







Hadoop生态圈

一 ,采集,数据从哪里来?主要包括flume等;
一 ,存储,海量的数据怎样有效的存储?主要包括hdfs、Kafka;
二,计算,海量的数据怎样快速计算?主要包括MapReduce、Spark、storm等;
三,查询,海量数据怎样快速查询?主要为Nosql和Olap,Nosql主要包括Hbase、 Cassandra 等,其中olap包括kylin、impla等,其中Nosql主要解决随机查询,Olap技术主要解决关联查询;
四,挖掘,海量数据怎样挖掘出隐藏的知识?也就是当前火热的机器学习和深度学习等技术,包括TensorFlow、mahout、spark等;
Apache Ambari是一种基于Web的工具,界面友好,支持Apache Hadoop集群的供应、管理和监控。Ambari已支持大多数Hadoop组件,包括HDFS、MapReduce、Hive、Pig、 Hbase、Zookeeper、Sqoop等,可用于生产环境。
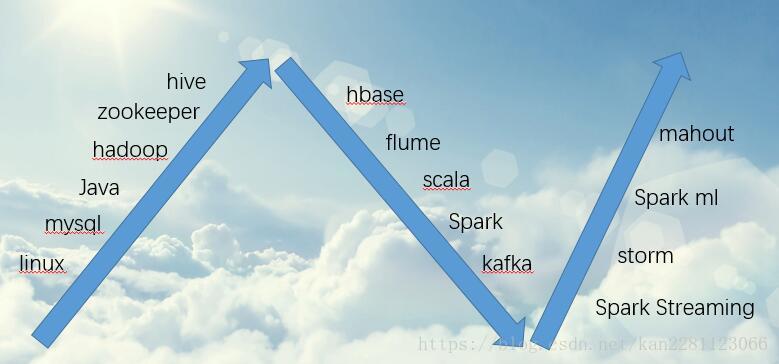
学习路线:
1、Hadoop是一个能够对大量数据进行分布式处理的软件框架,他以一种可靠、高效、可伸缩的方式进行数据处理。具有高可靠性、高扩展性、高效性、高容错性、低成本的特点。
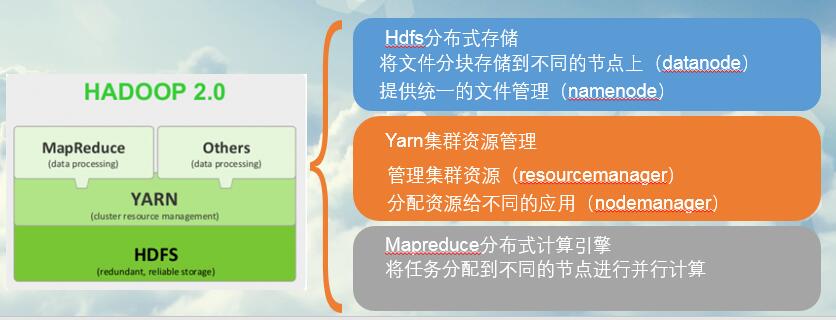
2、Hadoop hdfs–分布式文件系统
将文件分成多个block,分散存储到不同的节点上,并提供多副本,保证数据容错性能。
主从结构
- 主节点,可以有2个: na
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1873
1873











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









