







DSSM模型的优化目标是最大化点击文档的概率,该概率计算的计算方式是通过将query和doc的term vector分别映射到语义空间,然后计算每个(Q, D)的余弦相似度,再进行softmax转化成概率。在计算中有两个小点可以注意,一个是softmax函数中的系数gamma(>0),该参数用于平滑,当它大于1时,概率之间的差异会被放大,当它小于1时,概率直接的差异会被缩小;另一个是计算的时候并没有使用所有的文档,而是选取了点击的doc和4个未点击的doc,这个算法类似于word2vec里的negative sampling,用于减小softmax的计算量。
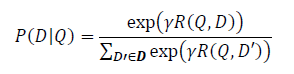
网络的结构比较简单,输入是原始的term vector,第一层将term vector映射为n-gram letter vector,之后是几个全连接层(使用tanh作为激活函数),输出层带激活。
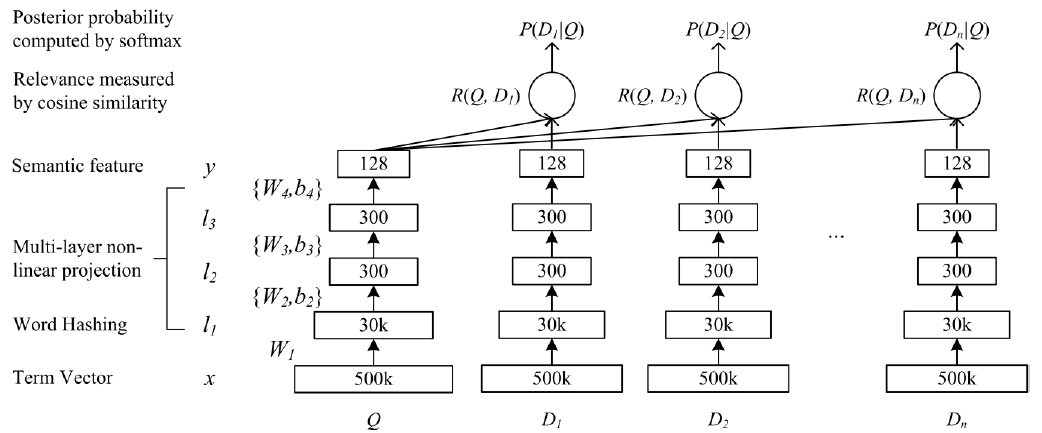
word hashing的好处包括:(1)大大降低维度(2)减少训练集中未出现的词的影响(3)减少词性变化的影响。
作者训练该模型时使用了大小为1024的mini batch,20个epoch之后就训练完成了。并把模型和其他的常用模型进行了比较,包括(1)LSA这样的主题模型(2)无监督学习的自动编码器模型(3)基于词匹配的模型,如tf-idf,比较了NDCG指标以及pair t test显著性,DSSM指标显著高于其他模型。
DSSM的优势体现在三方面:(1)直接训练搜索目标,而不是像自动编码器那些学习无监督的目标(2)使用深度模型,能更好的提取语义特征(3)使用word hashing,从而解决了term vector的高维问题,不像有的模型不得不通过选取最频繁的部分term使得term vector截断















 2156
2156

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









