







Paper name
TAMING TRANSFORMERS FOR HIGH-RESOLUTION IMAGE SYNTHESIS (A.K.A #VQGAN)
Paper Reading Note
Paper URL: https://arxiv.org/abs/2012.09841
Project URL: https://compvis.github.io/taming-transformers/
Code URL: https://github.com/CompVis/taming-transformers
TL;DR
- 2021 CVPR 文章,出自海德堡大学。本文结合 transformer 和 CNNs 两个结构,提升网络的建模能力,实现了高质量的图像生成效果。
Introduction
背景
- 设计用于长序列数据的 transformer 结构在各种任务上都取得了 SOTA 的结果。在 NLP 上是毫无疑问的王者模型结构,同时也在逐步适配于图像和音频领域
- 与主导视觉架构卷积神经网络(CNNs)不同,变压器架构没有内置的关于交互局部性的归纳先验,因此可以自由学习其输入之间的复杂关系。然而,这种泛化性也意味着它必须学习所有关系,而 CNNs 则被设计用于利用图像中强烈的局部相关性的先验知识。因此,transformer 的增强表达能力伴随着计算成本的二次方增长,因为考虑了所有成对的交互。因此,现代 tranformer 模型的计算资源和时间需求对于将其扩展到具有数百万像素的高分辨率图像构成了基本问题。
- 目前一些工作发现 transformer 倾向于学习类似卷积结构的功能,这就引发了一些思考:
- 每次训练视觉模型时,是否必须从头开始重新学习有关图像的局部结构和规律,还是可以在保留 transformer 的灵活性的同时高效地编码归纳图像偏见?
- 作者猜测 CNNs 在学习图像的底层结构信息时有效,但是高层语义层面就不够了。CNNs 不仅有强烈的局部性偏见,而且通过在所有位置使用共享权重来表现出对空间不变性的偏见。如果需要更全面地理解输入图像,CNNs 效果不佳
本文方案
- 本文结合 transformer 和 CNNs 两个结构,提升网络的建模能力,实现了高质量的图像生成效果。
- 我们使用卷积方法来高效学习一个上下文丰富的视觉部分的 codebook,随后学习其全局组成的模型
- 这些组成部分内的长程交互需要一个富有表现力的 transformer 架构来建模其各个视觉部分的分布。
- 此外,利用对抗方法来确保局部部分的字典捕捉到感知上重要的局部结构,以减轻使用 transformer 架构对低级统计建模的需求。允许变压器专注于其独特的强项——建模长程关系——使它们能够生成高分辨率图像,就像下图一样,这是以前无法实现的效果
- 通过提供关于所需对象类别或空间布局的条件信息(conditioning information),直接控制生成的图像

