







杨立昆是法国计算机科学家 Yann LeCun 的中文名,他任 Meta 首席人工智能科学家和纽约大学教授,他带领 Meta 的团队推出了开源大模型领域 Llama。他与 Yoshua Bengio、Geoffrey Hinton 一同获得2018年的图灵奖。
2024年3月28日,杨立昆在哈佛大学做了一场学术演讲,其中提到了自己关于 AI 的7个观点。

杨立昆在哈佛大学的演讲现场
1.AI 应该能够理解、记忆、推理、规划
动物和人类可以通过尝试和学习,理解世界是如何运作的,他们可以进行推理和规划,他们有常识,这是今天绝大多数 AI 系统做不到的。
尽管硅谷的炒作总是告诉你 AGI 即将到来,但我们实际上并没有那么接近。我们目前拥有的 AI 系统,在一些能力上极其有限。
如果我们有了接近人类智力的系统,我们就会有能够在20小时练习中学会驾驶汽车的系统,就像任何17岁的青少年那样;我们就会有家用机器人,能够一次性学会清理餐桌和清空洗碗机,就像10岁孩子那样。
所以我们漏掉了一些重要的东西。我们应该让 AI 像人类那样学习世界是如何运作的,不仅仅是从文本中学习,还应该从视频或者其他感官输入中学习。
我们需要一个拥有世界模型,拥有记忆,能够推理,能够规划行动的系统,而且它是可控和安全的,这就是目标驱动的 AI。
2. 现在的大模型没有前途
LLM 以及图像识别、语音识别、翻译等,现在 AI 中所有很酷的这些东西,都归功于自监督学习。
它的工作方式是,你拿一段数据,比如一段文本,以某种方式转换或破坏它,比如用空白标记替换其中的一些单词。然后你训练一些巨大的神经网络来预测缺失的单词,这就是 LLM 的训练方式。
它们工作得很好,是因为 LLM 会在数十万亿个 token 上训练,但这种东西会犯愚蠢的错误。它们并不真正理解逻辑,如果你告诉它们 A 和 B 是一回事,它们不一定知道 B 和 A 也是一回事。它们并不真正理解排序关系的传递性以及类似的东西。它们不会做逻辑推理,你必须明确地教它们做算术,或者让它们调用工具来做算术。
它们对底层现实没有任何了解。它们只是在文本上训练。它们只知道语言中包含的知识。但大多数人类知识实际上与语言无关。
它们也真的不能规划,每当它们看似可以规划时,基本上是因为它们训练过类似的规划,它们基本上只是重复一个非常相似的计划。
