






 本文介绍了如何使用Python爬取《流浪地球》的豆瓣影评数据,包括评分、评论时间、用户信息等,并进行初步分析,如评论数量与评分的关系、用户城市分布等。在爬取过程中,遇到的反爬策略和解决方案也进行了探讨。
本文介绍了如何使用Python爬取《流浪地球》的豆瓣影评数据,包括评分、评论时间、用户信息等,并进行初步分析,如评论数量与评分的关系、用户城市分布等。在爬取过程中,遇到的反爬策略和解决方案也进行了探讨。
- 背景与挖掘目标
- 获取豆瓣评论数据
- 分析好评与差评的关键信息
- 分析评论数量及评分与时间的关系
- 分析评论者的城市分布情况
1. 背景与挖掘目标
豆瓣(douban)是一个社区网站。网站由杨勃(网名“阿北”) 创立于2005年3月6日。该网站以书影音起家,提供关于书籍、电影、音乐等作品的信息,无论描述还是评论都由用户提供(User-generated content,UGC),是Web 2.0网站中具有特色的一个网站。
网站还提供书影音推荐、线下同城活动、小组话题交流等多种服务功能,它更像一个集品味系统(读书、电影、音乐)、表达系统(我读、我看、我听)和交流系统(同城、小组、友邻)于一体的创新网络服务,一直致力于帮助都市人群发现生活中有用的事物。
2019年2月5日电影《流浪地球》正式在中国内地上映。根据刘慈欣同名小说改编,影片故事设定在2075年,讲述了太阳即将毁灭,已经不适合人类生存,而面对绝境,人类将开启“流浪地球”计划,试图带着地球一起逃离太阳系,寻找人类新家园的故事。
《流浪地球》举行首映的时候,口碑好得出奇,所有去看片的业界大咖都发出了同样赞叹。文化学者戴锦华说:“中国科幻电影元年开启了。”导演徐峥则说,“里程碑式的电影,绝对是世界级别的。
可是公映之后,《流浪地球》的豆瓣评分却从8.4一路跌到了7.9。影片页面排在第一位的,是一篇一星影评《流浪地球,不及格》。文末有2.8万人点了“有用”,3.6万人点了“没用”。
关于《流浪地球》的观影评价,已经变成了一场逐渐失控的舆论混战,如“枪稿”作者灰狼所说,“关于它的舆论,已经演化成‘政治正确、水军横行、自来水灭差评、道德绑架、战狼精神。’”
挖掘目标:
- 获取豆瓣评论数据
- 分析好评与差评的关键信息
- 分析评论数量及评分与时间的关系
- 分析评论者的城市分布情况
2. 获取豆瓣评论数据
目标网址:https://movie.douban.com/subject/26266893/comments?status=P
获取首页数据
通过selenium和chromedriver获取数据
from selenium import webdriver
driver = webdriver.Chrome()
url = 'https://movie.douban.com/subject/26266893/comments?status=P'
driver.get(url)
获取用户名
通过driver.page_source获取网页源码
我们使用Xpath解析网页
通过下列代码获取names并命名
names = dom.xpath('//div[@class="comment-item"]//span[@class="comment-info"]/a/text()')
获取评价打分
通过谷歌开发者工具可以看到,class的属性决定评星。allstar10是一星,allstar50是五星。所以我们想要获取评价就要获取class的属性

同理:
dom.xpath('//div[@class="comment-item"]//span[@class="comment-info"]/span[2]/@class')
然而发现结果是:

