







项目背景
拍拍贷“魔镜风控系统”基于400多个数据维度来对当前用户的信用状态进行评估,通过历史数据每个借款人的性别、年龄、籍贯、学历信息、通讯方式、网站登录信息、第三方时间信息等用户信息以及对应的分类标签,在此基础上结合新发标的用户信息,得到用户六个月内逾期率的预测,为金融平台提供关键的决策支持。数据格式
数据下载–点这里
这里面包含三期数据,每期数据内容和格式相同,这里面包括两部分信息:
一部分是Master
PPD_dat_1.csv
PPD_dat_2.csv
PPD_dat_3.csv
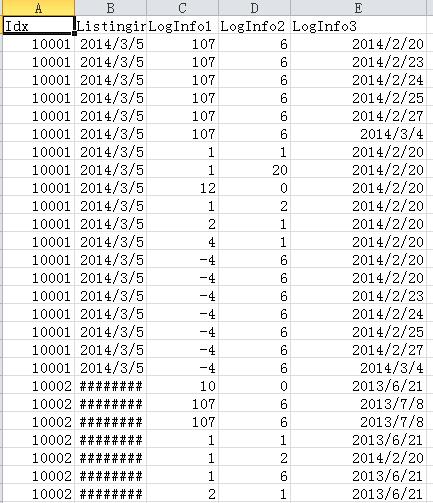
一部分是Log info
PPD_daht_1_LogInfo.csv PPD_daht_2_LogInfo.csv PPD_daht_3_LogInfo.csv
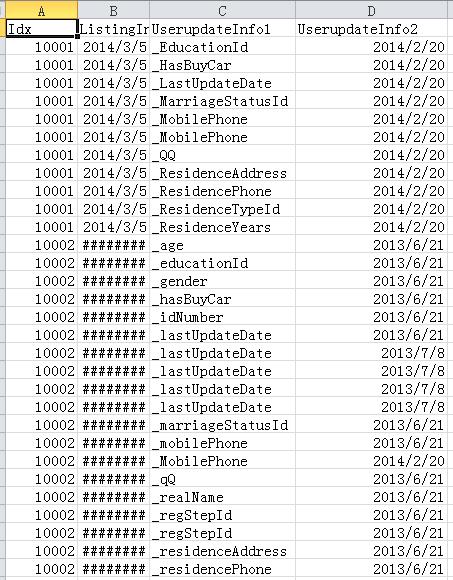
一部分是Update info
PPD_daht_1_Userupdate.csv
PPD_daht_2_Userupdate.csv
PPD_daht_3_Userupdate.csv

3. 问题思路
数据清洗
- 对数据的合并:要把几次的数据合并到一起;要把主表和日志表合并在一起;要把训练集和测试集合并在一起。
- 对字符空格的转换:存在着汉字和英文字符,需要转换成数值形式;存在着数据表达不统一的情况,比如北京和北京市,QQ和Qq,以及多空格等情况。
- 对LogInfo与UserupdateInfo 日期信息的处理等:历史记录相对于主表的主要差异在于对于每个index的各项信息,主表是按列汇总,而历史记录是按行堆叠,因此将历史记录按index 分组,将各行信息汇总到各列上,使得各个index 对应唯一一行以与主表连接。此外,对每笔贷款的历史记录中的时间信息,通常其起始时间和登陆/更新信息的总频率对衡量借款人的行为较为重要。
数据摘要
- 它的作用是简化并理解数据特征,主要包括了变量的类型、变量空值/非空值数据、变量频数前五的值与对应数量、其他值的数量、数字变量的统计量(均值、方差、四分位数)
特征工程
- 数值特征的保留与非数值特征的转换:有额外信息的非数值变量转化为对应的数值:时间–>年月日周、相对天数,地名–>经纬度和城市等级,定序变量–>序数;其他非数值变量全部0-1哑变量处理。
- 选取统计量概况一系列相似变量:取中位数、方差、求和、最值、空值树等概况各时期第三方信息、几个城市变量信息等,统计量尽量要相互独立
- 删
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









