







众所周知,Python的爬虫是一个很好用的数据工具,但是学校课程设置涉及甚少。前段时间,恰好遇到HR面试时问了,自己不会,还有就是朋友工作中做数据整理想偷懒找我做爬虫,我又又又不会。于是乎,趁这段空闲时间,开启爬虫选手初养成系列,记录自己的爬虫学习过程。
爬取影评数据
网络爬虫
爬虫过程一般分三步走:(1)网络数据抓包;(2)获取url,向服务器发送链接请求;(3)接收服务器返回的响应。接下来就展开了说一下。
(1)网络数据抓包
网络数据抓包就是抓取网络接口请求的数据,常用工具有 Fiddler、Wireshark等等。但我今天爬的是网站,直接在网页内按F12—>network就可以查看数据请求了。主要看一些Headers中的信息和HTML语言结构。
(2)获取url,向服务器发送链接请求
url就是我们熟知的网址。在向服务器发送链接请求的过程中,很容易被网站反爬制裁,因此这里就需要用到我们上面抓包获取的Headers信息了,我们可以先通过抓包看看正常一个浏览器访问网页时,向服务器发送的请求包含哪些信息,在我们爬虫时就可以将Headers信息封装进我们的请求,方便伪装自己。用Python中的urllib库就可以完成。
(3)接收服务器返回的响应
这没啥好说的,就是计算机网络里经典的三次握手,四次挥手。
def get_page(url,headers):
req = request.Request(url,headers=headers) #发送请求
response = request.urlopen(req) #获取响应
url_string = response.read().decode('utf-8') #将响应变成字符串显示
return url_string
(4)解析HTML,获取需要的数据
在收到服务器的响应后,我们得到的是HTML格式的字符串,需要对HTML进行解析。在解析HTML上,Python的正则表达式和Beautifulsoup有异曲同工之妙,都是寻找匹配的字符串。但是正则表达式要去记符号的表示,没有Beautifulsoup方便。两者都只要基本掌握find和find_all函数就行。find函数是找出匹配模式的第一个字符串,find_all是找出匹配模式的所有字符串。
这边我爬取了四部电影的影评和评分,分别是《肖申克的救赎》、《美人鱼》、《想见你》、《交换人生》。

