







背景信息

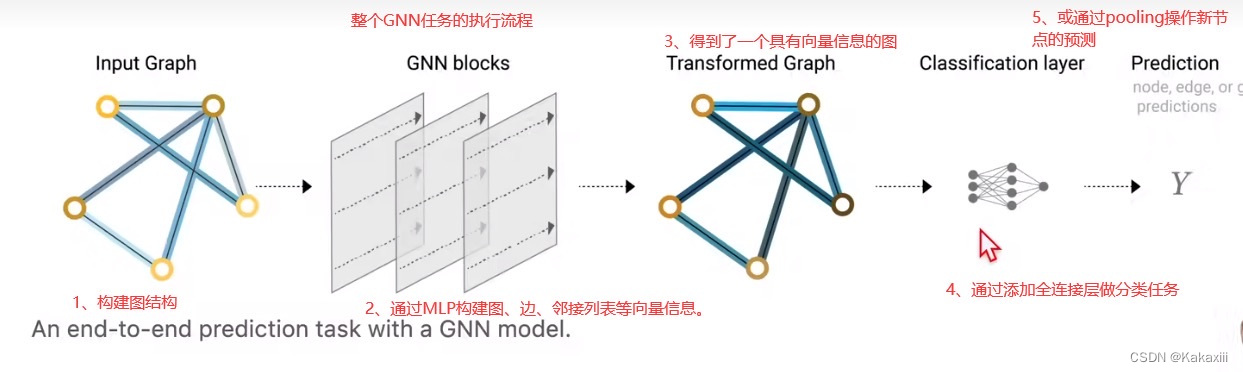
利用深度学习来做知识追踪(DLKT)任务的总的一个工作流程可以分为以下三个部分:
①表征学习:从显性记录中提取出隐性特征
②构建知识状态:通过不同的方式(将知识追踪问题定义成为不同的问题)构建学生的知识状态
③预测:当输入新的题目时,通过知识状态来预测学生的未来表现
而与之相对应的,目前的研究的优化方向,都是从这三个方向来对知识追踪进行改进和优化。
1、表征学习部分:如何融入更多信息;
2、知识状态的构建与传播:如何更符合知识状态的变化过程;
3、预测部分:如何建立知识状态ht与目标问题yt的联系;
从线性代数空间变换的角度来理解就是:先将行为构造为数字化的输入,即独立空间下的行为表示,使用函数将独立空间中的行为信号变换到隐空间下,这个过程可视为对行为的理解升华,再变换到输出空间,实现预测。
相关工作
那将前人的工作按照优化方式来分类可以分为以下三个部分:
在表征学习环节的优化:如何融入更多信息
| 相关模型 | 简介 |
|---|---|
|
GIKT
|
本质上还是一个序列神经网络
在嵌入部分采用了图卷积神经网络来传递知识点与问题的二部图的结构然后得到嵌入;
将练习过程构造为二部图,从二部图中得到顶点嵌入,即用户嵌入、题目嵌入,将其作为序列模型的输入,这样做既考虑到了行为的图结构特点,也考虑到了时序特点。

|
|
EKT
|
使用双向LSTM编码每个题的语义,再使用另一个LSTM来追踪学生的知识状态。
之前的KT任务中是单纯从知识概念编号(独热编码)来获取表示,EKT使用双向LSTM学习题目文本语义,将其作加入到输入中,可注入更多信息。
|
|
AKT
|
嵌入中考虑了问题的难度对于回答的影响,采用了Ratch嵌入。
|
|
PEBG(不是知识追踪模型)
|
将问题-问题、问题-知识点、知识点-知识点之间的显式关系、隐式关系和传播关系预训练到概念嵌入和知识点嵌入之中,提升知识追踪的效果。
|
|
DIMKT
|
定义知识点的难度和问题的难度,融入到嵌入中。
|
知识状态的构建与传播:如何定义知识追踪问题
1、将知识追踪问题定义为时间序列预测问题

|
相关模型
| 简介 |
|---|---|
|
DKT
|
利用LSTM层对学生的知识状态进行编码,以预测学生的反应表现。
|
|
DKT+
|
引入正则解决重构和不一致预测的问题。
|
|
DKTF
|
模拟了学生的遗忘行为。
|
|
KQN
|
使用学生知识状态编码器和技能编码器通过点积来预测学生的反应表现。
|
|
DKVMN