3.目标驱动的 AI 系统
我们希望 AI 可以做分层规划。
举个例子,假设我坐在纽约大学的办公室里,我想去巴黎。我不会做毫秒级的计划,这是不可能的,因为我不知道将会发生的情况。我是否必须避开一个我还没看到的特定障碍?红绿灯会是红色还是绿色?我要等多久才能打到出租车?所以,我不能从一开始就计划好一切。
但我能做高层规划,我知道我需要到机场,并登机,这是两个宏观动作,对吧?然后再决定较低层次的子目标,我如何到达机场?嗯,我在纽约,所以我需要下楼到街上打车,就是下一层的目标。我如何到达我要去的街道,我必须坐电梯下去,然后走到街上?我如何去电梯?我需要从椅子上站起来,打开办公室的门,走到电梯,按下按钮。
所以你可以想象有这种分层规划在进行。我们完全不费力气就能做到这一点,动物也能很好地做到这一点。今天没有任何 AI 系统能够做到这一点。
所以我设计了目标驱动的 AI 系统,结构如下:
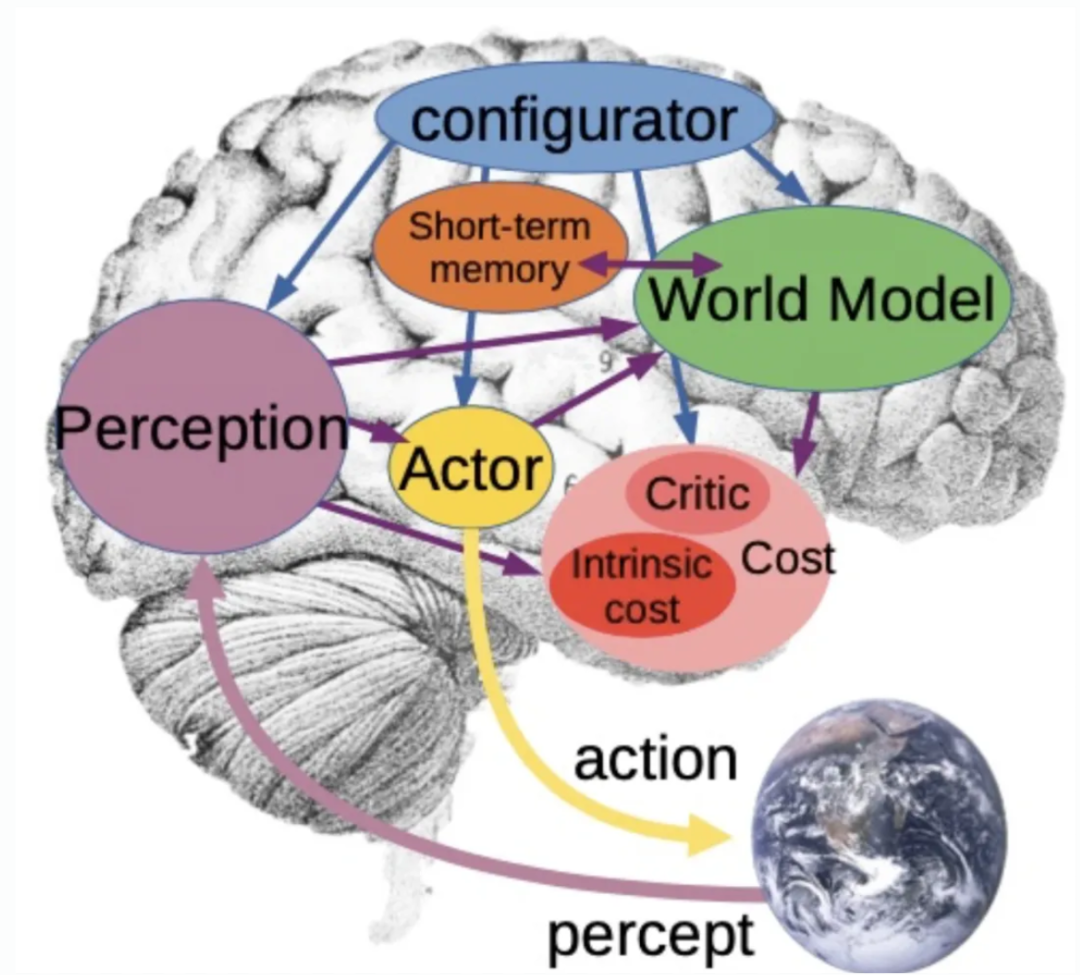
目标驱动 Al 的模块化认知结构
在这个架构中,有一个感知模块,用来观察世界,并将其转化为对世界的表示;有一个持久记忆模块,用来记录事实;有一个世界模型,这是系统的核心;有一个行动模块,一个成本模块,一个配置器。系统的工作方式如下:
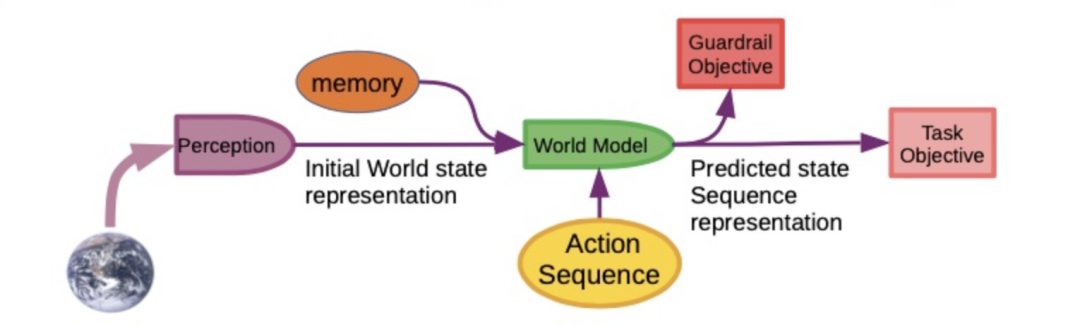
目标驱动 AI 的工作方式
AI 观察世界,将其输入感知系统,产生对当前世界状态的认识,并可能将其与记忆中的内容结合起来,记忆中包含先前观察到的世界状态。世界模型接收当前世界状态,根据输入的行动序列,产生对未来世界状态的预测,并将未来世界状态输入粉色和红色的方框,判断离任务(Task)目标有多远(用户期望的目标),离护栏(Guardrail)目标有多远(保障安全的目标)。
系统将搜寻一个行动序列,以使预测的世界状态满足目标,这与那些多层神经网络有本质的不同。这基本上是一个优化问题,如果这个推理的空间是连续的,我们可以使用基于梯度的方法做反向传播,不断更新行动序列,最后收敛到最优行动序列。
4.世界模型的关键是预测世界
如果要建立这种类型的系统,我们如何构建世界模型?人类或动物是如何做到这点的?
