







背景
人脸关键点检测
人脸关键点检测也称为人脸关键点检测、定位或者人脸对齐,是指给定人脸图像,定位出人脸面部的关键区域位置,包括眉毛、眼睛、鼻子、嘴巴、脸部轮廓等和人脸检测类似,由于受到姿态和遮挡等因素的影响,人脸关键点检测也是一个富有挑战性的任务。
把关键点的集合称作形状(shape),形状包含了关键点的位置信息,而这个位置信息一般可以用两种形式表示,第一种是关键点的位置相对于整张图像,第二种是关键点的位置相对于人脸框(标识出人脸在整个图像中的位置)。把第一种形状称作绝对形状,它的取值范围是[0,img_width]或者[0,img_height];第二种形状称作相对形状,它的取值范围是0到1。这两种形状可以通过人脸框来相互转换。

人脸关键点的检测有许多重要的应用场景。
-
人脸姿态对齐:人脸识别等算法都需要对人脸的姿态进行对齐从而提高模型的精度。
-
人脸美颜与编辑:基于关键点可以精确分析脸型、眼睛形状、鼻子形状等,从而对人脸的特定位置进行修饰加工,实现人脸特效美颜,贴片等娱乐功能。
-
人脸表情分析与嘴型识别:基于关键点可以对人的面部表情进行分析,从而用于互动娱乐,行为预测等场景。
人脸关键点检测方法分类:
-
基于ASM(Active Shape Model) 和 AAM (Active Appearnce Model)的传统方法
-
基于级联形状回归的方法
-
基于深度学习的方法
人脸关键点的里程碑算法如下。
1、1995 年,Cootes 的 ASM(Active Shape Model)。
2、1998 年,Cootes 的 AAM(Active Appearance Model) 算法。
3、2006 年,Ristinacce 的 CLM(Constrained Local Model)算法。
4、2010 年,Rollar 的 cascaded Regression 算法。
5、2013 年,Sun 开创深度学习人脸关键点检测的先河,首次将 CNN 应用到人脸关键点定位上。
目前,应用最广泛且效果精度最高的是基于深度学习的方法,因此重点记录关于深度学习在人脸关键点检测算法。
人脸姿态估计
人脸姿态估计算法,主要用以估计输入人脸块的三维欧拉角。一般选取的参考系为相机坐标系,即选择相机作为坐标原点。姿态估计可用于许多业务场景,比如在人脸识别系统的中,姿态估计可以辅助进行输入样本的筛选(一般人脸要相对正脸才进行召回和识别);在一些需要人脸朝向作为重要业务依据的场景中,人脸姿态算法也是不可或缺的,比如疲劳驾驶产品中驾驶员的左顾右盼检测。
1、准备工作
安装昇思MindSpore
conda create --name SynergyNet
conda activate SynergyNet
pip install MindSpore 1.8, Opencv, Scipy, Matplotlib, Cython准备数据
300W-LP数据集:
https://drive.google.com/file/d/1YVBRcXmCeO1t5Bepv67KVr_QKcOur3Yy/view?usp=sharing
https://github.com/cleardusk/3DDFA
AFLW2000-3D数据集:
https://drive.google.com/file/d/1SQsMhvAmpD1O8Hm0yEGom0C0rXtA0qs8/view?usp=sharing
解压后放在根目录下,格式如下:
${root_dir}
|--3dmm_data #training dataset
|--train_aug_120x120
|--AFWFlip_AFW_1051618982_1_0_1.jpg
|--...
|--BFM_UV.npy
|--u_exp.npy
|--...
|--aflw2000_data #testing dataset
|--AFLW2000-3D_crop
|--image00002.jpg
|--...
|--eval
|--AFLW2000-3D.pose.npy
|--...