|
设计一个静态密钥矩阵来存储不同知识中心之间的关系,设计一个动态价值矩阵来更新学生的知识状态。
本质上还是时间序列预测问题,只每个时间步的状态存储外置,从ht外置到了V矩阵,然后通过问题的嵌入作索引去里面有选择的提取信息,这样能够一定程度的表示关系,更新矩阵的过程采用了擦除和添加的办法,擦出门和添加门同样来自v矩阵裹一层网络。
KC之间的潜在关系由迭代更新的外部记忆显式建模
增加外部记忆结构来扩展DKT
|
|
EKT
|
本质上还是时间序列预测问题:
1、双向LSTM编码每个题的语义。
2、另一个LSTM来追踪学生的知识状态
3、
EERNNM或EERNNA来做预测
|
|
GIKT
|
本质上还是一个序列神经网络
最后预测部分结合了之前得到的预测矩阵。
筛选出与当前预测题目最合适的history exercise 或者 hiddden state 。
在这里分为两种:
一种是hard selection ;另一种是soft selection。hard selection选择过往序列中与当前题目含有相同知识点的exercise或hidden state embedding;
soft selection选择过往序列中与当前exercise进行注意力计算后的top-k个embedding(且需要满足注意力值在阈值
|
|
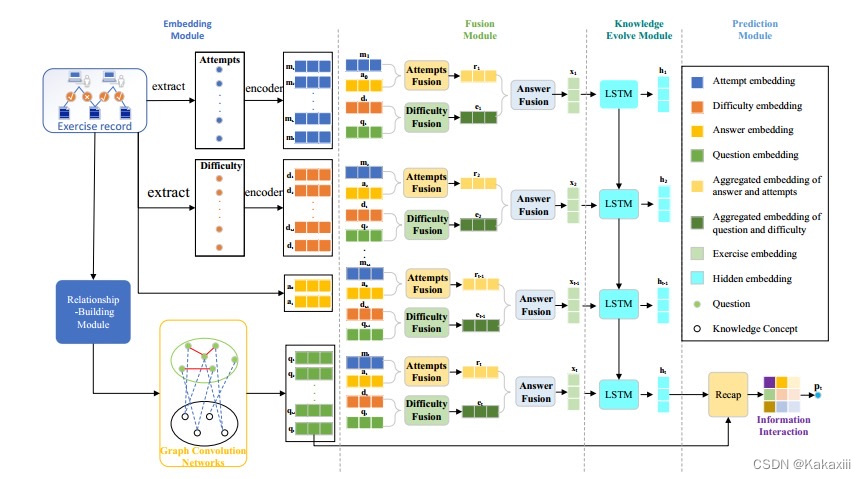
ADGKT
|
在gikt的基础上,将问题难度和尝试次数嵌入到输入中
|
|
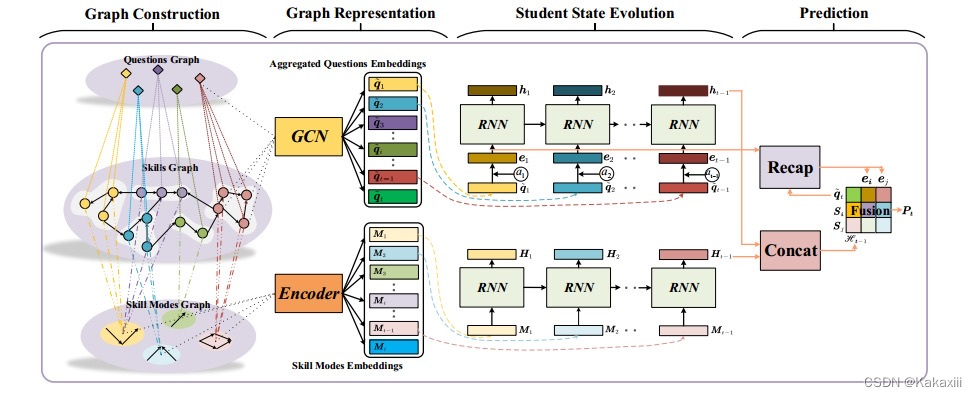
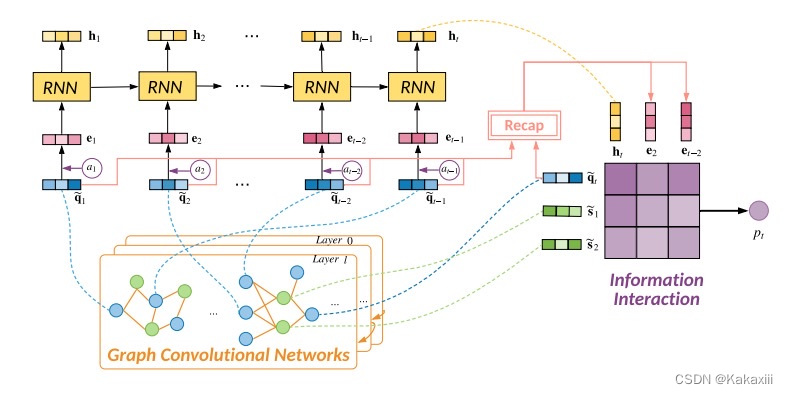
APGKT(2022)
|
在GIKT的基础上进行优化:
在表征阶段将技能模式引入;
技能模式:学生对技能的学习是循序渐进的,按照难度递增的方式循序渐进(带有难度信息的先后修,这里解决的先后修关系的表示模式,又不只是先后修)
|

2、将知识追踪问题定义为图的节点分类问题
|
相关模型
| 简介 |
|---|---|
|
GKT
|
将知识追踪问题定义成为图的节点分类问题,也就是将问题作为节点,正误作为节点的两种分类,将概念信息融合进节点中用于构建图结构,按照时间步去更新这个图结构的状态,传播节点信息,将最终的图结构的节点进行图分类。从而能够得到题目的回答情况。
|
|
RCD
|
则将学生-概念和概念-概念关系建模为层次图,通过汇总不同图中的节点信息来预测和更新回答的正确性。
|
|
SKT
|
利用信息传播分别计算数据在时间和空间上的影响, 再聚合它们用于预测学生表现。