Methods
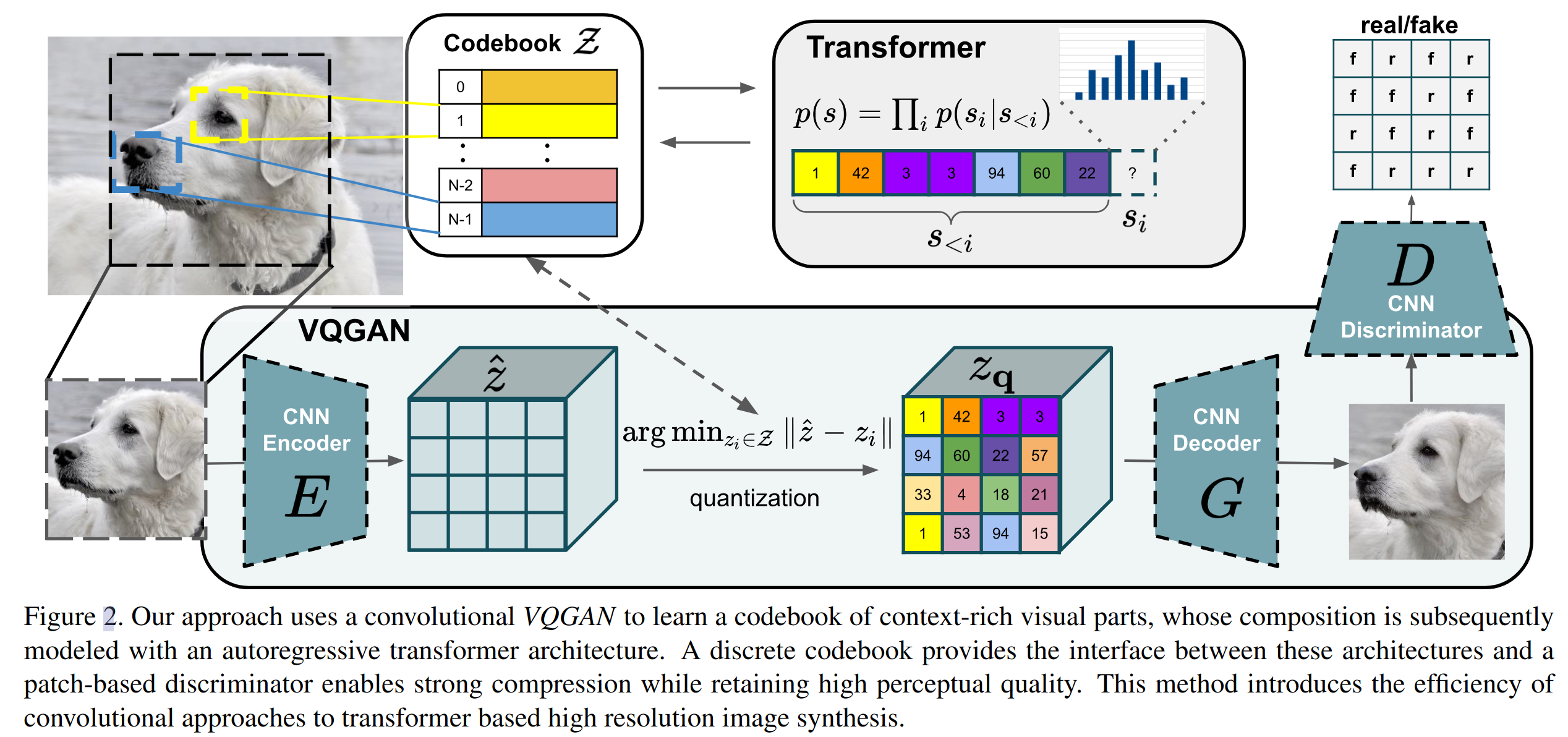
学习用于图像组成的 codebook(VQVAE)
- 如上图所示,对于输入图像经过卷积网络 E 得到图像特征
z
^
\hat{z}
z^,定义一个可学习的 codebook,通过 quantization 操作得到量化后的特征
z
q
z_{q}
zq,量化操作主要对于
z
^
\hat{z}
z^ 中的每个 index 的特征在 codebook 中找到最接近的特征表达,公式表达如下:

然后通过卷积网络 G 得到重建的图像

需要主要的是这里的 quantization 操作不可微,所以使用了 STE 来进行梯度反传,即将梯度直接从 decoder 复制到 encoder 上,实现了端到端的训练。整体训练 loss 函数如下:
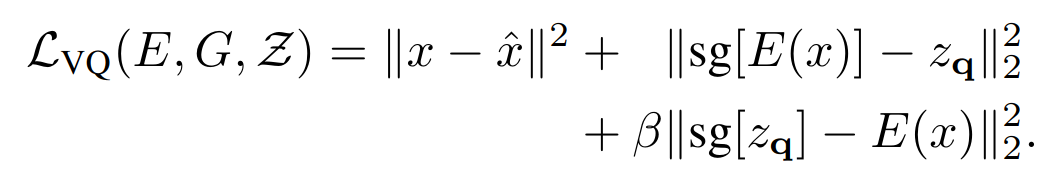
其中第一项是图像重建损失,sg 代表梯度截断操作
学习感知丰富的 codebook (VQGAN)
-
相比于 VQVAE 的改良
-
使用了 GAN 训练方式,引入了 patch-based discriminator D

