






决策树在画图的时候通常是用来分类,因此从图像来看,一次又一次的分类就像数值一样,而在机器学习中,决策树就扮演了类似的角色,它就是一个分类器,给不同的特征分类,从而我们能够筛选出我们所想要的数据结果。
1.回归模型的评估
我们光看图像不能直接了解拟合数据是否多精确
所以在这里我们可以引出另外一个包,也是sklearn里的
import sklearn.metrics as sm
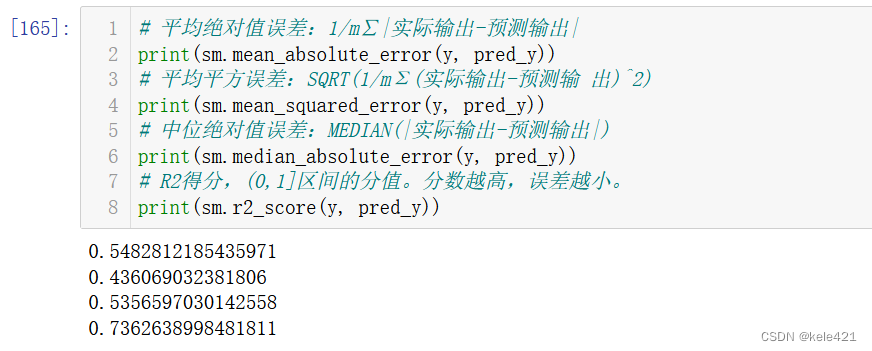
# 平均绝对值误差:1/m∑|实际输出-预测输出|
sm.mean_absolute_error(y, pred_y)
# 平均平方误差:SQRT(1/mΣ(实际输出-预测输出)^2)
sm.mean_squared_error(y, pred_y)
# 中位绝对值误差:MEDIAN(|实际输出-预测输出|)
sm.median_absolute_error(y, pred_y)
# R2得分,(0,1]区间的分值。分数越高,误差越小。
sm.r2_score(y, pred_y)
前三个方法我们能算出其大概的误差,大抵是求得绝对值的实际-预测后进行求和后再处于个数或者直接求得其中的中位数这样,求得的数据基本类似。
而最后一个方法就相当于给这个模型计算一下它的算法成功率,计算他的分数,我们可以看到这里大概是0.73,可以理解为73分,大概合格的水准,如果想要分数更高,就需要其他的线性模型方法了。
2.模型封装
我们经常使用的model一般我们会在regression之类的包里导入,但如果我们自己想要定义一个特殊的模型关系的时候,我们可以先进行一定的数据计算,描述好x与y的关系,然后对于这个model进行存储,这个操作就是模型封装。
封装后当我们想要调用的时候我们就可以直接用with open或者其他的打开方式来调用这个model,这对于我们机器学习的编码可以省去很多操作
import numpy as np
import sklearn.linear_model as lm
import matplotlib.pyplot as mp
import pickle
x, y = np.loadtxt('single.txt',
delimiter=',', unpack=True)
# 训练线性回归模型
model = lm.LinearRegression()
model.fit(x.reshape(-1, 1), y)
pred_y = model.predict(x.reshape(-1, 1))
# 评估模型的性能
import sklearn.metrics as sm
print(sm.mean_absolute_error(y, pred_y))
print(sm.mean_squared_error(y, pred_y))
print(sm.median_absolute_error(y, pred_y))
print(sm.r2_score(y, pred_y))
# 保存模型
with open('linear.pkl', 'wb') as f:
pickle.dump(model,f)
print('dump success.')
