






GAN论文梳理-----来源各大博客
本文目的只是为了快速了解一下GAN的情况
注博客和代码来源:
https://cloud.tencent.com/developer/column/1638
https://blog.csdn.net/weixin_36811328/article/details/88420820
https://blog.csdn.net/qq_37995260/article/details/90510052
等,均在文中有原链接
GAN代码集合:https://github.com/wiseodd/generative-models
DCGAN
核心思想
生成器和判别器全部使用CNN结构
在D网络中,不再用pool操作来实现图片尺寸收缩,而是用stride>1的卷积来实现尺寸收缩;
在G网络中,使用“反卷积”来生成图像
在G和D中都使用BatchNorm
不使用全连接层
在G网络中,使用ReLU,最后一层使用Tanh
在D网络中,使用LeakyReLU

直接转一份比较详细的代码介绍,可以仔细看看
论文地址
原始GAN
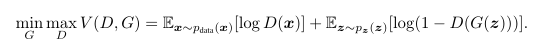
CGAN
核心思想
原始GAN的生成器G学到了数据的分布,生成出来的图片其实是随机的,也就是说这个G的生成过程处于一种没有指导的状态,虽然生成的图片,比如mnist数据集来说,生成的的确是数字,但是却没有具体的说是什么数字。 cGAN相当于在原始GAN的基础上加上一个条件:condition,以此来指导G的生成过程。
具体实现
在G和D的输入端都添加条件,则D就相当于多加了一部分信息,从而进行更为具体的判别;G的输入多了一个条件之后,生成的数据也就有了一个具体的方向。
论文链接
pytorch 版本

LSGAN
核心思想: 将损失函数替换为:least squares loss
论文地址
pytorch/tensorflow

对于一些G生成的样本,如果判别器D判定它们为real,在使用传统损失函数sigmoid cross entropy loss的情况下:那么这些样本就不会再得到优化,但使用least squares loss 的情况下,这些图片会继续得到优化,所以生成的图像质量会更高

pix2pix
论文地址
pytorch代码
核心思想
本篇论文的核心思想并不复杂,是借鉴了conditional-GAN的思想。了解cGAN的朋友都清楚,cGAN在输入G网络的时候不光会输入噪音,还会输入一个条件(condition),G网络生成的fake images 会受到具体的condition的影响。
那么现在,如果把一副图像作为condition,则生成的fake images 就与这个condition images有对应关系。
这样一来,就实现了一个Image-to-Image Translation 的过程
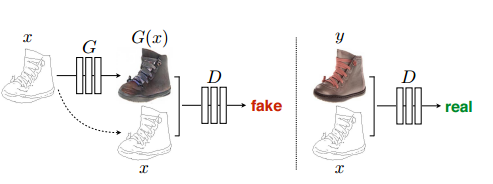
和CGAN的区别:

可以看作CGAN是对噪音进行变换成想要的y,
pix2pix是直接拿想要得到的图像进行变换成新的图
损失函数:
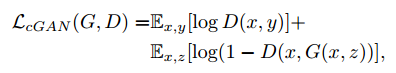
在CGAN的loss上增加了L1距离损失函数
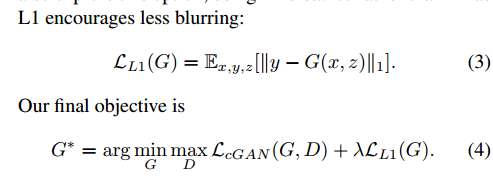
这里的损失函数中,G的输入仍然写的是(x,z),说实话,其实并不用噪音z,
它官方给的代码里,输入都没有噪音z,也就是说,写个G(x)就可以了。

D网络称为Pacth-D. 就是说,最后D网络生成的可以是一个patch(或者说一个矩阵),早期的GAN中,D网络一般就只输出一个数字,0or1,这里输出一个矩阵,矩阵中的元素为0or1,矩阵大小可调节(Patch的大小可以调节)。如图,286指的是原始方法,只有1个数字,对应感受野大小为286286;
11为每个像素都产生一个数字;论文中说明70的效果好,可能是因为286的参数过多更加难训练
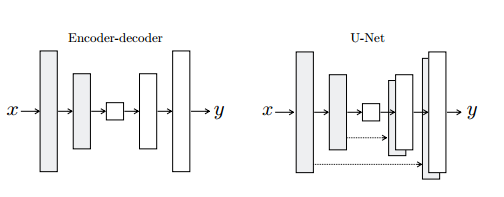
G使用了UNet结构。对称式的端到端结构生成图片
CycleGAN
论文地址
代码地址
核心思想:从X生成Y,再从Y生成回x,如此循环往复,故名为cycleGAN