-
使用了 perceptrual loss,替换 l2 损失
-
-
最后使用的损失函数是 VQ 损失和 GAN 损失的加权和

其中 λ \lambda λ 为一个自适应的权重,计算方式如下:
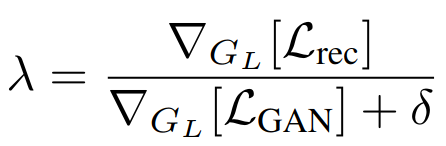
其中 Lrec 是 perceptual 损失, ∇ G L [ ⋅ ] \nabla_{G_{L}}[\cdot] ∇GL[⋅] 代表输入对于 decoder 最后一层的梯度, δ = 1 0 − 6 \delta=10^{-6} δ=10−6 用于确保数值计算稳定 -
为了聚合全局上下文信息,在分辨率最低的特征处使用一个 transformer attention layer
Learning the Composition of Images with Transformers
- 在二阶段训练中使用 transformer 结构来学习图像的组成,也即如上的网络架构图中的 transformer 模块所示,基于自回归的方式进行训练,学习预测 codebook 中的 index
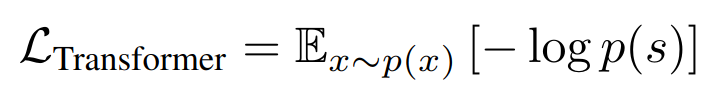
Conditioned Synthesis
- 在许多图像合成任务中,用户希望通过提供额外信息来控制生成过程,从中合成一个示例。我们将这个信息称为 c,可以是描述整体图像类别的单个标签,甚至是另一幅图像本身。任务就是学习给定此信息 c 时序列作为前提:
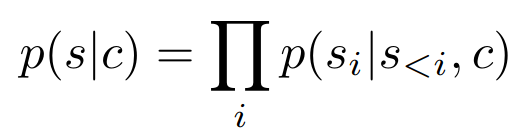
如果条件信息 c 具有空间结构,我们首先学习另一个 VQGAN,再次获得一个基于索引的表示
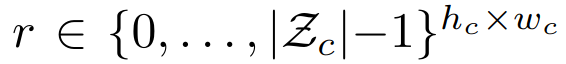
其中 Zc 是新获得的 codebook。由于 transformer 的自回归结构,我们可以简单地将 r 前置到 s,并将负对数似然的计算限制在以下条目