有一个很自然的想法,就是把自监督训练文本的想法移植到视频上:拍一段视频,称之为 y,这是完整视频,然后通过遮盖其中一部分来破坏它,比如说遮盖后半段,产生视频 x,然后训练一些巨大的神经网络,用x来预测缺失的视频部分。
如果系统能预测视频中将要发生的事情,那么,它可能对物理世界的底层本质有很好的认识。
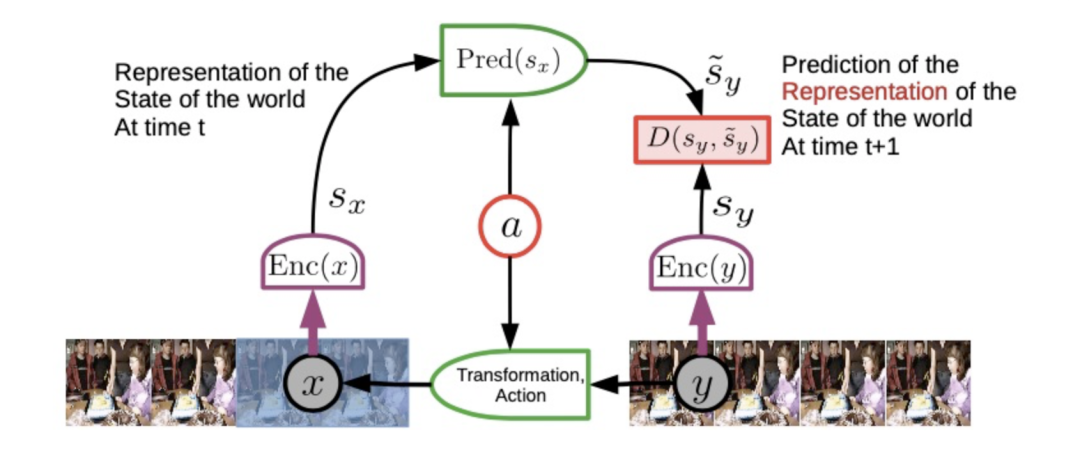
对视频的自监督训练
直接预测像素级别的视频是非常困难的,但我们可以从“x 的表示”重建“y 的表示”,这样,我们不用预测每个像素,而只是预测y的表示。
在上图中,x 是一个观察,sx 是那个观察的表示。a 将是你采取的一个行动(或者你观察到有人在采取行动),然后 sy 是你采取行动后世界状态的表示,对 sy 解码后,y 就是预测的未来世界状态。
我们取一段视频,遮盖后面的部分,告诉其正在采取的动作,要求系统预测将要发生的事情。如果你有这个,你就有了一个世界模型。
如果你有一个世界模型,就可以将其放入规划系统。如果你有一个可以规划的系统,你就可能拥有比当前 AI 更智能的系统,它们可以够规划行动,而不仅仅是词语。
5.只预测你关注的信息
预测图像中缺失的内容非常困难,因为图像中可能有复杂的纹理,诸如此类。
拿这个讲座的视频举例,我把摄像机指向这个方向,慢慢平移,在你前面停下,这时,我们让系统预测视频中接下来会发生什么。
系统可能会预测:平移会继续,会有人坐着,在某个时候会有一面墙。它绝对不可能预测我们任何人长什么样,它也不可能预测楼梯有多少级,它不可能预测墙壁或地毯的精确纹理,对吧?所以这里有各种完全无法预测的细节。
所以做预测的大问题是:什么是适当的信息和适当的抽象层次?然后你消除其他所有东西,如果你把所有资源都花在试图预测那些无关紧要的事情上,你就完全是在浪费时间。
为什么预测图像很困难?因为图像是高维和连续的。而文本是离散的,预测文本就很容易。
语言是很简单的,现实世界是真正困难的。
6.为什么我们需要开源的 AI 平台
AI 系统有偏见是很正常的,因为它们是通过互联网上可用的文本训练的,文本有偏见,系统就必然会有偏见。
每一份期刊、每一份新闻杂志报纸都有偏见。我们解决这个问题的方法是拥有高度多样化的非常不同的杂志和报纸。我们不会从单一系统获取信息,我们可以在各种有偏见的系统之间进行选择。
同样地,我们不会有无偏见的AI系统,我们需要一个开源的 AI 平台,允许任何人根据自己的语言、文化、价值观、兴趣来微调一个开源AI系统,这样,我们就不会从单一的 AI 系统获取信息,我们可以在各种有偏见的 AI 系统之间进行选择。
有些人认为 AI 是危险的,他们说“你不能把 AI 交到每个人手中,它太危险了,你需要监管它”。其实,这更加危险。