 左边为pix2pix类型的数据集,需要成对的数据,而右边是cycleGAN的数据集,不需要相匹配的数据集,
左边为pix2pix类型的数据集,需要成对的数据,而右边是cycleGAN的数据集,不需要相匹配的数据集,
x和y没有关系。
损失函数:
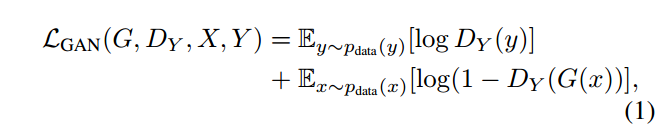
但单纯的使用这一个损失是无法进行训练的。原因在于,映射F完全可以将所有x都映射为Y空间中的同一张图片,使损失无效化。对此,作者又提出了所谓的“循环一致性损失”(cycle consistency loss)。
我们再假设一个映射G,它可以将Y空间中的图片y转换为X中的图片G(y)。CycleGAN同时学习F和G两个映射,并要求 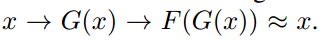 以及
以及 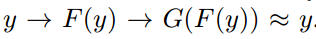 。也就是说,将X的图片转换到Y空间后,应该还可以转换回来。这样就杜绝模型把所有X的图片都转换为Y空间中的同一张图片了。,循环一致性损失就定义为:
。也就是说,将X的图片转换到Y空间后,应该还可以转换回来。这样就杜绝模型把所有X的图片都转换为Y空间中的同一张图片了。,循环一致性损失就定义为:
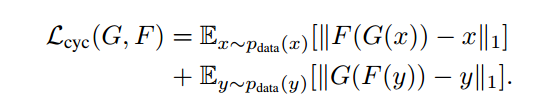
最终的损失:

本来我要从X经过G生成fake_Y,但如果我把Y输入进G呢?它还是应该生成fake_Y,我们可以称为fake_Y2;也就是说,本来生成器G是用来生成Y这种风格的图像的,如果输入本身就是Y,那么就更应该生成Y这个图像了,这就是要让这个生成器G能够做到identity mapping,所以可以计算fake_Y2和输入Y的L1-loss,称之为identity-loss。

CycleGAN的孪生兄弟DiscoGAN, DualGAN
本节参考:https://blog.csdn.net/qq_37995260/article/details/90510052
DiscoGAN
论文地址
pytorch代码

(a)是我们理想的映射,一对一的;(b)是原始GAN的结果,A中的多个模式映射到了B中的一个模式,就是模式崩溃的情况;©是加入了重建损失的GAN,A中两个模式的数据都映射到了B中的一个模式,而B中一个模式的数据只能映射到A中这两个模式中的一个。重建损失使得模型在©中的两个状态之间震荡,而并不能解决模式崩溃问题。
对(c)的解释:当出现模式崩溃时,重建损失强制要求重建样本和原来的样本一样,所以会在DomainA中两个模式之间震荡。

基于在二维A和B域中合成数据的演示实验, 源与靶都是从高斯混合模型中提取数据样本。
任务是发现A和B域之间的跨域关系,并将样本从五个A域模式转换成B域,该B域围绕圆弧展开十种模式。(5种颜色表示5个A域,10个黑叉表示10个B域,有色背景显示了D的输出值。)
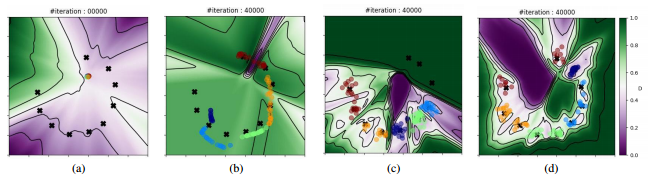
(a)生成器初始化,所以可以看到五种颜色重叠于一点
(b)普通GAN,多个颜色映射到不同B中,各种重叠,模式崩溃
(c)重构GAN, 效果好了点奥,可以看到还是有点重叠,而且有些黑x没被映射到
(d)discoGAN, 作者的模型效果不用说,都映射到了
DualGAN
论文地址
代码