这种 “decoder-only” 策略在文本摘要任务中也取得了不错的效果
Generating High-Resolution Images
- 上面设计的 transformer attention 机制限制了输入的尺寸为固定的 h x w 尺寸。虽然我们可以调整我们的 VQGAN 的下采样块数量 m,将尺寸为 H × W 的图像缩小到 h = H/2m × w = W/2m,但我们观察到在 m 达到关键值后,重建质量会下降,这个关键值取决于考虑的数据集。因此,为了在百万像素范围内生成图像,我们必须逐块进行处理,并在训练期间将图像裁剪以限制 s 的长度到最大可行的大小。为了采样图像,以下图中所示的滑动窗口方式来利用 transformer。我们的 VQGAN 确保可用的上下文仍足以忠实地对图像进行建模,只要数据集的统计信息大致上是空间不变的,或者有空间调节信息可用。在实践中,这并不是一个严格的要求,因为当违反它时,即在对齐的数据上进行无条件的图像合成时,我们可以简单地在图像坐标上进行条件设定,类似于 COCO-GAN。
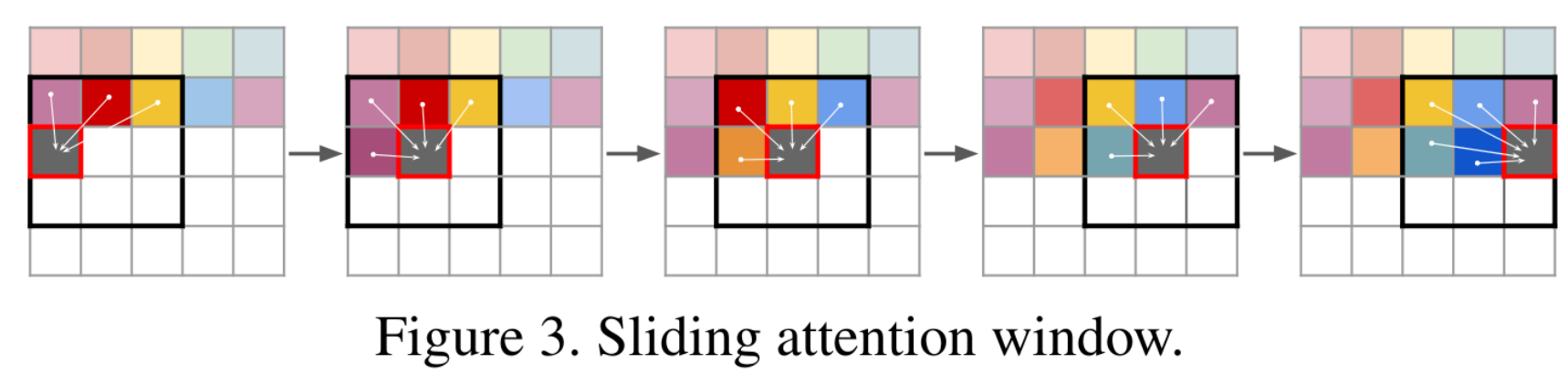
Experiments
transformer 架构有效性实验
- 每个任务,我们训练一个带有m=4下采样块的VQGAN。如果需要,为条件信息再训练一个。然后,在相同的表示上,分别训练 transformer 和 PixelSNAIL 模型,因为后者已在先前的最先进的两阶段方法中使用。为了进行全面比较,我们在 85M 和 310M 参数之间变化模型容量,并调整每个模型中的层数以使它们匹配。我们观察到 PixelSNAIL 的训练效率大约是 transformer 的两倍,因此为了进行公平比较,报告相同训练时间(P-SNAIL时间)和相同训练步数(P-SNAIL步数)下的负对数似然。

上表报告了在 ImageNet(IN)、Restricted ImageNet(RIN)(由ImageNet中的动物类别子集组成)、LSUN Churches and Towers(LSUN-CT) 上进行无条件图像建模的结果,以及在基于 MiDaS 方法获得的深度图(D-RIN)上进行的条件图像建模,以及在基于 DeepLab 方法获得的 Flickr 上的语义掩码(S-FLCKR)上进行的条件图像建模。请注意,对于语义掩码,我们使用交叉熵重建损失来训练第一阶段,因为它们具有离散的特性。结果表明,当在相同的训练时间内训练时, transformer 在所有任务上始终优于 PixelSNAIL,并且当在相同数量的步骤上训练时,差距甚至进一步增加。这些结果表明,transformer 的优势在我们提出的两阶段设置中得以体现
条件生成效果
- 支持语义图像合成、

