






★ 启动Anaconda虚拟机流程:
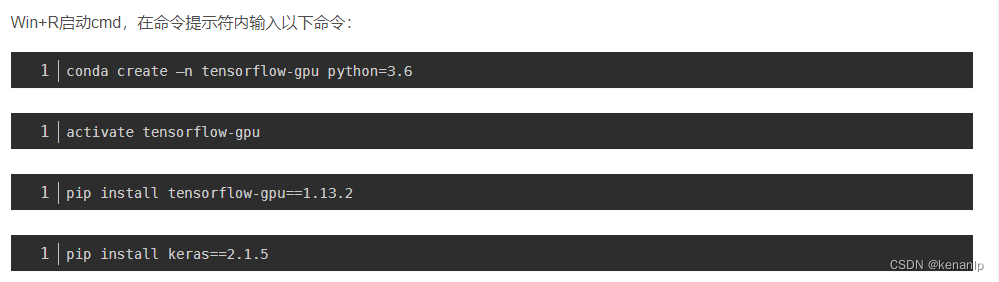
★ 使用Labelme工具制作样本流程:
1、激活tensorflow-gpu-2.4.0虚拟机
2、执行labelme指令,启动UI进行图片标注
3、执行json_to_dataset.py脚本,将json图片转化成label可以使用的图片(参考工程:语义分割\unet-pytorch-main)
4、执行yg2uent.py脚本,将图片划分为训练集与验证集,并生成train.py训练时读取的txt文件
★ 手动执行流程:
1、cmd执行labelme指令,打开QT,选择图片,进行制作,保存为json文件
2、进入json文件路径,cmd执行labelme_json_to_dataset x.json,生成x.json文件夹(output文件夹)
3、将原图与x.json文件,存放于(before文件夹)
4、执行get_jpg_and_png脚本















 2312
2312











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