|
3、将知识追踪问题定义为序列信息捕获问题

注意力网络中的ht是直接通过“计算”得来的?并没有经过传播。
也就是直接将学生的答题序列中的序列信息给用来创建学生的知识状态(位置信息)。
会使用到transformer来decode序列信息。
|
相关模型
| 简介 |
|---|---|
|
AKT
|
利用注意力机制来表征问题之间的时间距离和学生过去的互动
1、嵌入中考虑了问题的难度对于回答的影响,采用了Ratch嵌入
2、在建立知识状态的过程中,将学生的知识状态直接使用transformer去提取序列信息来得到。
3、预测还是经过一个简单的网络结构;
|
|
SAKT
|
利用自我注意机制来捕捉练习和学生反应之间的关系
|
|
SAINT
|
使用基于Transformer的编解码器架构来捕获学生的练习和响应序列
|
在预测结果环节的优化:如何建立知识状态ht与目标问题yt的联系
| 相关模型 | 简介 |
|---|---|
|
EKT
|
1、双向LSTM编码每个题的语义。
2、另一个LSTM来追踪学生的知识状态
3、
EERNNM或EERNNA来做预测
|
|
DIMKT
|
定义知识点的难度和问题的难度,融入到预测部分的ht中。
|
|
GIKT
|
本质上还是一个序列神经网络
最后预测部分结合了之前得到的预测矩阵。
筛选出与当前预测题目最合适的history exercise 或者 hiddden state 。
在这里分为两种:
一种是hard selection ;另一种是soft selection。hard selection选择过往序列中与当前题目含有相同知识点的exercise或hidden state embedding;
soft selection选择过往序列中与当前exercise进行注意力计算后的top-k个embedding(且需要满足注意力值在阈值
|
|
APGKT(2022)
|
在GIKT的基础上进行优化:
在表征阶段
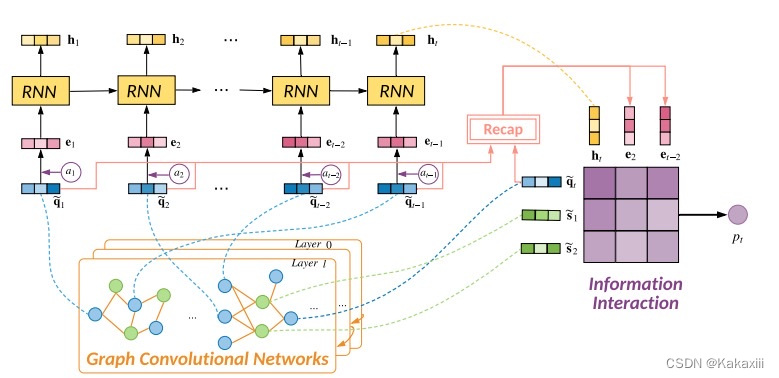
|
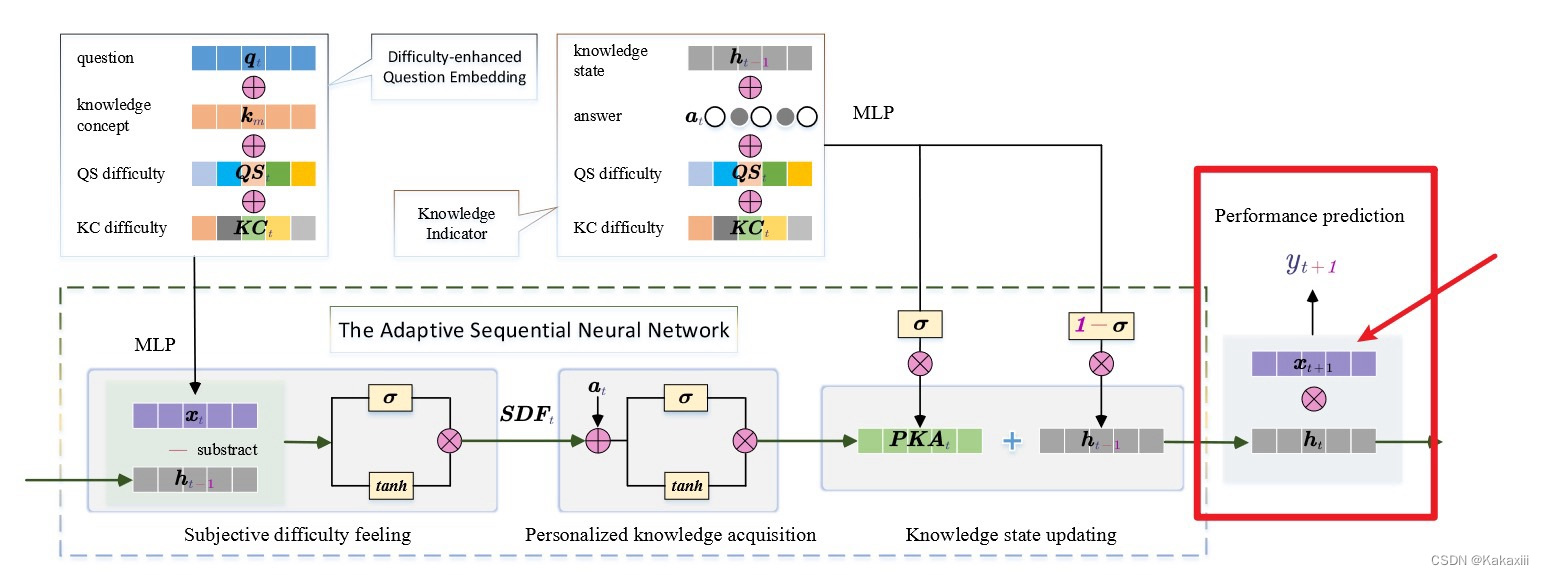
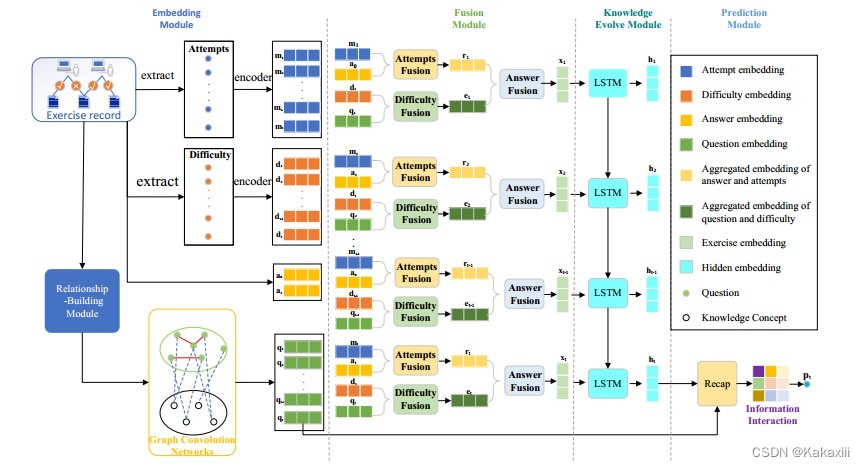
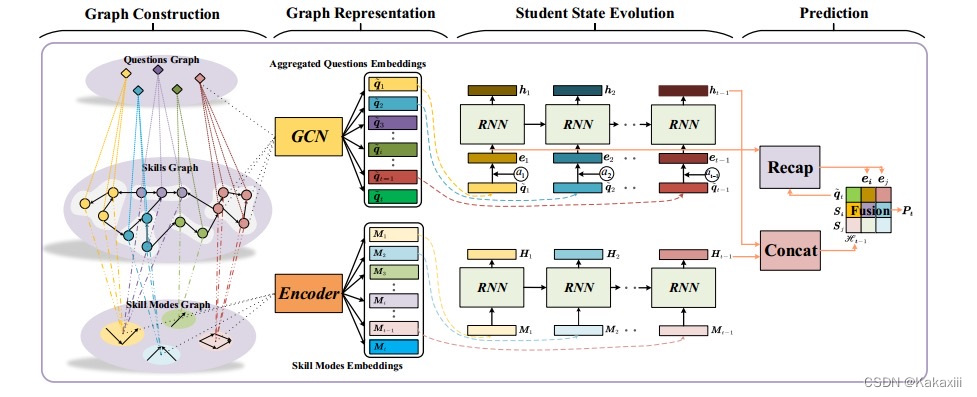
总结
- 使用图来构建知识点与问题的信息能够更好地构建知识状态
