







深度伪造视频检测新突破:视频级混合增强与时空适配器技术
一、研究背景与核心挑战
深度伪造技术的快速发展在带来便利的同时,也引发了隐私泄露、虚假信息传播等安全问题。当前深度伪造视频检测面临三大核心挑战:
- 时间特征复杂性:不同伪造算法产生的时间伪影(如帧间不一致)差异大,如何提取通用时间特征提升模型泛化性?
- 时空特征失衡:传统模型常依赖单一特征(如空间纹理或时间运动),难以平衡学习时空联合特征。
- 效率瓶颈:视频处理计算成本高,如何在保证精度的同时降低模型复杂度?
二、关键发现:面部特征漂移(FFD)现象
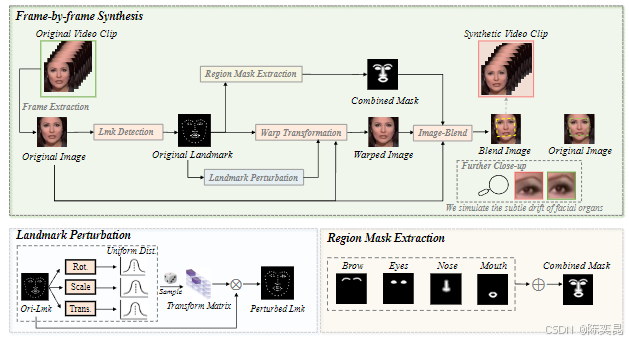
通过分析真实伪造视频,团队发现一种未被充分研究的时间伪影——面部特征漂移(Facial Feature Drift, FFD):即使相邻帧外观相似,眼、鼻等面部器官的位置和形状仍存在细微不连贯(如图1)。这一现象源于逐帧换脸过程中生成模型的随机性,导致帧间特征不一致,是跨算法伪造视频的共性缺陷。
三、核心技术:视频级混合增强与时空适配器

1. 视频级混合数据(Video-level Blending, VB):模拟FFD增强泛化性
- 技术原理:通过对视频帧的面部器官(眼、眉、鼻、口)进行仿射变换(旋转、缩放、平移),生成包含FFD伪影的合成帧。具体步骤:
- 关键点扰动:对原始帧面部关键点添加随机扰动,生成变形后的关键点坐标;
- 区域掩码提取:基于关键点距离生成软掩码,控制扰动区域边界;
- 动态融合:将变形区域与原始帧融合,生成包含自然过渡的合成帧(如图2)。
- 优势:作为“困难负样本”,迫使模型学习跨算法的通用时间特征,解决传统数据合成仅关注空间伪影的局限。
2. 时空适配器(Spatiotemporal Adapter, StA):轻量级时空特征融合
- 设计思路:利用预训练图像模型(如CLIP、ViT)的强大空间表征能力,通过插件式适配器赋予其时间建模能力,避免从头训练复杂视频模型。
- 架构细节:
- 双流3D卷积:空间分支采用(1, N, N)核提取单帧细节,时间分支采用(N, 1, 1)核捕捉跨帧运动,支持多尺度特征(3x3, 5x5, 7x7);
- 交叉注意力机制:融合时空特征的高层关联,增强互补性(如空间光照不一致与时间动作不连贯的联合检测);
- 参数高效训练:仅更新适配器模块,冻结 backbone 参数,训练成本降低80%以上(如图3)。
四、实验验证:跨域泛化能力显著提升
1. 数据集与评估协议
- 训练数据:基于FaceForensics++ (FF++) 数据集,测试覆盖Celeb-DF-v2、DFDC、WildDeepfake等7个跨域数据集及6种最新伪造技术(如Synthesia、Inswap)。
- 核心指标:视频级AUC、准确率(Acc)、等错误率(EER)。
2. 关键结果
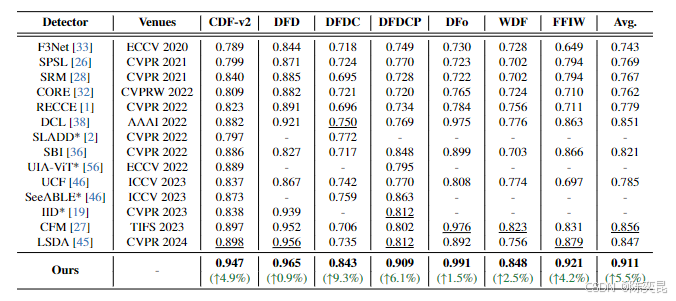
- 跨数据集泛化:在未见过的伪造技术(如e4s、SimSwap)上,AUC最高达94.7%,较SOTA方法提升9.3%(表5);
- 效率优势:相比全参数微调的3D CNN(如VdTR, 93M参数),StA仅需22M参数,推理速度提升40%(表6);
- 消融实验:VB和StA单独贡献显著增益,联合使用时AUC提升14.7%(表7),验证了时空特征协同的重要性。

五、应用场景:多领域落地潜力
1. 互联网内容监管
- 平台视频审核:实时检测社交平台(抖音、YouTube)上传内容,拦截伪造名人、政治人物的虚假视频;
- 电商直播防伪:识别虚拟主播的面部合成漏洞,保障商品展示真实性。
2. 司法与安全取证
- 视频证据鉴定:辅助警方分析监控录像中的伪造片段,识别帧间特征漂移作为篡改证据;
- 身份认证增强:在金融远程开户、政务人脸核验中,结合时空特征检测活体与伪造视频的差异。
3. 多媒体内容生产
- 电影与娱乐:自动检测AI生成视频中的不自然运动,提升虚拟人、特效场景的质量控制;
- 教育领域:防止伪造课堂录像用于学术欺诈,确保在线教育内容的真实性。
六、总结与未来方向
本文提出的**视频级混合增强(VB)和时空适配器(StA)**技术,首次将FFD伪影引入数据合成,并通过轻量级架构实现高效时空特征融合,在跨域检测中展现出卓越泛化能力。未来可探索:
- 多模态融合:结合音频、文本信息进一步提升检测鲁棒性;
- 轻量化部署:适配移动端设备,支持实时视频流检测;
- 对抗攻防:针对更高级的动态伪造技术(如时序一致化生成模型)优化算法。
论文代码预计在CVPR 2025开源,相关技术已在腾讯优图实验室等机构落地,为构建可信数字内容生态提供了关键技术支撑。
参考资料
Yan, Z., Zhao, Y., Chen, S., Guo, M., Fu, X., Yao, T., Ding, S., & Yuan, L. (2024). Generalizing Deepfake Video Detection with Plug-and-Play: Video-Level Blending and Spatiotemporal Adapter Tuning. arXiv preprint arXiv:2408.17065.



















 3676
3676

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











