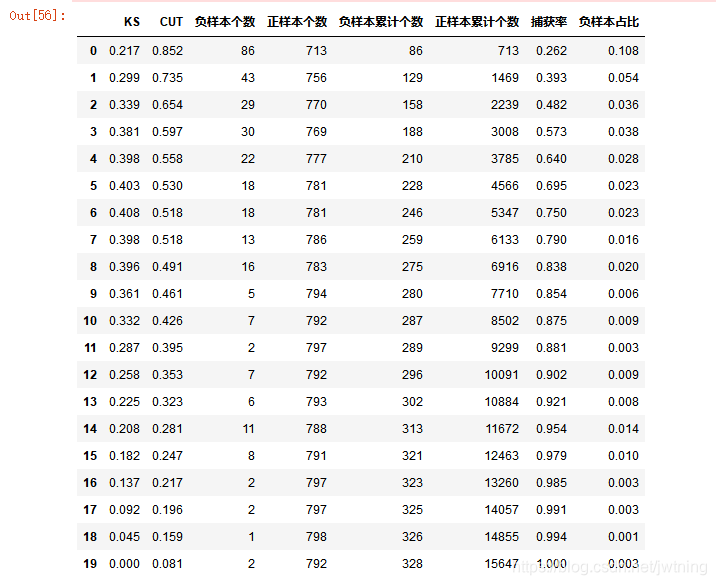
- 模型报告所需字段:KS值、负样本个数、正样本个数、负样本累计个数、正样本累计个数、捕获率、负样本占比
- KS值取得最大值的箱越靠前,表示该模型越好
- 负样本占比一般呈递减趋势,如果出现波动的箱编码越靠前,说明模型的排序能力越弱
model = lr_model
bins = 20 # 分成20个箱子
Y_predict = model.predict_proba(val_x)[:,1]
Y = val_y
lis = list(zip(Y_predict,Y)) # 打包为元组,再转为列表
ks_lis = sorted(lis, key=lambda x: x[0], reverse=True) # 按照预测概率进行排序,倒序
nrows = Y.shape[0] #计算总共有多少个样本
bin_num = int(nrows/bins+1) # 计算每组的样本数量,int()向下取整
bad = sum(val_y) # 统计总样本集中的负样本数量
good = sum([1 for (p, y) in ks_lis if y == 0]) # 统计总样本集中的正样本数量
bad_cnt, good_cnt = 0, 0
KS = []
CUT = [] # 阈值
BAD = []
GOOD = []
BAD_CNT = [] #累计负样本
GOOD_CNT = [] #累计正样本
BAD_PCTG = []
BADRATE = []
dct_report = {}
for i in range(bins):
ds = ks_lis[i*bin_num: min((i+1)*bin_num, nrows)] # 对原数据进行切片,分为bins个组
cut = round(ks_lis[min((i+1)*bin_num, nrows)-1][0],3) # 阈值,概率大于此阈值则预测为1
bad1 = sum([1 for (p, y) in ds if y == 1]) # 统计分组中的负样本数量
good1 = sum([1 for (p, y) in ds if y == 0]) # 统计分组中的正样本数量
bad_cnt += bad1
good_cnt += good1
bad_pctg = round(bad_cnt/bad,3) # 捕获率,当前箱的负样本累计个数除以负样本总数
badrate = round(bad1/(bad1+good1),3) # 负样本占比,当前箱的负样本数量除以当前箱样本数量
#KS值,每个分组中,累计负样本占所有负样本的比例 - 累计正样本占所有正样本的比例,再取绝对值
ks = round(abs((bad_cnt / bad) - (good_cnt / good)),3)
KS.append(ks)
CUT.append(cut)
BAD.append(bad1)
GOOD.append(good1)
BAD_CNT.append(bad_cnt)
GOOD_CNT.append(good_cnt)
BAD_PCTG.append(bad_pctg)
BADRATE.append(badrate)
dct_report['KS'] = KS
dct_report['CUT'] = CUT
dct_report['负样本个数'] = BAD
dct_report['正样本个数'] = GOOD
dct_report['负样本累计个数'] = BAD_CNT
dct_report['正样本累计个数'] = GOOD_CNT
dct_report['捕获率'] = BAD_PCTG
dct_report['负样本占比'] = BADRATE
val_report = pd.DataFrame(dct_report)
val_report结果:
from pyecharts.charts import *
from pyecharts import options as opts
from pylab import *
mpl.rcParams['font.sans-serif'] = ['SimHei']
np.set_printoptions(suppress=True)
pd.set_option('display.unicode.ambiguous_as_wide', True)
pd.set_option('display.unicode.east_asian_width', True)
line = (
Line()
.add_xaxis(list(val_repot.index))
.add_yaxis(
"分组坏人占比",
list(val_repot.负样本占比),
yaxis_index=0,
color="red",
)
.set_global_opts(
title_opts=opts.TitleOpts(title="行为评分卡模型表现"),
)
.extend_axis(
yaxis=opts.AxisOpts(
name="累计坏人占比",
type_="value",
min_=0,
max_=0.5,
position="right",
axisline_opts=opts.AxisLineOpts(
linestyle_opts=opts.LineStyleOpts(color="red")
),
axislabel_opts=opts.LabelOpts(formatter="{value}"),
)
)
.add_xaxis(list(val_repot.index))
.add_yaxis(
"KS",
list(val_repot['KS']),
yaxis_index=1,
color="blue",
label_opts=opts.LabelOpts(is_show=1),
)
)
line.render_notebook() 结果:

4.映射分数
# 生成分数,并计算基于分数的ks
def score(pred):
score = 600+50*(math.log2((1- pred)/ pred))
return score
evl['xbeta'] = model.predict_proba(evl_x)[:,1]
evl['score'] = evl.apply(lambda x : score(x.xbeta) ,axis=1)
evl.head()
fpr_lr,tpr_lr,_ = roc_curve(evl_y,evl['score'])
evl_ks = abs(fpr_lr - tpr_lr).max()
print('val_ks : ',evl_ks) 
















 921
921

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









