







一文读懂MambaVision:融合Mamba与Transformer的视觉骨干网络新贵
在计算机视觉领域,骨干网络的性能对各类任务的效果起着决定性作用。今天要介绍的MambaVision,作为一种全新的混合Mamba-Transformer视觉骨干网络,在多个视觉任务中展现出了卓越的性能。
研究背景
传统的视觉骨干网络,如卷积神经网络(CNN)和基于Transformer的视觉Transformer(ViT),在处理视觉信息时各有优劣。CNN擅长捕捉局部特征,但在长距离依赖建模上存在局限;ViT虽然在长程依赖处理上表现出色,但计算复杂度较高,限制了其在一些资源受限场景的应用。Mamba作为一种新型架构,在自然语言处理领域展现出高效的长序列建模能力,将其引入视觉领域,有望为视觉骨干网络带来新的突破。
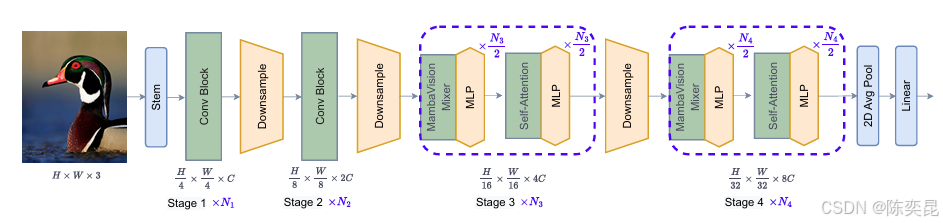
核心创新点
1. 重新设计Mamba架构用于视觉特征建模
研究者重新设计了Mamba的公式,使其更适合视觉特征的高效建模。Mamba原本是用于处理序列数据的架构,在视觉领域,图像可以看作是一种特殊的序列。通过调整Mamba的结构,使其能够更好地处理图像中的空间信息。例如,对Mamba中的一些参数和运算进行优化,以适应图像的二维结构,从而提高对视觉特征的捕捉能力。
2. 集成ViT与Mamba
通过全面的消融研究,验证了将ViT与Mamba集成的可行性。在Mamba架构的最后几层配备自注意力模块,显著提升了其捕捉长距离空间依赖的能力。自注意力机制能够让模型在处理图像时,关注到不同位置之间的关系,对于理解图像中的全局信息非常关键。这种集成方式结合了Mamba的高效性和ViT在长程依赖建模方面的优势,形成了强大的视觉骨干网络基础。
3. 设计分层架构的MambaVision模型家族
基于上述发现,研究者引入了一系列具有分层架构的MambaVision模型,以满足不同的设计标准。分层架构可以在不同的尺度上对图像进行处理,从低层次的局部特征到高层次的全局特征,都能有效地捕捉。不同的模型变体在参数数量、计算复杂度和性能上有所差异,用户可以根据具体任务和资源情况选择合适的模型。
模型架构详解
MambaVision采用了一种独特的架构,结合了自注意力模块和混合块(mixer block)。混合块通过创建对称路径来增强全局上下文的建模能力,且不依赖于结构化状态空间模型(SSM)。在整个网络中,MambaVision通过多个阶段(stage)逐步提取图像特征,每个阶段都由多个相同的模块组成,随着阶段的推进,特征图的分辨率逐渐降低,而通道数逐渐增加,从而实现对图像特征的深度挖掘。
实验结果与分析
1. ImageNet-1K数据集分类任务
在ImageNet-1K数据集的分类任务中,MambaVision的不同变体在Top-1准确率和吞吐量方面均达到了当前最优(SOTA)性能。例如,MambaVision-T模型在该数据集上的Top-1准确率达到了82.3%,同时吞吐量为6298 Img/Sec,在保证准确率的同时,实现了高效的推理速度。随着模型规模的增大,如MambaVision-L2模型,Top-1准确率提升至85.3% ,展示了模型的强大性能。
| 模型名称 | Acc@1(%) | Acc@5(%) | 吞吐量(Img/Sec) | 分辨率 | 参数数量(M) | 计算量(G) |
|---|---|---|---|---|---|---|
| MambaVision-T | 82.3 | 96.2 | 6298 | 224x224 | 31.8 | 4.4 |
| MambaVision-T2 | 82.7 | 96.3 | 5990 | 224x224 | 35.1 | 5.1 |
| MambaVision-S | 83.3 | 96.5 | 4700 | 224x224 | 50.1 | 7.5 |
| MambaVision-B | 84.2 | 96.9 | 3670 | 224x224 | 97.7 | 15.0 |
| MambaVision-L | 85.0 | 97.1 | 2190 | 224x224 | 227.9 | 34.9 |
| MambaVision-L2 | 85.3 | 97.2 | 1021 | 224x224 | 241.5 | 37.5 |
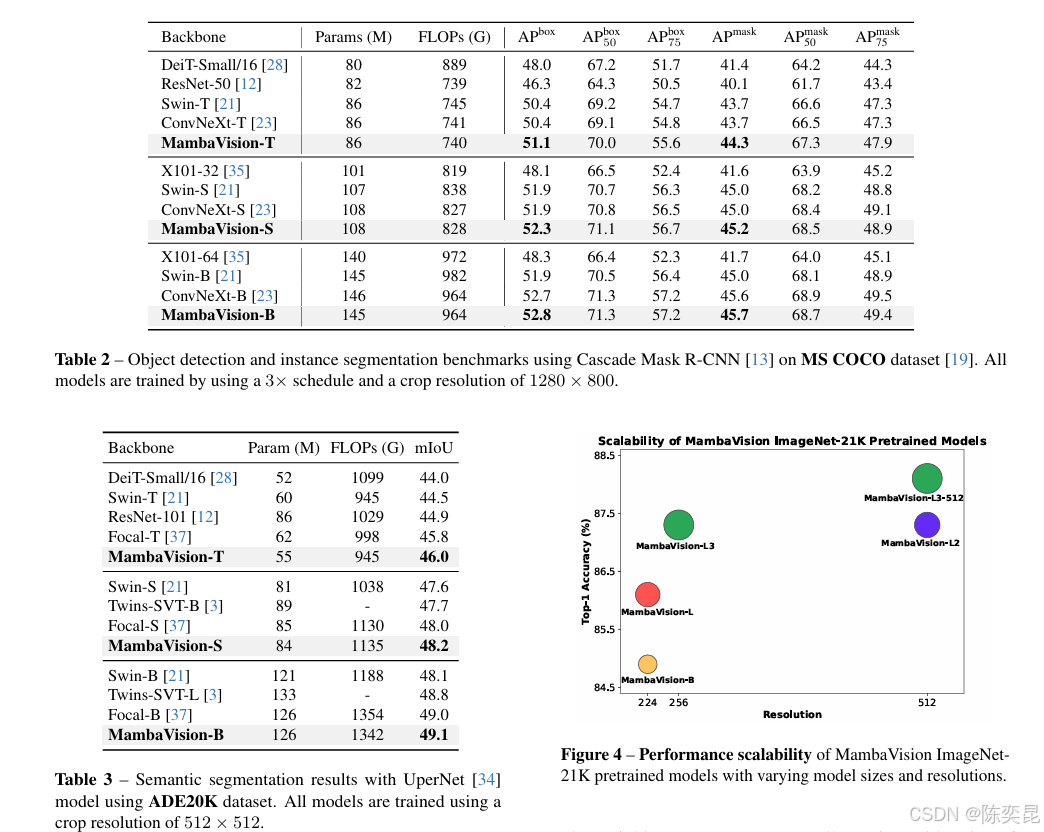
2. 下游任务表现
在MS COCO和ADE20K数据集的目标检测、实例分割和语义分割等下游任务中,MambaVision在与其他尺寸相当的骨干网络的对比中表现优异。它能够为这些任务提供高质量的特征表示,使得后续的检测和分割模型能够更准确地识别和分割目标物体。
应用场景

