






VidEdit: Zero-shot and Spatially Aware Text-driven Video Editing学习笔记

motivation:
1、文本驱动的扩散模型的简单的逐帧应用会导致闪烁的视频结果,缺乏运动信息和3D形状理解,效果较差
2、为了解决这一问题,引入diverse spatiotemporal attention mechanisms (时空注意力机制),存在问题:占用大量的内存资源、只专注于少量的帧,无法对长期依赖性进行建模,随时间推移不够可靠。
contribution:
1、将atlas-based(基于图谱)和预训练的文本到图像扩散模型相结合,提供了一种无需训练且高效的编辑方法
2、利用现成的全景分割器和边缘检测器,并将其用于基于条件扩散的图谱编辑
method
framework
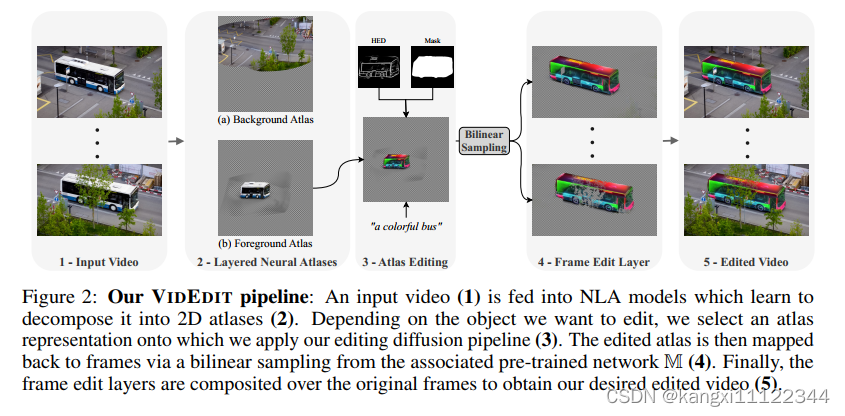 视频输入Neural Layered Atlas (NLA) 网络获得2D图谱
视频输入Neural Layered Atlas (NLA) 网络获得2D图谱
选择想要编辑的对象对应的图谱,执行编辑diffusion pipeline
编辑图谱通过双线性插值映射回帧(只有想要编辑对象的帧)
在原始帧上合成帧编辑层,获得想要的编辑视频
NLA
Neural Layered Atlases (NLA):神经分层图谱
将视频分解为一组2D图谱
对图谱图像执行基于文本的zero-shot编辑
Semantic Atlas Editing with VIDEDIT
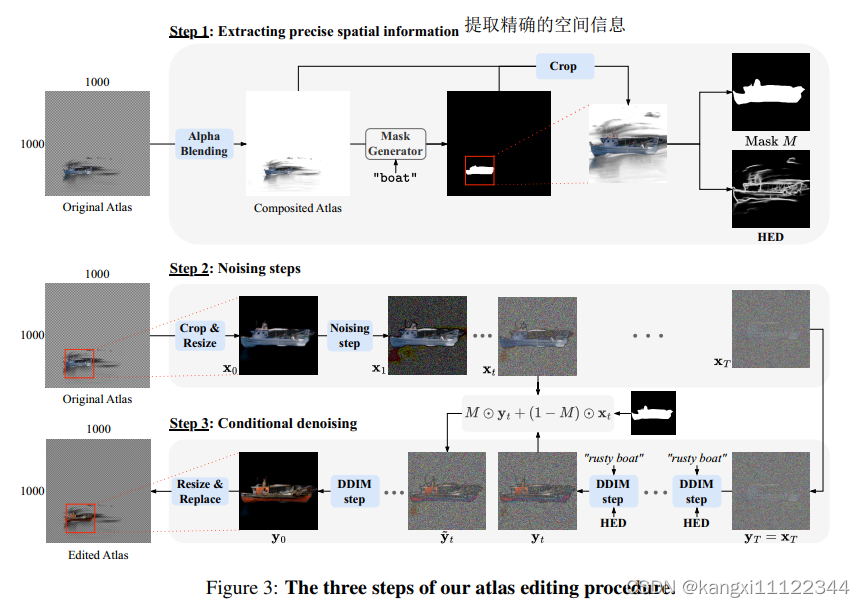
step1:利用全景分割器和边缘提取器得到mask和HED图
step2-step3:类似blended diffusion编辑区域用去噪得到的,未编辑区域用原图加噪得到的
experiments
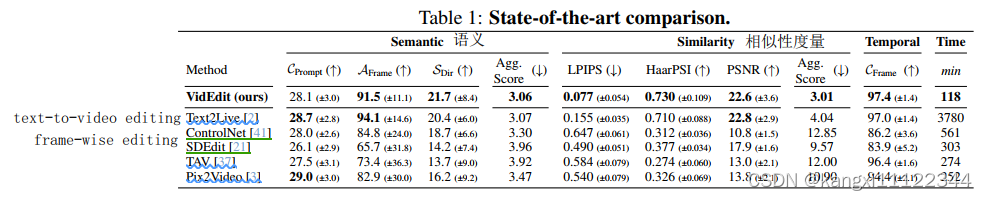
















 9306
9306











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