类似操作就是如此
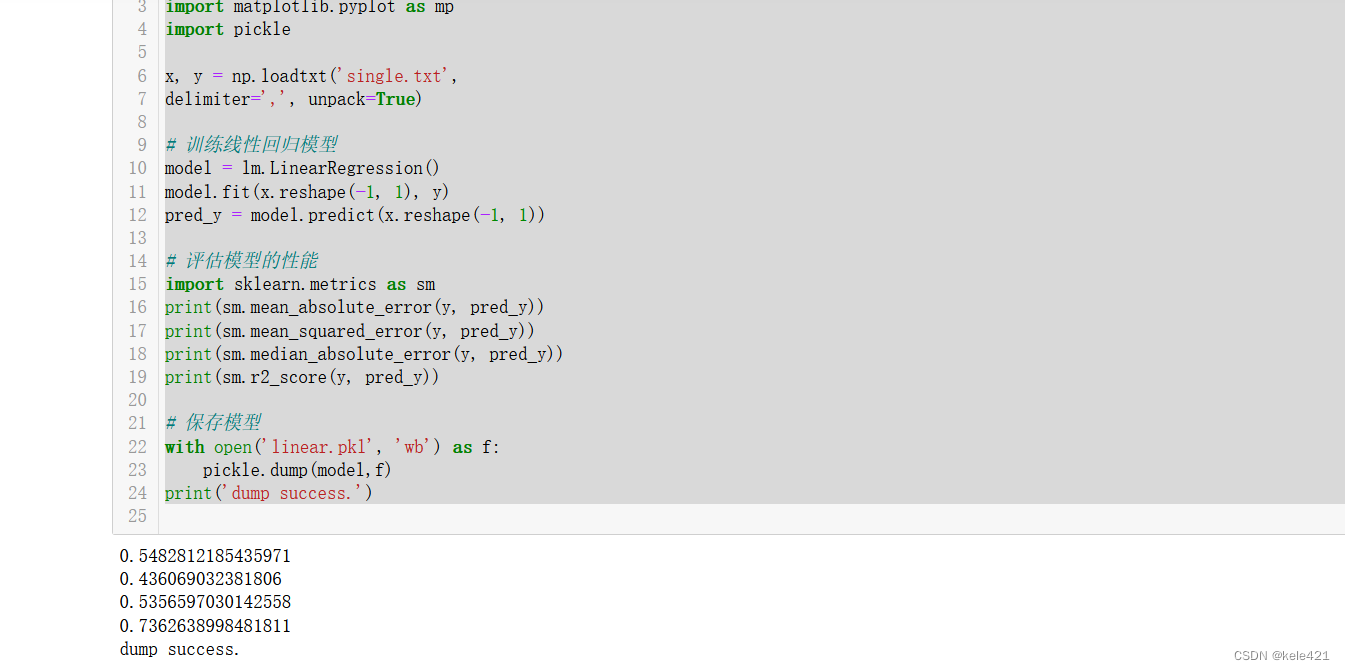
运行出现dumpsuccess就说明保存成功了下次就可以直接调用了
3.岭回归
岭回归实际就是线性回归的一种变式,线性回归的时候我们往往会根据一大堆散点的数据来进行数据的拟合,但是数据中一般都没有经过降噪平滑之类的操作,因此有些数据点会跟大多数数据点分离太开,这就会导致数据拟合的时候线性模型会受到一定的影响。
而岭回归则可以最小程度放弃部分嘈杂信息,然后让数据模型能够更加平滑,使得回归系数能够更加实际可靠
import numpy as np
import sklearn.linear_model as lm
import matplotlib.pyplot as mp
x, y = np.loadtxt('abnormal.txt',
delimiter=',', unpack=True)
# 训练线性回归模型
model = lm.LinearRegression()
model.fit(x.reshape(-1, 1), y)
pred_y = model.predict(x.reshape(-1, 1))
# 绘制这些点
mp.figure('Ridge Regression', facecolor='lightgray')
mp.title('Ridge Regression', fontsize=18)
mp.grid(linestyle=':')
mp.scatter(x, y, s=80, color='dodgerblue',
label='Sample Points')
mp.plot(x, pred_y, color='orangered',
label='Regression Line')
print(sm.r2_score(y, pred_y))
# 基于岭回归,训练模型
model = lm.Ridge(
100, fit_intercept=True, max_iter=10000)
model.fit(x.reshape(-1,1), y)
pred_y = model.predict(x.reshape(-1, 1))
mp.plot(x, pred_y, color='blue',
label='Ridge Regression Line')
print(sm.r2_score(y, pred_y))
mp.legend()
mp.show()
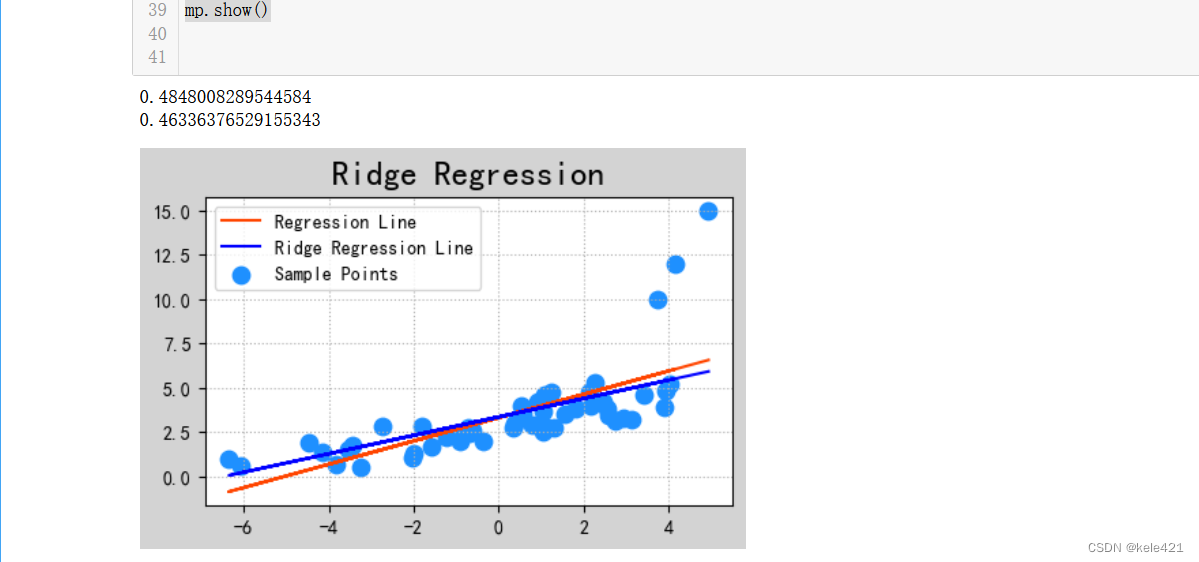
从图中我们可以很容易看出普通线性回归模型和岭回归的区别,右上方的点就是我上文所说到的嘈杂的点,而橙色的线性回归受到上方的点的影响而斜率变大,比蓝色的上翘一点,而蓝色的岭回归就更加实际一点,只根据大多数数据的趋势绘制线性模型。
4.多项式回归
多项式回归其实跟线性模型的思路差距不是很大,只在于其算式不是y=w1x+w0了而是由许多个随机系数的x^n,x^n-1这样的变量组成的算式,也因此其模型不是一条直线而是一条曲线了。