在之前的研究中,GKT、GIKT、SKT、PEBG所构建知识图,是符合知识点之间的关系以及问题之间的关系描述的,这些研究证明增加关系(相似关系和先后修关系)是可行的优化方向。① 但是GKT仅仅将知识点的间的信息考虑到了相似关系的传播,GKT构建图的过程采用了图结构学习,这个领域关注的是如何从数据中学习出图的结构,即节点和边之间的关系和连接。图结构学习的目标是发现节点之间的依赖关系、模式和网络的拓扑结构。也就是用知识点的数量,随机初始化了一个知识点与知识点之间的关系矩阵,结合概念与回答正误的融合特征信息来进行节点信息的传播,这样的方法仅靠答题序列的信息学习的隐藏层状态,这不具有解释性。GIKT和SKT本质上都是序列神经网络,GIKT在表征学习环节融入了结点间的相似关系,并在预测环节补充来进行预测;SKT则是在知识状态的传播过程中,去对照关系传播信息,已达到更新状态的作用。并没有一个既具有解释性,又充分利用信息的知识追踪模型。而PEBG通过预训练考虑的多种关系后可以明显提升知识追踪的预测结果这也说明了通过学习关系对知识状态的影响是可行的。
- 融入更多的问题属性信息以符合现实学习往往会有更好的效果
在之前的研究中GIKT、EKT、AKT以及DIMKT在表征学习部分融入了难度、关系、上下文等信息,说明了融入更多题目属性信息之后能够得到一个更符合现实学生学习的知识状态②,那么在前面1节提到的图中融入结点,也就是题目的相关信息(难度、区分度、问题类型(5, one-hot)、平均反应时间、平均回答次数、平均正确率),将这些信息作为节点属性用作结点更新的辅助信息,也能更好地表示学生的知识状态,达到优化知识追踪的效果。
那么结合①②两个点,在GIKT的基础上将知识追踪问题定义为时间序列预测问题,采用GAT(图注意力网络)来学习图结构,用属性信息(难度、区分度、问题类型(5, one-hot)、平均反应时间、平均回答次数、平均正确率)用作GAT更新过程中目标节点邻接边的权重计算。并在知识状态的传递过程中采用增加衰减器模拟学生学习中的遗忘过程,这样在比GIKT模型更具解释性的情况下,也能够融入更多性信息建立符合现实学习过程的知识状态构建嘛。
参考
- He L, Li X, Wang P, et al. MAN: Memory-augmented Attentive Networks for Deep Learning-based Knowledge Tracing[J]. ACM Transactions on Information Systems, 2024, 42(1): 1-22.