|--AFLW2000-3D_crop.list2、算法模型
Representation Cycle
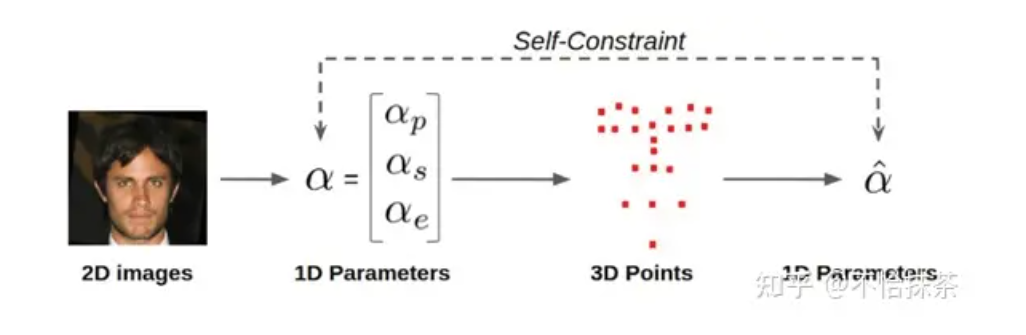
整体框架创建了一个Representation Cycle。首先,图像编码器和独立解码器从人脸图像输入中回归1D参数。然后,根据参数构造三维网格并细化提取的三维地标,这是将一维参数表示转换为三维点表示的前进方向。然后,反向表示方向采用一个地标到3dmm模块,将表示从3D点切换回1D参数。因此形成了一个表示循环(图4),我们将一致性损失最小化以方便训练。
_3D_attr, _3D_attr_GT, avgpool = self.I2P(x,target)
vertex_lmk1 = self.reconstruct_vertex_62(_3D_attr)
vertex_GT_lmk = self.reconstruct_vertex_62(_3D_attr_GT)
# global point feature
point_residual = self.forwardDirection(vertex_lmk1, avgpool, _3D_attr[:, 12:52], _3D_attr[:, 52:62])
# low-level point feature
vertex_lmk2 = vertex_lmk1 + 0.05 * point_residual
_3D_attr_S2 = self.reverseDirection(vertex_lmk2)
3D Morphable Models (3DMM)
3DMM,即三维可变形人脸模型,是一个通用的三维人脸模型,用固定的点数来表示人脸。它的核心思想就是人脸可以在三维空间中进行一一匹配,并且可以由其他许多幅人脸正交基加权线性相加而来。我们所处的三维空间,每一点(x,y,z),实际上都是由三维空间三个方向的基量,(1,0,0),(0,1,0),(0,0,1)加权相加所得,只是权重分别为x,y,z。
转换到三维空间,道理也一样。每一个三维的人脸,可以由一个数据库中的所有人脸组成的基向量空间中进行表示,而求解任意三维人脸的模型,实际上等价于求解各个基向量的系数的问题。人脸的基本属性包括形状和纹理,每一张人脸可以表示为形状向量和纹理向量的线性叠加。
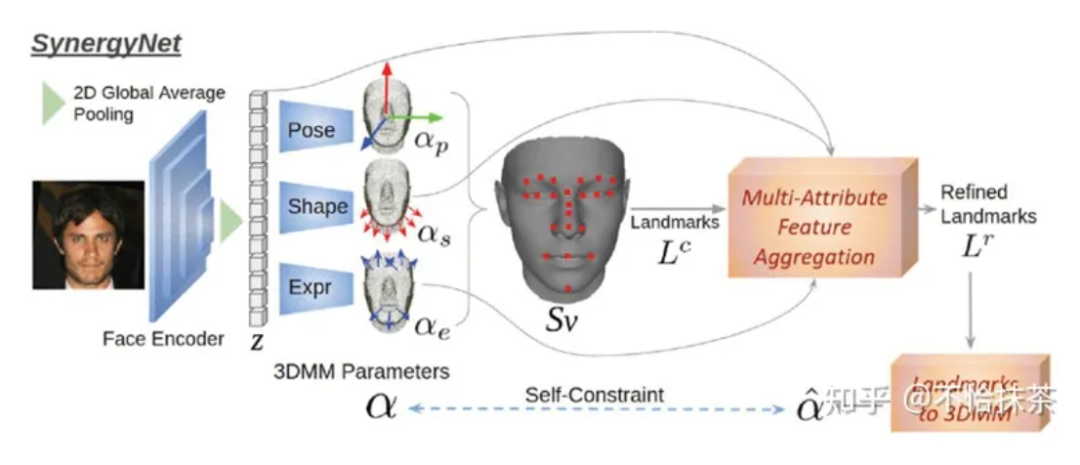
SynergyNet的特征提取部分同3DDFA-V2网络一样,采用Mobilenet-V2作为backbone,用来进行提取输入图像的人脸特征,并使用全连接(FC)层作为解码器,以预测3DMM参数。将解码器分为几个head,分别预测姿势,形状和表情,最后得到62维的人脸参数。
self.feature_extractor = MobileNetV2()
self.last_channel = make_divisible(last_channel * max(1.0, alpha), round_nearest)
self.num_ori = 12
self.num_shape = 40
self.num_exp = 10
# building classifier(orientation/shape/expression)
self.classifier_ori = nn.SequentialCell(nn.Dropout(0.2),
nn.Dense(self.last_channel, self.num_ori),)
self.classifier_shape = nn.SequentialCell(
nn.Dropout(0.2), nn.Dense(self.last_channel, self.num_shape),)
self.classifier_exp = nn.SequentialCell(
nn.Dropout(0.2),
nn.Dense(self.last_channel, self.num_exp),)
self.pool = nn.AdaptiveAvgPool2d(1)
x = self.feature_extractor(x)
pool = self.pool(x)
x = pool.reshape(x.shape[0], -1)
avgpool = x
x_ori = self.classifier_ori(x)
x_shape = self.classifier_shape(x)
x_exp = self.classifier_exp(x)
concat_op = ops.Concat(1)