显然,这其中有未打分的(comment-time),要对这种进行筛选。
获取评分时间
通过谷歌开发者工具发现,时间是在span的title属性里面
times = dom.xpath('//div[@class="comment-item"]//span[@class="comment-info"]/span[3]/@title')
获取短评内容
messages = dom.xpath('//div[@class="comment-item"]//div[@class="comment"]/p/span[@class="short"]/text()')
获取赞同量
votes = dom.xpath('//div[@class="comment-item"]//div[@class="comment"]/h3/span[@class="comment-vote"]/span[@class="votes"]/text()') # 赞同量
获取用户主页网
user_url = names = dom.xpath('//div[@class="comment-item"]//span[@class="comment-info"]/a/@href') # 用户主页网址
一直到上面这,都爬的好好的,然后当我想用request进入某个主页网址的时候,遇到了418反爬
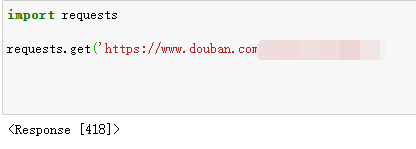
这里我选择的是用cookie。 登录获取一下cookies ,然后转换成字典(因为个人隐私,我删了几个数字):
cookies_str = 'bid=qKOdCLIajIs; _pk_ses.100001.4cf6=*; ap_v=0,6.0; __utma=30149280.688453215.1585988569.1585988569.1585988569.1; __utmc=30149280; __utmz=30149280.1585988569.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); __utma=223695111.1438858643.1585988569.1585988569.1585988569.1; __utmb=223695111.0.10.185988569; __utmc=223695111; __utmz=223695111.1585988569.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); __utmb=30149280.1.10.1585988569; ps=y; dbcl2="214558448:XIwFTrlzX1s"; ck=I1oq; _pk_id.100001.4cf6=279739e4a763236.1585988569.1.1585989402.1585988569.; push_noty_num=0; push_doumail_num=0'
cookies = {}
# 拆分
for i in cookies_str.split(';'):
key,value = i.split('=',1)
cookies[key] = value
cookies
好的,加了cookie之后发现还是418,去翻了翻博客,决定加一下头文件:
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36'}
然后再爬,终于成功了