曲线的话其实直观来看更能拟合那些分散的数据,所以其模型评估一般都会分数高于普通的线性回归。不过由于我们使用模型的时候要多出那么多个特征,因此在使用多项式回归的时候我们先要扩展特征然后再使用线性模型。
import numpy as np
import sklearn.linear_model as lm
import matplotlib.pyplot as plt
import sklearn.metrics as sm
import sklearn.preprocessing as sp
import sklearn.pipeline as pl
x, y = np.loadtxt('single.txt',
delimiter=',', unpack=True)
# 基于数据管线,实现多项式回归模型训练
# 1.扩展特征 2. 把扩展之后的样本交给线性回归模型
model = pl.make_pipeline(
sp.PolynomialFeatures(10),
lm.LinearRegression())
model.fit(x.reshape(-1, 1), y)
pred_y=model.predict(x.reshape(-1,1))
print(sm.r2_score(y, pred_y))
# 画出多项式曲线
px = np.linspace(x.min(), x.max(), 500)
py = model.predict(px.reshape(-1, 1))
# 绘制这些点
plt.figure('Linear Regression', facecolor='lightgray')
plt.title('Linear Regression', fontsize=18)
plt.grid(linestyle=':')
plt.scatter(x, y, s=80, color='dodgerblue',
label='Sample Points')
plt.plot(px, py, color='orangered',
label='Regression Line')
plt.legend()
plt.show()
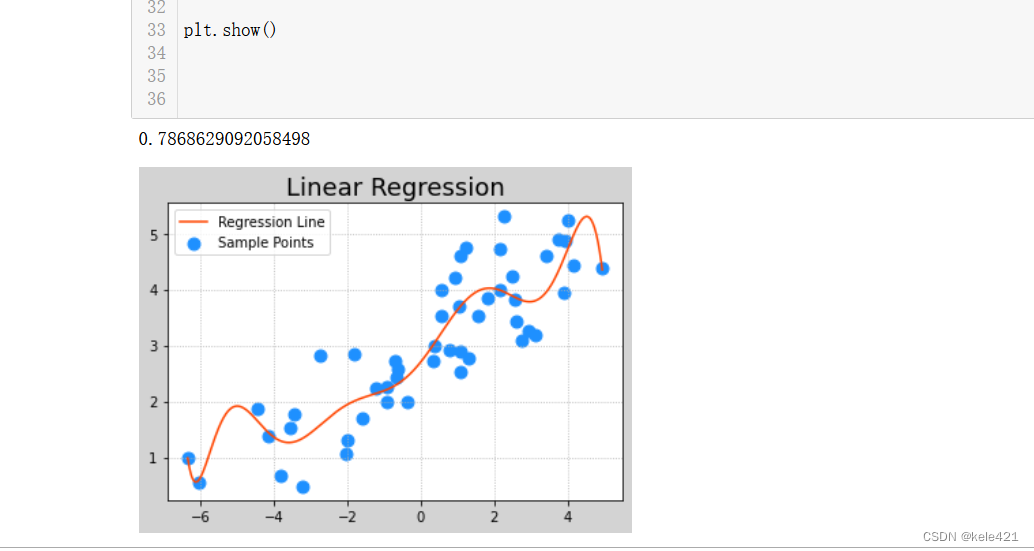
从数值上看,0.78就比之前的0.73要高了些,我们要注意的是这里 sp.PolynomialFeatures(10)中的10,就说明我们用了最高x的10次方这样,但是太高的话比如我这里调成20
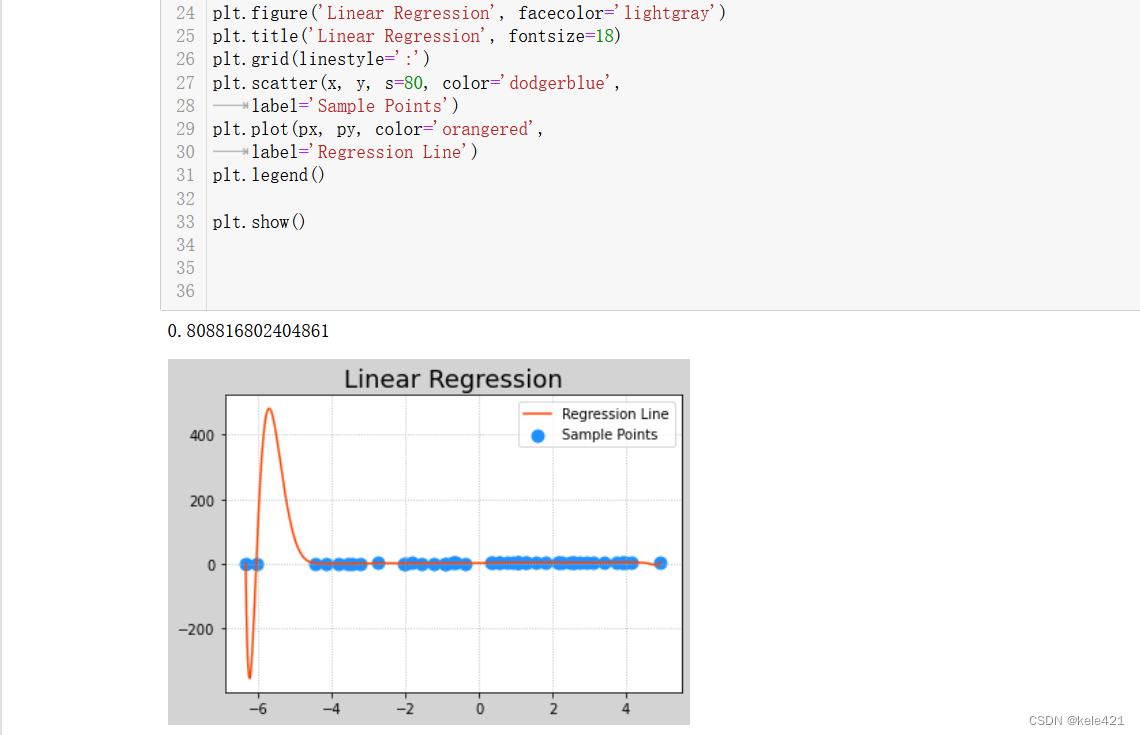
这样从数据评估角度确实又高了,但是前面那一段误差甚至到了400,-200这样的程度,为了防止过拟合,也尽量不要只看测试的评估结果,要看看数据模型呈现的样子是否适合我们来使用。
5.决策树来看波士顿房价
这里就引出我一开始介绍的决策树模型了
