







标题来自李宏毅对Transformer的讲解。。。
seq2seq模型
序列到序列模型,顾名思义就是一个序列生成另一个序列。由编码器和解码器组成,其中编码器会把信息转换为一个向量(上下文context)。整个序列处理完后编码器把context发送给解码器,解码器再逐项生成输入序列中的元素。
Transformer也算是基于这样的编码器-解码器结构,故了解这个模型蛮重要的。
RNN循环神经网络和注意力机制
又是一个老是出现但是一直不太了解的概念。
如果普通的含单隐藏层的多层感知机的隐藏层输出H为下式:
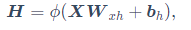
对于含隐藏状态的循环神经网络来说就是下式:
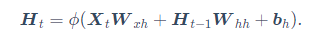
最大区别就是引入了上一时间步的隐藏变量(怕以后不知道啥意思,就是输入输出中间层的输出)。
这里理解一下时间步:举例说,模型处理一个语句是一个一个单词处理的,每个单词进编码器的步骤可称为一个时间步,同理解码器吐出单词也是一个一个时间步吐。。。
这里接着讲注意力机制。注意力机制应用于解码器产生输出之前,而解码器的注意力机制步骤为:
1、查看所有接收到的编码器的 hidden state(隐藏层状态)。其中,编码器中每个 hidden state(隐藏层状态)都对应到输入句子中一个单词。
2、给每个 hidden state(隐藏层状态)一个分数(我们先忽略这个分数的计算过程)。
3、将每个 hidden state(隐藏层状态)乘以经过 softmax 的对应的分数,从而,高分对应的 hidden state(隐藏层状态)会被放大,而低分对应的 hidden state(隐藏层状态)会被缩小。
拆解Transformer
先上个总图:

看这个是真滴难看明白。。。所以先看下面这个图


直接放图,宏观上Transformer也是由编码器-解码器这样两部分组成,论文中用了各六层。其中解码器比编码器多了一层Encoder-Decoder Attention 层,这个层能帮助解码器聚焦于输入句子的相关部分(类似于 seq2seq 模型 中的 Attention)。
流程:进入输入(note:编码器和解码器都有,且都是embedding+positional embedding)然后走过层层编码器,到达解码器,从解码器出来后经过个线性层+softmax层
编码器的细节:编码器的每个子层(Self Attention 层和 FFNN)都有一个残差连接和层标准化(layer-normalization)。

embedding,把词汇处理成向量。。。对应图片呢=-=?
再补一个位置编码(positional embedding),实在没太整明白具体的编码规则。。。总之,这个东西是用来表示序列中单词顺序的。这个东西编码器和解码器都有。
Self-attention
个人理解注意力机制概念更大些,包括self-attention啦。
直到开始写总结我才发现self-attention和attention好像不太一样=-=但attention本身就是通过一系列计算提高关注度(或者相关度)
self-attention大体流程:(往下说的都是一个head的attention)
第一步:每个词向量输入编码器后会创建三个向量,即Query 向量,Key 向量,Value 向量。这 3 个向量是词向量分别和 3 个矩阵相乘得到的,而这个矩阵是我们要学习的参数。
第二步:计算attention score,即一个单词向量的Q乘以别的单词向量的K(点积),再除以个数(为了求梯度更加稳定,也不一定是啥数)最后经过softmax层把分数归一化,使这些分数都是正数且加起来为1.
就先这些吧。。。累了。。















 2563
2563











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