强大的 AI 不是一天就能出现的,而是一个渐进的过程。我们需要构建我所描述的这种类型的系统,使它们越来越强大,让它们学习越来越多的东西,设置越来越多的护栏和目标等等,随着它们变得越来越聪明,它们也会变得更加安全可靠和行为良好。
在这个过程中,每个人都可以做出贡献,这就是为什么我们需要开源模型。
7.未来的 AI 很危险吗
达到人类水平的 AI 还需要多长时间?LLM 的支持者说会在明年或今年年底之前,这是扯淡,我认为大概五年内都不会。
有一种想法是,突然间,超级智能系统会在几分钟内接管世界,这完全是荒谬的,世界根本不是这样运作的。
一些智库游说政府相信这种风险,所以政府会组织会议,讨论类似“我们明年都会死光光吗?”这种问题。
所以我们必须先告诉政府,我们离人类级智能还很远,不要相信那些告诉你超级智能就在眼前的人,比如 Elon。
我们可以以无危险的方式构建它们,超级人工智能不会是一个事件,它将是渐进的,我们有办法以安全的方式构建这些东西。
讨论现在的 AI 今后可能存在的风险,是无厘头的,因为未来的 AI 还没有被发明出来,我们不知道它们会是什么样子。
这就像在1925年讨论喷气式客机跨大西洋飞行的安全性,我们知道,喷气发动机在那时还没有被发明出来,而且这不是一天就发生的,对吧?它花了几十年的时间,现在你可以乘坐双引擎喷气式飞机完全安全地飞到地球的另一端,这太神奇了。
AI 也会是同样的事情。
转载自丨卫sir说
作者丨卫剑钒
编辑丨赵政瑛
相关阅读 | Related Reading
专访天谋科技CTO乔嘉林:一个顶级开源项目背后,还需要淬炼多个“最后一公里”
【Deep Dive:AI Webinar】炉边对谈-谁在构建开源人工智能?
【Deep Dive: AI Webinar】即将出台的欧盟人工智能法案中开源监管的观点

开源社简介
开源社(英文名称为“KAIYUANSHE”)成立于 2014 年,是由志愿贡献于开源事业的个人志愿者,依 “贡献、共识、共治” 原则所组成的开源社区。开源社始终维持 “厂商中立、公益、非营利” 的理念,以 “立足中国、贡献全球,推动开源成为新时代的生活方式” 为愿景,以 “开源治理、国际接轨、社区发展、项目孵化” 为使命,旨在共创健康可持续发展的开源生态体系。
开源社积极与支持开源的社区、高校、企业以及政府相关单位紧密合作,同时也是全球开源协议认证组织 - OSI 在中国的首个成员。
自2016年起连续举办中国开源年会(COSCon),持续发布《中国开源年度报告》,联合发起了“中国开源先锋榜”、“中国开源码力榜”等,在海内外产生了广泛的影响力。


















 954
954

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