对于波士顿房价的影响,有许许多多的特征,地域,犯罪率,天气等等,对于这种大规模,多特征数据,我们就要借用决策树模型来进行分类,知道哪些特征的影响力大,而那些对结果影响力小的特征则是可以忽略不计的,这样就可以省去许多计算机计算时间,跟岭回归能忽略嘈杂数据有异曲同工之妙
import numpy as np
import sklearn.datasets as sd
import sklearn.tree as st
import sklearn.utils as su
import sklearn.metrics as sm
import matplotlib.pyplot as mp
# 加载数据
boston = sd.load_boston()
print(boston.data.shape)
print(boston.target.shape)
print(boston.feature_names)
names = boston.feature_names
# 打乱数据集,划分测试集 与 训练集
x, y = su.shuffle(
boston.data, boston.target, random_state=7)
train_size = int(len(x) * 0.8)
train_x, test_x, train_y, test_y = \
x[:train_size], x[train_size:], \
y[:train_size], y[train_size:]
# 使用训练集训练, 使用测试集测试
model = st.DecisionTreeRegressor(max_depth=4)
model.fit(train_x, train_y)
#
pred_test_y = model.predict(test_x)
print(sm.r2_score(test_y, pred_test_y))
print(sm.mean_absolute_error(test_y, pred_test_y))
# 输出特征重要性
dt_fi = model.feature_importances_
print(dt_fi)
mp.figure('Feature Importance', facecolor='lightgray')
mp.subplot(211)
mp.title('DT Feature Importance', fontsize=16)
mp.grid(linestyle=':', axis='y')
x = np.arange(dt_fi.size)
sorted_indices = dt_fi.argsort()[::-1]
mp.xticks(x, names[sorted_indices])
mp.bar(x, dt_fi[sorted_indices], 0.8,
color='dodgerblue', label='DT Feature Importances')
