







与本章节相关的一些关键术语
graph
我们知道, 在tensorflow里,模型是以compuatation graph的形式存在,作为训练和inference的载体。下面简称graph。
graph的组成:- node:即定义一个具体的计算操作,比如Add, MatMul,Conv等。每个node可以定义多种属性 ,包括它的计算操作(叫做Op),输入、输出数据类型,与计算相关的参数设置,比如Convolution时需要的padding\stride.
- tensor:是一个node输出的计算结果,比如MatMul计算完成后,输出一个多维的张量,就是一个tensor,tensor可以作为下一个node的数据输入。
edge:连接各个node, 目前有两种edege:
- data_flow: 负责在node之间传递tensor数据
- control_flow: 负责确定node之间的执行依赖关系
多个node和他们之间的edge连接,就构成了一个graph,完整描述我们定义的神经网络模型。
GraphDef
用于定义graph的ProtoBuf协议格式,因其文本属性,可以将graph以这种格式保存至文本文件,实现训练模型的保存。也可以很方面的在不同设备、软件模块之间传输和解析GraphDef。另外,tensorboard可以读取GraphDef格式保存的文本文件,显示graph。
session
运行graph的主体。负责创建和管理graph及其所需的运行设备(device)资源。
device
运行graph的硬件资源,属于session,如本地的gpu device/ cpu device。
Executor
graph的具体执行者,属于session,当我们把graph分割到多个device执行的时候,也会生成对应的多个Executor实例。
模型的生成总体流程
graph的生成,源自通过python API中对graph中nodes的定义。
一般来讲,我们通过python API这样开始训练一个model:
- 定义graph和其中的node
- 创建session去Run这个graph
Graph的生成总体流程如下图:
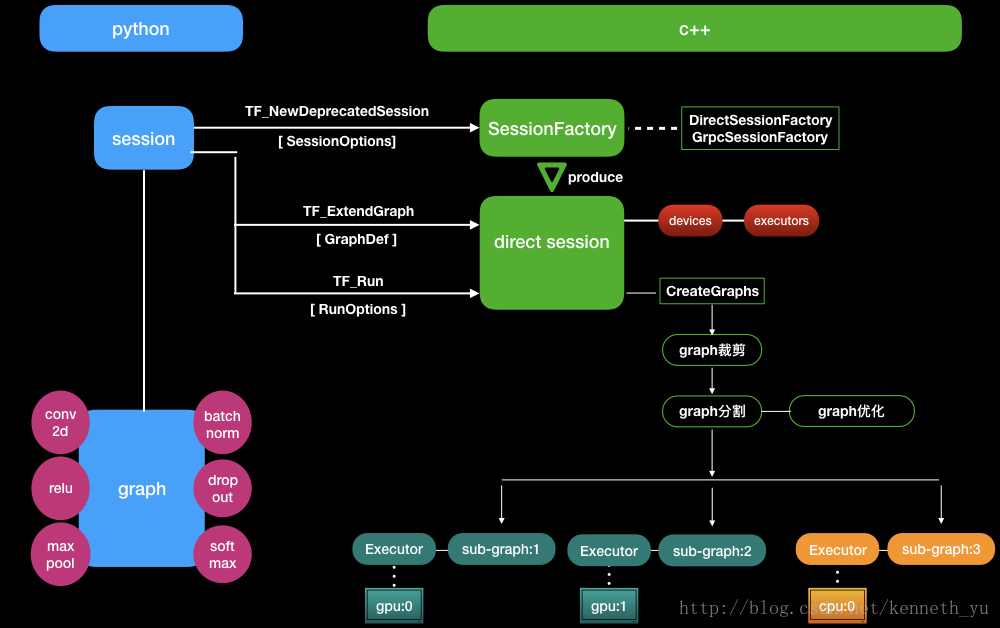
graph的构建、分割、优化(c++部分)
graph的执行是在c++代码中完成的,在执行前,需要对graph进行构建、分割、优化。
而在开始构建一个graph之前,我们必须先创建一个session,作为运行这个graph的主体。
Session的创建
python API调用c++ API , 创建合适的session,用于运行graph。
运行graph的session有两类:
- DirectSession:使用本地的devic作为运行资源,如本机中的gpu、cpu。可以将graph分割、分布到多个devices上运行,实现devices之间的并发执行,同样可以实现data parallelism/ model parallelism 这两种分布式训练。配置比较简单,我们主要结合这种session进行举例和讲解。
- GrpcSession:使用远程主机的device作为计算资源,grpc作为远程调用的机制。使用cluster进行分布式训练的场景就需要使用这种session。实现上,graph按照worker分割的原理,类似于DirectSession按照device分割的原理, 每个worker上sub-graph的执行者也是Executor,这里不探讨。
为方便感兴趣的朋友进一步查看代码,列出主要函数调用路径:
full_graph实例的创建和优化
python部分定义好的graph,通过TF_ExtendGraph()接口, 将graph以protobuf定义的 GraphDef格式,传递到c++ session中。
同步graph有两种场景:
- graph增量式更新后,主动同步到c++ session;
- 每次session run时,都会先同步graph到c++ session,以保证run的是最新的graph;
主要函数调用路径:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1183
1183











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