Context-Rich 的 codebook 的重要性
- 为了验证上下文丰富词汇表有多重要,在 HQ-Faces(CelebA-HQ和FFHQ的结合) 数据集上进行验证。其中 transformer 架构保持不变,通过改变 vqgan 的下采样块的数目,调整了编码到第一阶段表示的上下文量。我们以缩减图像输入和生成的表示之间的边长的方式来指定编码的上下文量,即将大小为 H×W 的图像编码到大小为 H/f×W/f 的离散代码中,其中 f 表示一个 reduction factor(折减系数,对于f = 1,我们复制了 Generative Pretraining From Pixels 的方法,并用 k = 512 的 RGB 值的 k 均值聚类替换了我们的VQGAN)。在训练期间,我们总是裁剪图像以获得大小为 16×16 的 transformer 输入,即在使用第一阶段中的因子 f 建模图像时,我们使用大小为 16f×16f 的裁剪图像输入网络。
- 以下结果清晰地展示了强大的VQGAN通过增加 transformer 的有效感受野所带来的好处。对于较小的感受野,或者等效地较小的f,模型无法捕捉一致的结构。对于中等值的f = 8,可以近似表示图像的整体结构,但是会出现面部特征的不一致性,如半胡子脸和图像不同部分的视点不一致。只有我们的完整设置f = 16才能合成高保真度的样本。最后一行显示了加速比,原始在像素级别进行预测,一张图需要花费 7258 s(基于 Titan X 测试),而使用更高的下采样倍率图像生成效率能大幅提升