mp.legend()
mp.tight_layout()
# 基于正向激励,训练模型
import sklearn.ensemble as se
model = se.AdaBoostRegressor(
model, n_estimators=400, random_state=7)
model.fit(train_x, train_y)
pred_test_y = model.predict(test_x)
print(sm.r2_score(test_y, pred_test_y))
print(sm.mean_absolute_error(test_y, pred_test_y))
ada_fi = model.feature_importances_
mp.subplot(212)
mp.title('AdaBoost Feature Importance', fontsize=16)
mp.grid(linestyle=':', axis='y')
sorted_indices = ada_fi.argsort()[::-1]
mp.xticks(x, header[sorted_indices])
mp.bar(x, ada_fi[sorted_indices], 0.8,
color='orangered', label='AdaBoost Feature Importances')
mp.legend()
mp.tight_layout()
mp.show()

我们先看DT feature这张图,这里运用了决策树模型,将不同的特征导致最终结果的占比写了出来,我们可能看不懂这里x轴的写法 ,sorted_indices = dt_fi.argsort()[::-1]就是一种可以将数据从小到大排列的一种方法,而后面加了[::-1]就是输出一串可以让这些特征从大到小的序列号,然后将这串数字导入xticks里,所以我们能更直观的看出最能影响房价的三个特征RM,LSTST,DIS.
有兴趣的话可以看看下面这串Adaboost根据权重的加强分类器,n_estimators=400, random_state=7分别代表了这里的分类器设定为400,而随机打乱的数据为random_state7,数据打乱是为了防止数据在放入模型的时候因为原来设定原因从高到低或者从低到高这种有规律的方式排列,影响最终准确率,而设定个随机种子就可以保证之后使用的时候还是根据这样的随机打乱程度。重点还是在adaboost身上,它也是决策树的一种,但是它有正向激励措施,可以使得最终误差更小,从最后数据就可以得知,决策树的评估结果也只有0.82.而adaboost则可以到达0.90得准确率,因此adaboost的模型更好一点。















 3330
3330











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