这篇文章的灵感来源是Xia et al 提出的一篇做机器翻译的文章NIP Dual。这篇文章的一个例子很好的解释了对偶的思想。首先假设我们有两个人A和B,A会英文不会法语,B会法语不会英文。A要和B进行交流,A写了一段话,通过翻译器GA翻译成法语,但A看不懂法语,只能将翻译的结果直接发给B;B收到这段话之后,用自己的理解整理了一下,通过翻译器GB翻译成英文直接发给A;A收到之后,要检查B是否真正理解自己说的话。如此往复几次,A和B都能确认对方理解了自己。在这个例子中,翻译器A和B分别是两个生成器,A和B分别担任了判别器的角色。
BiGAN(与ALI类似)
BIGAN论文
ALI
代码
VAE和GAN都是常见的生成式模型,对于VAE结构:image1输入到encoder中,产生输出vector,这个vector再输入到decoder中产生image2,然后最小化重构误差||image1-image2||;对于GAN:优化目标是判别器D的输出,而输入是真实图片和随机采样噪声经过G生成的虚假图片。
而BiGAN则结合编解码器结构和判别器结构提出了一种新的优化思路:
输入image x(x是数据集中的真实图片),经过编码器E得到E(x)
从某个分布(如高斯分布、均匀分布等)中采样随机噪声z,经过解码器G得到G(z)
通过上述两步,我们可以得到一系列(x, E(x))和(G(z), z),前者是Encoder产生的,后者是Generator产生的,将这些结果输入到Discriminator中,让它判断是E还是G产生的;如果D不能准确判断,那么就成功了。

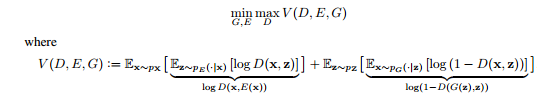
BiGAN 使得 GAN 具有了学习有意义的特征表示的能力。原始 GAN 中,D 接收样本作为输入, 并将其习得的中间表示作为相关任务的特征表示, 没有其他的机制。它对于生成数据与真实数据的语义上有意义的特征并不十分清晰。当 G 生成了真实数据时,D 只能预测生成数据(图片)的真实性,但是无法学习有意义的中间表示。BiGAN 就是希望让 GAN 能够具备表征学习能力。
SAGAN
论文
代码


在目前的图像生成模型中,一般很难处理好细节和整体的权衡
可能原因:
对此的一种可能解释是先前的模型严重依赖于卷积来模拟不同图像区域之间的依赖性。由于卷积运算符具有局部感受域,因此只能在经过多个卷积层之后处理长距离依赖性(long-range dependency)。这可能会因各种原因阻止学习长期依赖性:
(1)小型模型可能无法找到他们之间的依赖关系;
(2)优化算法可能无法发现仔细协调多个层以捕获这些依赖性的参数值;
(3)增加卷积核的大小可以增加网络的表示能力,但是又会丧失卷积网络的参数和计算效率。
解决办法-即SAGAN的优点:
self-attention 在模拟远程依赖性的能力、计算效率和统计效率之间展现出更好的平衡。自我关注模块将所有位置处的特征的加权和作为该位置的响应,其中权重 - 或注意向量 - 仅以较小的计算成本来计算。
我们提出了自我注意生成对抗网络(SAGAN),它将self-attention机制引入卷积GAN。
(1)可以很好的处理长范围、多层次的依赖(可以很好的发现图像中的依赖关系)
(2)生成图像时每一个位置的细节和远端的细节协调好
(3)判别器还可以更准确地对全局图像结构实施复杂的几何约束。
过程:
(1)f(x),g(x)和h(x)都是普通的1x1卷积,差别只在于输出通道大小不同;
(2)将f(x)的输出转置,并和g(x)的输出相乘,再经过softmax归一化得到一个Attention Map;
(3)将得到的Attention Map和h(x)逐像素点相乘,得到自适应的注意力feature maps.
稳定GAN的一些Tricks
- Spectral Normalization
SA-GAN将Spectral Normalization应用到了G和D中,稳定了训练和生成过程。 - Imbanlanced Learning Rate
在训练过程中,给予G和D不同的学习速率,以平衡两者的训练速度。
WGAN和SNGAN
原生 GAN 的目标函数等价于优化生成数据的分布 Pg和真实数据的分布Pr之间的 J-S 散度 (Jensen–Shannon Divergence)。在但存在的问题是判别器训练越好,生成器梯度消失越严重。关于生成器梯度消失的论证:在(近似)最优判别器下,最小化生成器的loss等价于最小化Pg和真实数据的分布Pr之间的JS散度,而由于Pg和真实数据的分布Pr几乎不可能有不可忽略的重叠,所以无论它们相距多远JS散度都是常数log2,最终导致生成器的梯度(近似)为0,梯度消失。
WGAN使用性质优良的 Wasserstein distance 代替原生 GAN 中的 J-S 散度。 然后利用KR对偶原理将 Wasserstein distance的求解问题转换为求解最优的利普希茨连续函数的问题。
谱归一化(Spectral Normalization)的来源,需要数学知识,我只简单过了一遍,详细参考下面博客:
https://blog.csdn.net/StreamRock/article/details/83590347
https://zhuanlan.zhihu.com/p/63957812
可视化WGAN: https://zhuanlan.zhihu.com/p/31394374
https://www.cnblogs.com/noahzhixiao/p/10171410.html
SNGAN就是对WGAN的改进
StyleGAN(前身ProGAN)
论文
代码
本节详细内容参考:https://blog.csdn.net/a312863063/article/details/88795147(总结非常好的文)
PROGAN中的平滑技术