- class-conditional 合成

- 人脸生成
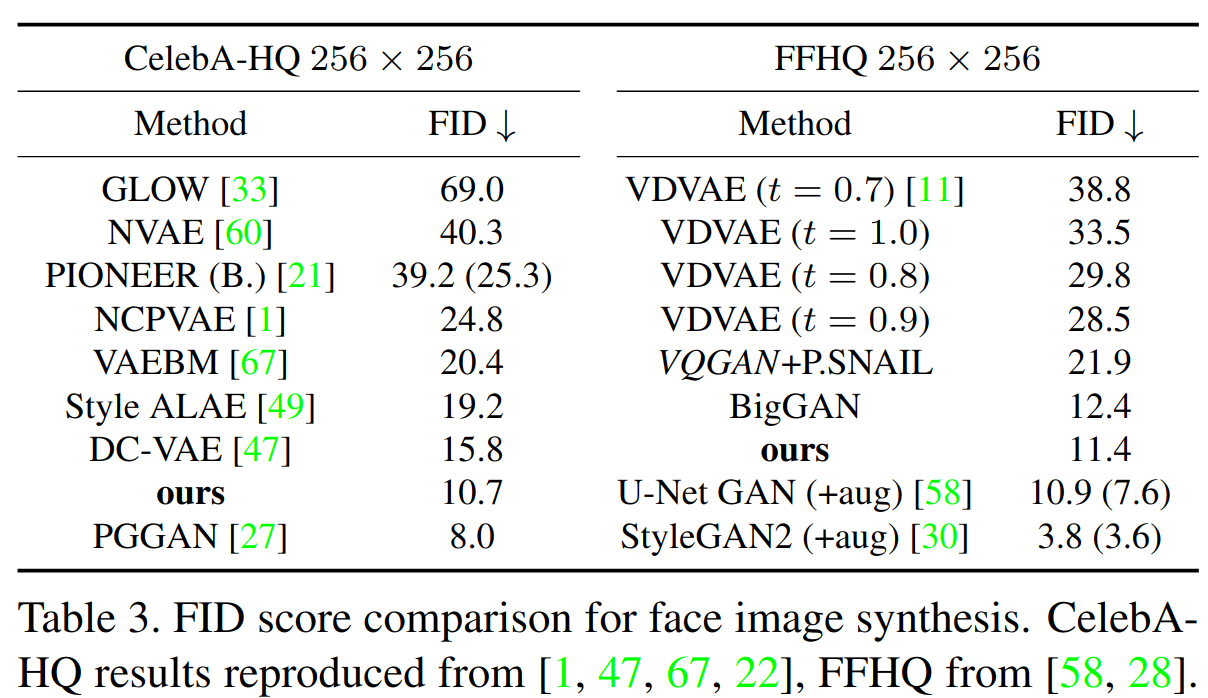
定量对比
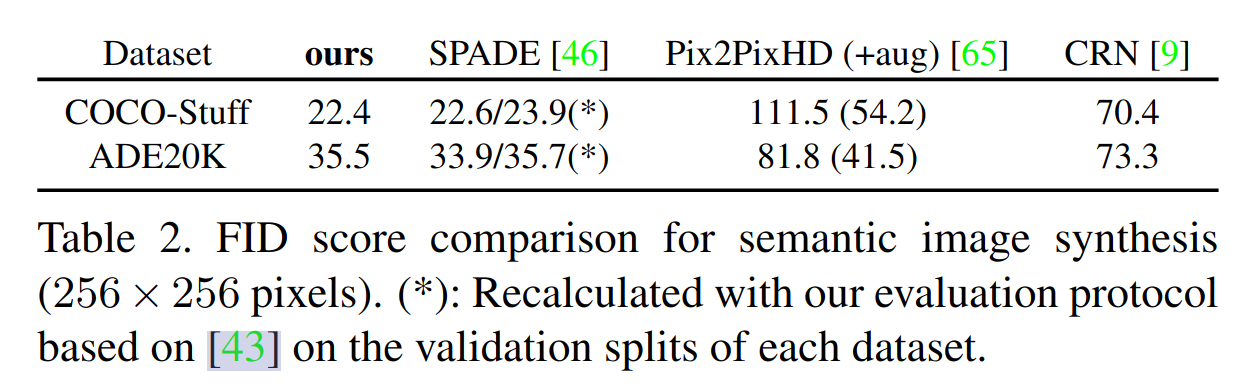
- semantic synthesis 任务
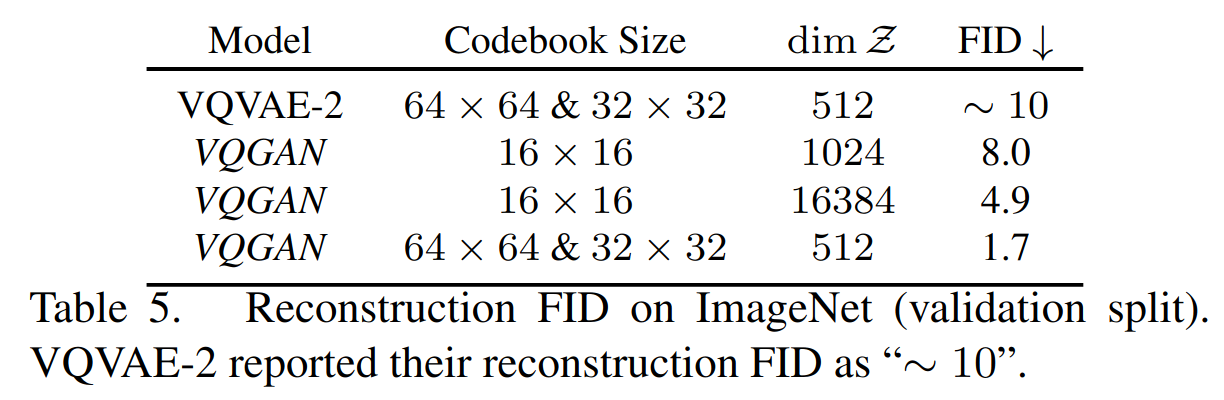
- 与 vqvae 的对比,在提供更大压缩的同时优于VQVAE-2(序列长度为256对比5120 = 322 + 642)
Thoughts
- 图像生成领域中结合 transformer 和 cnn 的经典作品,在取得较大压缩比的同时保证了较好的生成质量
- 二阶段中的 transformer 自回归思路看起来很合理,在图像领域自左到右,自上到下的自回归方式可能还有更好的解决方法
- GAN 的 loss 重要性消融实验本文没有太多涉及,可能效果提升相比于其他模块比较有限
















 927
927











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









