






Llama.cpp 是一种在 CPU 和 GPU 上高效运行大型语言模型(LLM)的好方法。不过,它的缺点是需要将模型转换为 Llama.cpp 支持的格式,目前这种格式是 GGUF 文件格式。在这篇博文中,你将学习如何将 HuggingFace 的模型(llama2 7b chat)转换为 GGUF 模型。
Llama.cpp 支持以下模型:
- LLaMA 🦙
- LLaMA 2 🦙🦙
- Falcon
- Alpaca
- GPT4All
- Chinese LLaMA / Alpaca and Chinese LLaMA-2 / Alpaca-2
- Vigogne (French)
- Vicuna
- Koala
- OpenBuddy 🐶 (Multilingual)
- Pygmalion 7B / Metharme 7B
- WizardLM
- Baichuan-7B and its derivations (such as baichuan-7b-sft)
- Aquila-7B / AquilaChat-7B
把hugggingface模型格式转换成gguf
在github上下载llama.cpp
git clone https://github.com/ggerganov/llama.cpp.git安装所需要的包
pip install -r llama.cpp/requirements.txt查看convert.py文件中的选项。
python llama.cpp/convert.py -h我的llama2-7b-chat目录是C:\apps\ml_model\llama2-7b-chat-hf
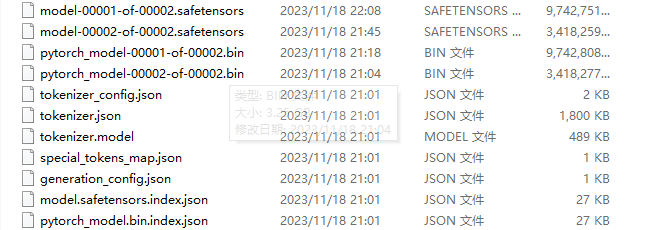
执行下面命令把safetensor格式转换成gguf格式
python convert.py C:\apps\ml_model\llama2-7b-chat-hf --outfile C:\apps\ml_model\llama2-7b-chat-hf\llama2-7b-chat_f16.gguf --outtype f16`C:\apps\ml_model\llama2-7b-chat-hf `: 模型目录的路径。
`C:\apps\ml_model\llama2-7b-chat-hf\llama2-7b-chat_f16.gguf`: 保存 GGUF 模型的输出文件名。
`q8_0`: 指定量化类型(在这种情况下,为量化的 8 位整数)。
outtype 有三个选项q8_0, f16, f32
在这种情况下,我们还通过设置 --outtype q8_0 将模型量化为 8 位。量化有助于提高推理速度,但可能会对模型质量产生负面影响。你可以使用 --outtype f16(16 位)或 --outtype f32(32 位)来保持原始质量
注意:如果你选用q8_0的话,后面的就不能再不能做量化了。
量化模型
进入llama.cpp. 用下面命令编译
mkdir build
cd build
cmake ..
cmake --build . --config Release把模型量化成q4
cd llama.cpp/build/bin && \
./quantize /Users/harry/Documents/apps/ml/llama-2-7b-chat/llama2-7b.gguf /Users/harry/Documents/apps/ml/llama-2-7b-chat/llama2-7b-q4_0.gguf q4_0如果是window,下载Releases · skeeto/w64devkit · GitHub

然后解压,运行w64devkit.exe后在llama.cpp目录下运行make命令。
运行下面命令做量化
quantize.exe /Users/harry/Documents/apps/ml/llama-2-7b-chat/llama2-7b.gguf /Users/harry/Documents/apps/ml/llama-2-7b-chat/llama2-7b-chat-q4_0.gguf q4_0最后你会发现下面几个模型文件。
llama2-7b-chat-q4_0.gguf 大小是3736.
之前大小是差不多是13G(两个safetensors文件)

测试
量化后测试一下的量化后的模型。在llama.cpp目录下运行下面命令
main -m C:\apps\ml_model\llama2-7b-chat-hf\llama2-7b-chat-q4_0.gguf --color --ctx_size 2048 -n -1 -ins -b 256 --top_k 10000 --temp 0.2 --repeat_penalty 1.1 -t 8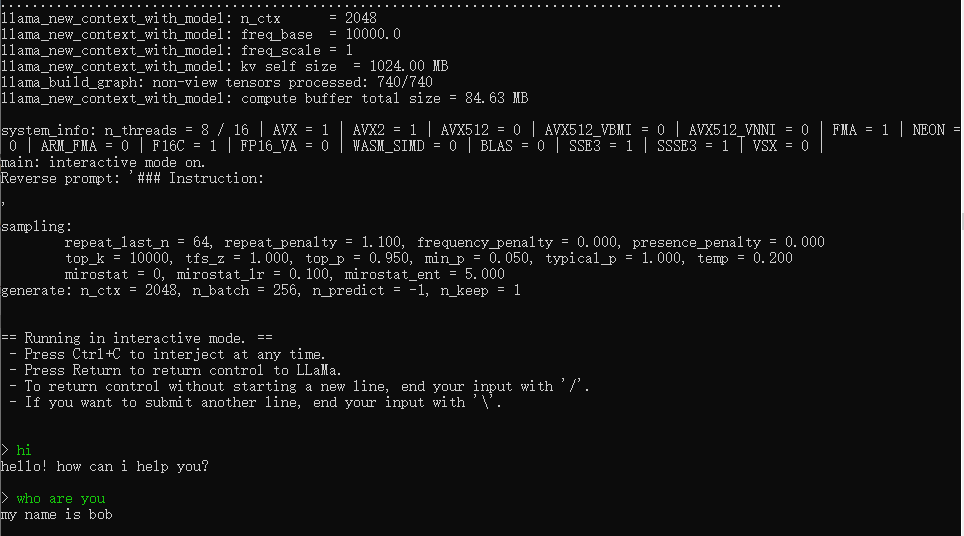


















 435
435

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