_3D_attr = concat_op((x_ori, x_shape, x_exp))
_3D_attr_GT = target
return _3D_attr, _3D_attr_GT, avgpool3DMM to Refined 3D Landmarks
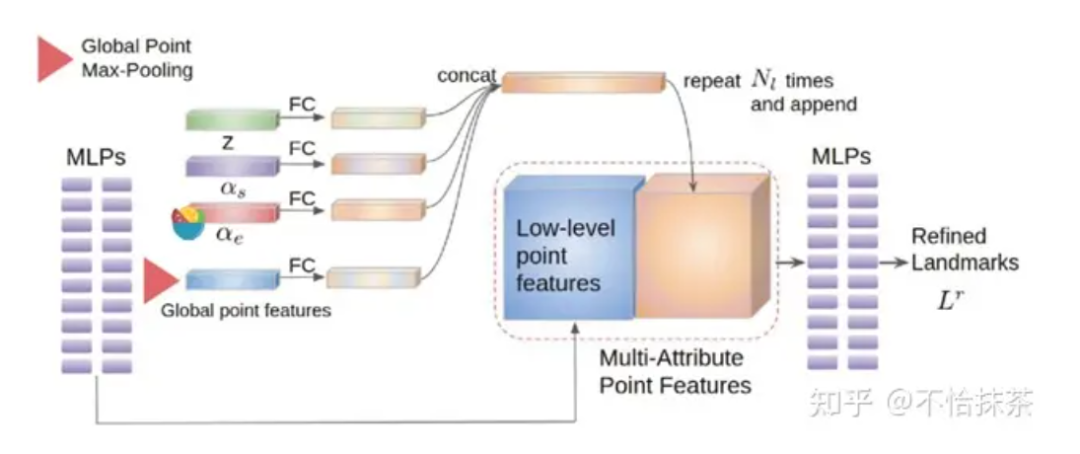
采用了一个聚合多属性特征的细化模块,以产生更精细的landmark 。landmark可以看作是一系列3D点。
细化模块不是单独使用LC进行改进,而是采用多属性特征聚合(MAFA),包括输入图像和3DMM semantics,可提供来自不同域的信息。例如,形状包含较薄/较厚的面部的信息,并且表达式包含眉毛或口腔运动的信息。因此,这些信息可以帮助回归更优质的地标结构。MLPs通常用于从结构化点提取特征,在bottleneck处,采用global point max-pooling获得全局点特征。然后使用mlp解码器对每个点的属性进行回归。
# 3DMM Img
avgpool = other_input1
expand_dims = ops.ExpandDims()
avgpool = expand_dims(avgpool, 2)
avgpool = self.tile(avgpool, (1, 1, self.num_pts))
shape_code = other_input2
shape_code = expand_dims(shape_code, 2)
shape_code = self.tile(shape_code, (1, 1, self.num_pts))
expr_code = other_input3
expr_code = expand_dims(expr_code, 2)
expr_code = self.tile(expr_code, (1, 1, self.num_pts))
concat_op = ops.Concat(1)
cat_features = concat_op([point_features, global_features_repeated, avgpool, shape_code, expr_code])
Refined Landmarks to 3DMM
进一步构建了一个地标到3DMM模块,利用地标整体特征从细化的landmark回归3DMM参数。Landmark-to-3dmm模块还包含一个MLP解码器来提取高维点特征,并使用global point max-pooling来获得整体landmark特征。之后,分别用FC层将整体landmark特征转换为3DMM参数,包括姿势、形状和表情。
global_features = self.max_pool(out)
# Global point feature
out_rot =
self.relu(ops.Squeeze(-1)(self.bn6_1(ops.ExpandDims()(self.conv6_1(global_features), -1))))
out_shape =
self.relu(ops.Squeeze(-1)(self.bn6_2(ops.ExpandDims()(self.conv6_2(global_features), -1))))
out_expr =
self.relu(ops.Squeeze(-1)(self.bn6_3(ops.ExpandDims()(self.conv6_3(global_features), -1))))
concat_op = ops.Concat(1)
out = concat_op([out_rot, out_shape, out_expr])
squeeze = ops.Squeeze(2)
out = squeeze(out)代码地址:https://gitee.com/gai-shaoyan/mind3d
参考文献
[1] C. -Y. Wu, Q. Xu and U. Neumann, "Synergy between 3DMM and 3D Landmarks for Accurate 3D Facial Geometry," 2021 International Conference on 3D Vision (3DV), 2021, pp. 453-463, doi: 10.1109/3DV53792.2021.00055.MindSpore的SynergyNet背景


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