1. 图像分类
在图像分类任务中,MambaVision可以应用于各种领域,如安防监控中的目标分类(区分行人、车辆等)、医疗影像分析(识别病变类型)、工业产品质量检测(判断产品是否合格)等。凭借其高准确率和高效的推理速度,能够快速准确地对大量图像进行分类。
2. 目标检测
在自动驾驶场景中,需要实时检测道路上的车辆、行人、交通标志等目标。MambaVision可以作为骨干网络,为目标检测模型提供强大的特征提取能力,帮助模型更准确地定位和识别目标,提高自动驾驶系统的安全性和可靠性。在智能安防监控中,也能快速检测出异常目标,如入侵的人员或车辆。
3. 实例分割和语义分割
在医学图像分割中,MambaVision可以用于分割人体器官、肿瘤等,辅助医生进行疾病诊断和治疗方案的制定。在遥感图像分析中,可对土地利用类型(如农田、建筑、水域)进行语义分割,或者对特定目标(如建筑物、桥梁)进行实例分割,为城市规划、资源管理等提供数据支持。
开源代码与使用方法
MambaVision的代码已开源在GitHub上(https://github.com/NVlabs/MambaVision ),方便研究者和开发者使用。用户可以通过安装相关依赖,使用预训练模型进行图像分类、特征提取等操作。例如,通过Hugging Face库,只需几行代码就能加载预训练模型进行图像分类。同时,代码库还提供了模型评估和训练的脚本,便于用户根据自己的需求进行二次开发和优化。
总结
MambaVision作为一种创新的混合视觉骨干网络,通过融合Mamba和Transformer的优势,在多个视觉任务中取得了优异的成绩。其分层架构和高效的特征建模能力,为计算机视觉领域带来了新的解决方案。随着研究的不断深入和应用的拓展,相信MambaVision将在更多领域发挥重要作用,推动视觉技术的进一步发展。



















 1292
1292

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