获取用户居住地和入会时间信息
address = dom_url.xpath('//div[@class="user-info"]/a/text()') # 用户居住地
load_time = dom_url.xpath('//div[@class="basic-info"]//div[@class="pl"]/text()') # 用户加入时间
因为一个页面所以的评价都有一个主页,所以用for做个遍历。
同时,导入时间库,爬一次睡两秒防止反爬,部分代码:
import time
cities = [] #用户居住地址列表
load_times = [] # 用户加入时间列表
for i in user_url:
web_data = requests.get(i,cookies=cookies,headers=headers)
dom_url = etree.HTML(web_data.text,etree.HTMLParser(encoding='utf-8'))
address = dom_url.xpath('//div[@class="basic-info"]//div[@class="user-info"]/a/text()') # 用户居住地
load_time = dom_url.xpath('//div[@class="basic-info"]//div[@class="pl"]/text()') # 用户加入时间
cities.append(address)
load_times.append(load_time)
time.sleep(2) # 2秒访问一次反爬
结果: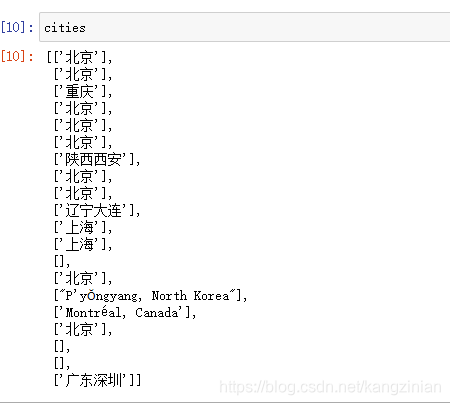
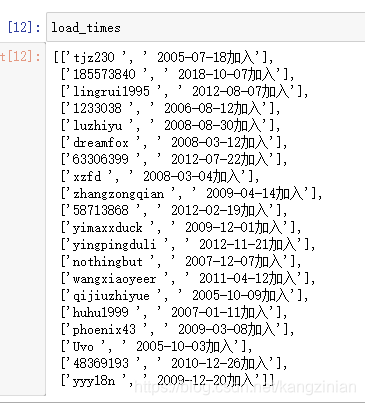
算是初步爬取成功
单页数据整理
获取到的数据要进行整理,去掉一些没用的数据,去掉缺失值,然后dataframe表格.
1. 评分数据ratings
如果没有评分,就保留一个空字符串;有评分打印评分。
先导入re模块。我们需要的是一个int型数据,使用==int()转换类型,加个[0]==来获取引号里面的值,,就有:
import re
["" if 'rating' not in i else int(re.findall('\d{2}', i)[0]) for i in ratings] # 评分数据整理
2. load_times
我们需要的是后面那个元素的日期.
可以使用strip将前后的元素剔除,如果没有加入时间使用”“代替,不需要最后两个字,所以加一个==[:-2]==
load_times = ["" if i==[] else i[1].strip()[:-2] for i in load_times] # 入会时间整理
3. cities
我们需要放在一个列表中,而不是嵌套列表
cities = ["" if i==[] else i[0] for i in cities] # 居住地的数据整理
最后导入库准备建表:
import pandas as pd
data = pd.DataFrame({
'用户名':names,
'居住城市':cities,
'加入时间':load_times,
'评分':ratings,
'发表时间':times,
'短评正文':messages,
'赞同数量':votes
})
但是报错:arrays must all be same length
查找了一番,发现times只有19个数据,其他的都20个数据.
然后改了一下times的查找方式:
times = dom.xpath('//div[@class="comment-item"]//span[@class="comment-info"]/span[@class="comment-time "]/@title')# 评论发布时间
然后数据就保存好了,但是这个数据是一个页面的数据,
所以要把这个data的构建定义成一个函数:
def get_web_data(dom=None,cookies=None):
names = dom.xpath('//div[@class="comment-item"]//span[@class="comment-info"]/a/text()') # 用户名
ratings= dom.xpath('//div[@class="comment-item"]//span[@class="comment-info"]/span[2]/@class') # 评分
times = dom.xpath('//div[@class="comment-item"]//span[@class="comment-info"]/span[@class="comment-time "]/@title')# 评论发布时间
messages = dom.xpath('//div[@class="comment-item"]//div[@class="comment"]/p/span[@class="short"]/text()') # 短评正文
user_url = dom.xpath('//div[@class="comment-item"]//span[@class="comment-info"]/a/@href') # 用户主页网址
votes = dom.xpath('//div[@class="comment-item"]//div[@class="comment"]/h3/span[@class="comment-vote"]/span[@class="votes"]/text()') # 赞同量
cities = [] #用户居住地址列表
load_times = [] # 用户加入时间列表
for i in user_url:
web_data = requests.get(i,cookies=cookies,headers=headers)
dom_url = etree.HTML(web_data.text,etree.HTMLParser(encoding='utf-8'))
address = dom_url.xpath('//div[@class="basic-info"]//div[@class="user-info"]/a/text()') # 用户居住地
load_time = dom_url.xpath('//div[@class="basic-info"]//div[@class="pl"]/text()') # 用户加入时间
cities.append(address)
load_times.append(load_time)
time.sleep(2) # 2秒访问一次反爬
ratings = ["" if 'rating' not in i else int(re.findall('\d{2}', i)[0]) for i in ratings] # 评分数据整理
load_times = ["" if i==[] else i[1].strip()[:-2] for i in load_times] # 入会时间整理
cities = ["" if i==[] else i[0] for i in cities] # 居住地的数据整理
data = pd.DataFrame({
'用户名':names,
'居住城市':cities,
'加入时间':load_times,
'评分':ratings,
'发表时间':times,
'短评正文':messages,
'赞同数量':votes
})
return data
接下来就是把这个函数应用于每一页,所以我们需要判断网页是否已经加载。
设置一个死循环whlie ture,除非满足到最后一页,否转一直进行单页读取,还要设置一个10秒没有加载好就报错的警示。
当当前页面最后一个评论的主页可以被点击,就默认这个页面被加载进来,否转就终止程序.
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
wait.until(
EC.element_to_be_clickable(
(By.CSS_SELECTOR,'#comments > div:nth-child(20) > div.comment > h3 > span.comment-info > a')
)
)
最后一页,可以通过selector来判断,如果没有 #paginator > a.next 则是尾页,或者有 #paginator > span 是尾页,但是首页也有,所以选择第一种。
代码:
all_data = pd.DataFrame()
wait = WebDriverWait(driver, 10) # 10秒内能加载就操作,不能就报错
while True:
wait.until(
EC.element_to_be_clickable(
(By.CSS_SELECTOR,'#comments > div:nth-child(20) > div.comment > h3 > span.comment-info > a')
)
)
dom = etree.HTML(driver.page_source,etree.HTMLParser(encoding='utf-8'))
data = get_web_data(dom=dom,cookies=cookies)
all_data = pd.concat([all_data,data],axis=0) # 按列拼接
# 当后页无法点击,终止循环
#paginator > span
#paginator > a.next
if driver.find_element_by_css_selector('#paginator > a.next')=[]: # 判断是否还有“后页”按钮
break
confirm_bnt = wait.until(
EC.element_to_be_clickable(
(By.CSS_SELECTOR,"#paginator > a.next")
)
)
confirm_bnt.click() # 翻页
大概十几二十分钟,就爬取完了之后就可以保存了
all_data.to_csv('doubanliulangdiqiu.csv', index=None.encoding='GB18030')
编码方式可以自己根据需要决定。
为了爬取所有数据,还是自己登录一下比较好

















 1567
1567





 到【灌水乐园】发言
到【灌水乐园】发言







