







 本文介绍了决策树在特征选择时常用的评估指标,如熵、基尼不纯度和分类误差率,并通过高尔夫球案例解释了它们的含义和作用。此外,文章探讨了信息增益和信息增益比的概念,以及它们在防止过拟合中的作用。在风控和信贷模型中,决策树的特性有助于识别坏用户,但可能不适合所有用户排序。
本文介绍了决策树在特征选择时常用的评估指标,如熵、基尼不纯度和分类误差率,并通过高尔夫球案例解释了它们的含义和作用。此外,文章探讨了信息增益和信息增益比的概念,以及它们在防止过拟合中的作用。在风控和信贷模型中,决策树的特性有助于识别坏用户,但可能不适合所有用户排序。
摘要:目前主要的决策树算法有ID3、C4.5和CART,在各种不同的软件选择使用决策数时,也有分裂依据的指标选择,主要包括熵(Entropy)、基尼不纯度(Gini impurity)和分类误差率(Misclassification);除了这些指标,C4.5和ID3在对比不同剪枝方法时还会有信息增益和信息增益比。本文以二分类问题为例,主要介绍不同指标的含义、这些指标可以衡量分枝好坏的原因(数学含义及实际含义)以及使用时的注意事项;除此之外,也会介绍信息增益和信息增益比的区别。
首先,构建一个决策树情景,使用网络上耳熟能详的案例(高尔夫球案例):
Table1. PLAY GOLF DATASET
| ID | OUTLOOK | TEMPERATURE | HUMIDITY | WINDY |
PLAY |
|---|---|---|---|---|---|
| 1 | SUNNY | 85 | 85 | FALSE | NO |
| 2 | SUNNY | 80 | 90 | TRUE | NO |
| 3 | OVERCAST | 83 | 78 | FALSE | YES |
| 4 | RAIN | 70 | 96 | FALSE | YES |
| 5 | RAIN | 68 | 80 | FALSE | YES |
| 6 | RAIN | 65 | 70 | TRUE | NO |
| 7 | OVERCAST | 64 | 65 | TRUE | YES |
| 8 | SUNNY | 72 | 95 | FALSE | NO |
| 9 | SUNNY | 69 | 70 | FALSE | YES |
| 10 | RAIN | 75 | 80 | FALSE | YES |
| 11 | SUNNY | 75 | 70 | TRUE | YES |
| 12 | OVERCAST | 72 | 90 | TRUE | YES |
| 13 | OVERCAST | 81 | 75 | FALSE | YES |
| 14 | RAIN | 71 | 80 | TRUE | NO |
目标变量为是否打高尔夫(PLAY);
可用变量有天气(OUTLOOK)、气温(TEMPERATURE)、相对湿度(HUMIDITY)和是否有风(WINDY)。
决策树在做特征选择时,依据限制条件,遍历所有特征及所有特征的分法,计算不同分法带来的信息增益或信息增益比,选择满足阈值条件的使信息增益(比)最大的分法。限制条件的类型包含叶结点的样例个数,分枝的枝数等。一般而言,离散变量直接按照离散值做切分,连续变量按照分割值的中位数进行切分。
以高尔夫的例子对数据进行查看,Fig1显示不同的类别在特征outlook和humidity内是如何分布的:
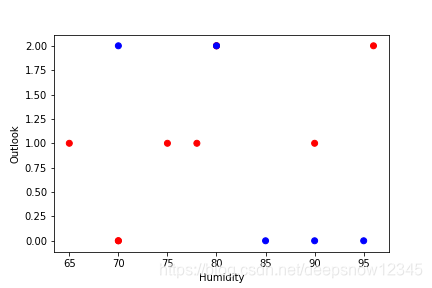
Fig1.Scatterplot of golf playing
注:图中红色代表class为Yes,蓝色代表class为No; Outlook中值0为sunny,值1为overcast,值2为rainy;rainy中h
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2145
2145

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