踩坑指南
在爬取数据过程中遇到两个坑:a)第一个是反爬,我将User_agent加入Headers还用time.sleep设置了间隔时间防止访问过快导致IP被封,即使这样但仍在爬取几百条数据后会出现error:Forbidden 403。无所谓,遇到了咱们换部电影,接着爬就是了。电影千千万,虽然我不能一下子爬完一部电影的全部影评,但我多爬几部就是了。反反爬之路,来日方长。b)第二个就是各位广大网友真的文采斐然,影评写的像大作文一样,需要点击“展开”才能查看完整影评,但是,在HTML结构中,这一部分展开的内容好像是被隐藏的,我不知道怎么获取,这个坑目前还没解决,只能爬豆瓣短评了,面对那些精选评论,默默落下了眼泪。
影评数据应用之情感分析
既然数据都爬完了,不用这些数据做点什么总感觉意犹未尽,于是就用我爬取的《肖申克的救赎》、《美人鱼》、《想见你》、《交换人生》影评做一个中文情感分析。这里为了训练能快一点,一共是784条数据。
数据预处理
不难发现,在爬取的影评中有很多emoji、颜文字和奇怪的符号,这些是不能用于文本训练的,需要去掉。其次,我们还需要根据推荐程度给数据打上标签。这里我将力荐、推荐、还行标记为正面情感(数字1),较差和很差记为负面情感(数字0),做一个二分类的中文情感分析。
(1)jieba分词
对于中文文本需要用jieba分词库将每句话分成一个又一个词或字。在用的时候发现,jieba库里居然没有“还行”这一个词组,没办法只能手动添上了,否则会分成“还”和“行”,不利于标签转化
(2)去停用词
停用词是指在信息检索中,为节省存储空间和提高搜索效率,在处理自然语言数据(或文本)之前或之后会自动过滤掉某些字或词,这些字或词即被称为Stop Words(停用词)。简而言之,就是去掉一些语气词,或是表承接的词,但不影响总体语义。
这里不得不提一下现在网络语言文化,现在的停用词面对各式各样的emoji和颜文字根本不够用,我在使用开源停用词时在原来的基础上加了不少。
(3)标签转化
模型训练只认数字,要把标签转换成数字,好评记为1,差评记为0.
(4)划分训练集和测试集
这一步就是将上面的数据打乱,划出一部分用于训练,另一部分用于测试,一般比例为8:2。
词向量嵌入
词向量:将词汇表的单词或短语映射到实数的向量。简而言之就是,如何将中文字表示成一个向量,将自然语言转换为向量之间的计算。
one-hot编码:基于词袋模型的表征方法。什么是词袋,什么是one-hot,举个例子就知道了。
假设现在有三句句子[“我要上南京信息工程大学”,“我学习信息工程专业”,“我在南京学习”]
分词后得到的是[“我”,“要”,“上”,“南京”,“信息工程”,“大学”,“学习”,“专业”,“在”],其实这个分词后不存在重复词的列表就是一个词袋,它像字典一样包含了句子中所有的词,可供查询。one-hot编码就是对于词袋中的每一个词,如果该词存在于本句子中就标记为1,反之则为0。因此编码长度一般与词袋大小等长。上述三句话编码后的结果为:
“我要上南京信息工程大学”——>[1,1,1,1,1,1,0,0,0]
“我学习信息工程专业”——>[1,0,0,0,1,0,1,1,0]
“我在南京学习”——>[1,0,0,1,0,0,1,0,1]
one-hot编码有个明显的缺点,就是没有上下文关联,词与词之间是割裂的。于是就有了其他的词向量表征方法,如Word2Vec、Glove等等,这些模型可以将单词从原先所属的空间映射到新的多维空间中,也就是把原先词所在空间嵌入到一个新的空间中去。可以理解为映射到更高的语义空间。但是,这里我一直搞不清word2vec和词向量嵌入概念的从属关系,直到在一篇CSDN中找到了满意的答案(已在文章最下方分享链接)。
词向量嵌入(word embedding):通过一定的方式将词汇映射到指定维度(一般是更高维度)的空间.
广义的word embedding包括所有密集词汇向量的表示方法,如之前学习的word2vec, 即可认为是word embedding的一种.
狭义的word embedding是指在神经网络中加入的embedding层, 对整个网络进行训练的同时产生的embedding矩阵(embedding层的参数), 这个embedding矩阵就是训练过程中所有输入词汇的向量表示组成的矩阵.
模型训练
模型比较简单,一层Embedding层,一层LSTM层,一层全连接层。
#define model
units = 32
model = Sequential()
model.add(Embedding(max_words, embedding_dim))
model.add(LSTM(units))
model.add(Dense(1, activation='sigmoid'))
model.summary()
model.layers[0].set_weights([embedding_matrix])
model.layers[0].trainable = False
model.compile(optimizer='rmsprop',
#设定损失函数
loss='binary_crossentropy',
metrics=['acc'])
history = model.fit(X_train, y_train,
epochs=10,
batch_size=32,
validation_data=(X_valid,y_valid)
)
训练结果如下:
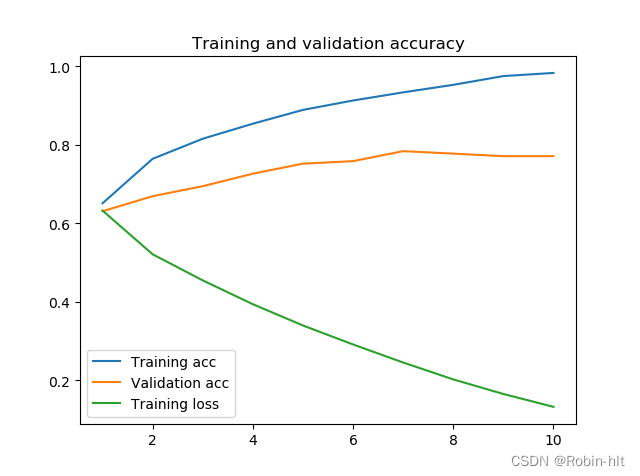
结果测试
这里用了几句不在数据集里的评论进行测试
sentence1 = '这两年太多太多这种剧了 真的很无聊'
sentence2 = '中国也是可以拍出很精彩的剧的!两位演技派把一正一邪的形象在黑社会帽子影响下的演变演绎了出来,非常精彩,人物都有血有肉,追剧追剧'
def show_pred(sentence):
input = np.zeros((100,))
i = -1
for x in jieba.cut(sentence):
if x in word_index.keys():
input[i] = word_index[x]
i -= 1
else:
input[i] = 0
i -= 1
label = model.predict(input.reshape(1, -1))
if label > 0.5:
print('好评')
else:
print('差评')
show_pred(sentence1)
show_pred(sentence2)
#输出:
#好评
#差评
别看这两句预测准确了,其实很多影评预测不一定准确,不过实验测试还算成功。
踩坑指南
感觉在应用环节,所有的问题都处在了数据预处理环节,真的是数据处理不好,模型就跑不起来。
踩坑1:有些影评分词后再去停用词,就变成空数据了Null。别不信,比如有的影评可能就用……表示对电影的无语。
解决方案:用.fillna(“”)把Null数据用空字符串代替。
踩坑2:emoji和颜文字,真的是怎么都清理不干净,大家的表达真的太多元了。
解决方案:统统加入停用词表。
资源获取
该项目完整获取: https://github.com/robin-hlt/Chinese-Film-Comments-Sentiment-Analysis
参考资源
文本预处理请参考链接: https://blog.csdn.net/rouge_eradiction/article/details/108456263
https://blog.csdn.net/rouge_eradiction/article/details/108456263
one-hot编码请参考链接:https://zhuanlan.zhihu.com/p/595664193
词向量请参考链接: https://blog.csdn.net/superflash_/article/details/122398687
















 279
279











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