- Song X, Li J, Cai T, et al. A survey on deep learning based knowledge tracing[J]. Knowledge-Based Systems, 2022, 258: 110036.
- Nakagawa H, Iwasawa Y, Matsuo Y. Graph-based Knowledge Tracing: Modeling Student Proficiency Using Graph Neural Network[C]//IEEE/WIC/ACM International Conference on Web Intelligence. 2019: 156-163.
- Cui C, Yao Y, Zhang C, et al. DGEKT: A Dual Graph Ensemble Learning Method for Knowledge Tracing[J]. ACM Transactions on Information Systems, 2024, 42(3): 1-24.
- Yang Y, Shen J, Qu Y, et al. GIKT: A Graph-Based Interaction Model for Knowledge Tracing[C]//Machine Learning and Knowledge Discovery in Databases: European Conference. 2021: 299-315.
- Luo R, Liu F, Liang W, et al. DAGKT: Difficulty and Attempts Boosted Graph-Based Knowledge Tracing[C]//Neural Information Processing. Cham: Springer International Publishing, 2023: 255-266.
- Zhang H, Bu C, Liu F, et al. APGKT: Exploiting Associative Path on Skills Graph for Knowledge Tracing[C]//PRICAI 2022: Trends in Artificial Intelligence. 2022: 353-365.
下篇预告
下篇将会介绍详细的技术路线的实现思路(含关键步骤图解),需要的同学不要错过下期哦!

















 3495
3495

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