StyleGAN首先重点关注了ProGAN的生成器网络,它发现,渐进层的一个潜在的好处是,如果使用得当,它们能够控制图像的不同视觉特征。层和分辨率越低,它所影响的特征就越粗糙。简要将这些特征分为三种类型:
1、粗糙的——分辨率不超过8^2,影响姿势、一般发型、面部形状等;
2、中等的——分辨率为162至322,影响更精细的面部特征、发型、眼睛的睁开或是闭合等;
3、高质的——分辨率为642到10242,影响颜色(眼睛、头发和皮肤)和微观特征;
然后,StyleGAN就在ProGAN的生成器的基础上增添了很多附加模块。
详细内容直接点击这里,作者写的很详细,我就不搬过来了
StackGAN(CGAN的改进)
提出了StackGAN,实现了根据描述性文本生成高分辨率图像
提出了一种新的条件增强技术,增强训练过程的稳定性、增加生成图像的多样性
通过多个实验证明了整体模型以及部分构件的有效性,为后面的模型构建提供了有益信息
StackGAN将Text-to-Image这项工作分为了两个阶段来执行:
Stage-I GAN:根据给定的文本描绘出主要的形状和基本颜色组合;并从随机噪声向量中绘制背景布局,生成低分辨率图像
Stage-II GAN:修正第一阶段生成的低分辨率图像中的不足之处,再添加一些细节部分,生成高分辨率图像

那么为什么这样两阶段的生成方式可行呢? 作者在文中的Introduction部分给出了一种解释:在高维的像素空间中,真实图像所满足的分布和模型所表示的分布也许没有交叠部分,根据14年的《Generative Adversarial Nets》可以知道,如果两个分布之间没有交叠的部分,那么就无法通过最小化两个分布的KL散度来训练模型,那么GAN的训练将会很难。而作者认为直接计算真实高分辨率图像所满足的分布和模型表示的分布之间的KL散度也许不容易,那么我们先计算低分辨率图像所满足的分布和模型标识的分布之间的KL散度,它们之间有更大的可能有交叠的部分;而低分辨率图像所满足的分布和高分辨率图像所满足的分布之间也有很大的概率有交叠的部分,这样模型的训练相对就容易一些,同时也可以生成高分辨率的图像。
另一个问题是为什么条件增强技术(Conditional Augmentation)可以实现增加数据流形的平滑性、增强模型的鲁棒性和提高生成图像的多样性呢? 作者认为在实际的训练中,我们能使用的文本-图像配对数据相对较少,那么它们在数据流形上表示就很稀疏,连续性很差,使得模型的训练很难。而使用了CA之后,由于我们不再是从一个个独立的点采样,而是从某个高斯分布中进行采样,这样就使得文本描述相差不多的可以对应同一幅图像,从而增加了文本-图像配对样本的数据量,在一定程度上缓解了流形上的表示的稀疏性,有助于更容易的训练模型。
Improved Techniques for Training GANs
问题描述:生成器和判别器其实是在寻找一个纳什均衡,但梯度下降算法适应于损失函数是一个凸(凹)函数的情况,如果应用梯度下降算法,且生成器和判别器使用同一个目标函数,很有可能是此消彼长此长彼消的情况。
因此为了解决不稳定的情况,作者提出了为生成器寻找另一个目标函数的方法。新的目标函数,利用判别器的中间层的输出,使 得生成图片的特征与真实图片的特征相匹配.直观上判别器的中间层其实是一个特征提取器,用来区别真实图片和生成图片的特征,作者认为这种特征的差异是值得生成器学习的。因此生成器的目标函数为,f(x)表示判别器的中间层的输出。

问题:生成图片单一的一个主要问题在于生成器的参数设置上,也就是说生成器把不同的z映射到了相同的点,当这种情况发生时,判别器由于只单独考虑一个点,所以只会对于这些相似的点,指出相似的优化方向,因此相当于没有考虑点与点之间的相似情况,也不会告诉生成器下一步优化时使得这些点不相似。因此作者提出判别器应该考虑多个点,而不是独立的计算每个点的梯度。具体方法如下:



将f(xi)和o(xi)concat,作为下一层的输入,其他的和原始的GAN是一样的。
提出了:inception score
Progressively Growing GANs
文章
代码
多尺度架构 Multi-Scale Architecture

上图显示了多尺度体系结构的概念。鉴别器用来确定生成的输出是“真实”还是“伪造”的,“真实”图像被下采样到分辨率高达4²,8²等,最高可达1024²。生成器首先生成4²图像,直到达到某种收敛为止,然后任务增加到8²图片,直到1024²。该策略极大地稳定了训练,并且可以想象为什么是相当直观的。从潜伏的z变量直接变为1024²图像,空间中包含大量变化。就像以前的GAN研究的趋势一样,生成低分辨率图像(例如28²灰度MNIST图像)比128²RGB ImageNet图像要容易得多。
Fading in New Layers

小批量标准偏差 Minibatch Standard Deviation
均衡学习率 Equalized Learning Rate
U-GAT-IT
论文
pytorch
CAM & Auxillary classifier

由上图,我们可以看到对于图像经过下采样和残差块得到的 Encoder Feature map 经过 Global average pooling 和 Global max pooling 后得到依托通道数的特征向量。创建可学习参数 weight,经过全连接层压缩到 B×1 维,这里的 B 是 BatchSize,对于图像转换,通常取为 1。
对于学习参数 weight 和 Encoder Feature map 做 multiply(对应位想乘)也就是对于 Encoder Feature map 的每一个通道,我们赋予一个权重,这个权重决定了这一通道对应特征的重要性,这就实现了 Feature map 下的注意力机制。
对于经过全连接得到的 B×1 维,在 average 和 max pooling 下做 concat 后送入分类,做源域和目标域的分类判断,这是个无监督过程,仅仅知道的是源域和目标域,这种二分类问题在 CAM 全局和平均池化下可以实现很好的分类。
当生成器可以很好的区分出源域和目标域输入时在注意力模块下可以帮助模型知道在何处进行密集转换。将 average 和 max 得到的注意力图做 concat,经过一层卷积层还原为输入通道数,便送入 AdaLIN 下进行自适应归一化。
AdaLIN

由上图,完整的 AdaLIN 操作就是上图展示,对于经过 CAM 得到的输出,首先经过 MLP 多层感知机得到 γ,β,在 Adaptive Instance Layer resblock 中,中间就是 AdaLIN 归一化。
AdaLIN 正如图中展示的那样,就是 Instance Normalization 和 Layer Normalization 的结合,学习参数为 ρ,论文作者也是参考自 BIN [3] 设计。AdaIN 的前提是保证通道之间不相关,因为它仅对图像 map 本身做归一化,文中说明 AdaIN 会保留稍多的内容结构,而 LN 则并没有假设通道相关性,它做了全局的归一化,却不能很好的保留内容结构,AdaLIN 的设计正是为了结合 AdaIN 和 LN 的优点。














 1455
1455











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









