






神经记忆模型
rnn和lstm的记忆能力实在有限,最多也就记忆十几个时间步长。因此当句子长度增长时或者需要添加先验知识时,seq2seq就不能满足此时对话系统的需求了。比起人工增加RNN隐藏状态大小,我们更愿意任意增加加入模型的知识量,同时对模型本身做出最小限度改变。基本上,我们能用独立存储器——作为一种神经网络能够按需读写的知识库——来增强模型。你可以把神经网络视为CPU,而且将这种新的外部存储器视为RAM。
按照facebook ai研究所和google deepmind研究所的进展回顾一下:
Facebook AI:
2015年提出MEMORY NETWORKS,使用记忆网络增强记忆。(引用数:475)
2015年提出End-To-End Memory Networks,针对上一篇文章中存在的无法端到端训练的问题,提出了端到端的记忆网络。(引用数:467)
2016年提出Key-Value Memory Networks for Directly Reading Documents,在端到端的基础上增加记忆的规模。(引用数:68)
2017年提出TRACKING THE WORLD STATE WITH RECURRENT ENTITY NETWORKS,论文提出了一种新的动态记忆网络,其使用固定长度的记忆单元来存储世界上的实体,每个记忆单元对应一个实体,主要存储该实体相关的属性(譬如一个人拿了什么东西,在哪里,跟谁等等信息),且该记忆会随着输入内容实时更新。(引用数:27)
Google DeepMind:
2014年提出Neural Turing Machines,神经图灵机,同facebook团队的记忆网络一样,是开篇之作。(引用数:517)
2015年提出Neural Random Access Machines,神经网络随机存取机。(引用数:55)
2015年提出Learning to Transduce with Unbounded Memory,使用诸如栈或(双端)队列结构的连续版本。(引用数:99)
2016年提出Neural GPUs Learn Algorithms,神经网络GPU,使用了带有读写磁头的磁带。(引用数:86)
Neural Turing Machines(NTM)
MEMORY NETWORK
Memory Network出现之前,大多数机器学习的模型都缺乏可以读取和写入外部知识的组件,例如,给定一系列事实或故事,然后要求回答关于该主题的问题。原则上这可以通过如RNN等模型进行语言建模来实现,因为这些模型可以被训练在阅读了一串文字之后用来预测下一个输出。然而,它们的记忆(隐藏状态和权重编码)通常太小,并且不能精确地记住过去的事实(知识被压缩成密集的向量)。
一个Memory Network由一个记忆数组m(一个向量的数组或者一个字符串数组,index by i)和四个组件(输入I,泛化G,输出O,回答R)组成。
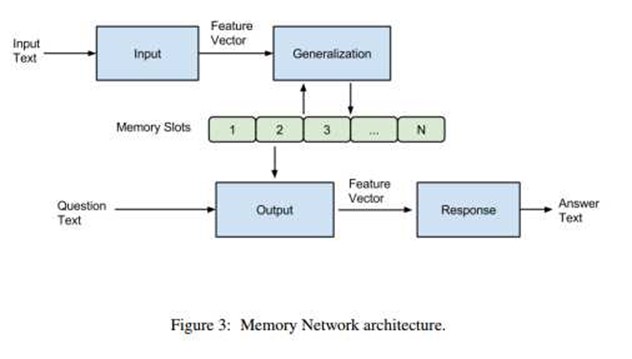
四个组件的作用:
I :(输入特征映射) - 将输入转换为记忆网络内部特征的表示。给定输入x,可以是字符、单词、句子等不同的粒度,通过I(x)得到记忆网络内部的特征。
G :(更新记忆) - 使用新的输入更新记忆数组m。
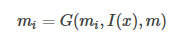
即通过输入I(x)和记忆数组m,来更新对应的记忆mi。比如论文中给出了一个G()函数的例子:
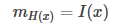
即将I(x)直接插入到记忆单元的插槽(slot)中,H(x)就是选择插槽的函数,这样只更新选择的插槽的记忆,而不更新其他的记忆。论文中也说,更复杂的G()函数,可以更新其他相关的旧的记忆,也可以在memory大小不够时进行遗忘。
O:(输出) - 在记忆数组m更新完以后,就可以将输入和记忆单元联系起来,根据输入选择与之相关的记忆单元。
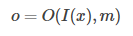
k为超参数,代表支持事例的个数。当k=1时:
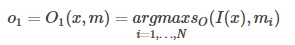
即根据输出I(x)从记忆单元中选择出与I(x)最相关的记忆事实。而当k=2时,
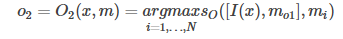
即将输入I(x)与第一个选择出来的记忆合并,然后再接着选择第二个与之相关的记忆。值得一提的是,因为此处加入了支持事实这一变量,因此在训练的时候数据集除了需要输入文本、问题和答案之外,还需要有支持事实这一个参数。
R:(输出回答) - 得到了输入编码向量I(x),记忆数组m和需要的支持事实,就可以根据问题来得到需要的答案了。文中给出了一个简单的R()函数,将输入和选择的记忆单元与此表中的每个单词进行评分Sr,然后选择得分最大的单词作为回答。即:
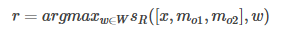
以下是统一的公式(可以看出作者把这玩意做成了一个架构,而不是一个具体的算法):

所有组件都是神经网络的话,叫做记忆神经网络(MemNNs,多了个s)。
Basic Model:
这是作者自己做的一个基本模型,或者算作是这个架构的一个简单例子。以下从一个记忆四个组件的角度,对这个方法进行说明:
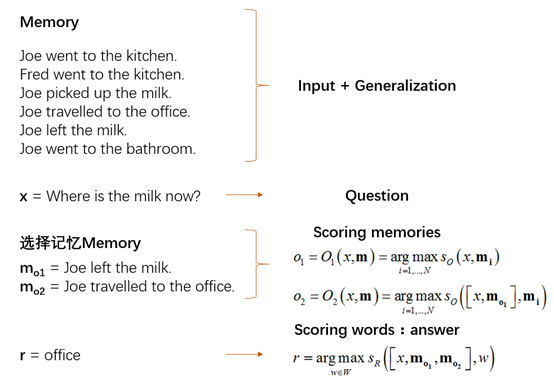
I:I输入的是一句话,简单地将I转换为一个频率的向量空间模型。
G:也是如上,简单地把读到的对话组里的每一句话的向量空间模型,插到记忆的list里,这里默认记忆插槽比对话组句子还多。。是的,m、I和G都很简单,也就是重任就压到了O和R上了。
O:O干的事,就是输入一个问题x,将最合适的k个支撑记忆(the supporting memories,在下文的数据集里会举出例子),也就是top-k。做法就是把记忆数组遍历,挑出最大的值。最后,O返回一个长度为k的数组。 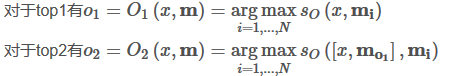
这里有几点说明:1、在这里,返回的oi简单就是记忆数组的序号索引。
2、在这里(向量空间模型向量表示),有
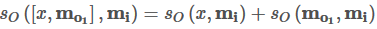
也就是对于多事实的情况,可以分开同时计算其与记忆的"关联度",然后加总。如果对于其他向量表示方式,则不一定有这样的线性关系。
3、作者给了一个有趣的例子反映了这个预测(test)过程,我觉得与其叫做回忆过程,还不如叫成推理过程好些

R:为了返回一个词汇w,设置公式
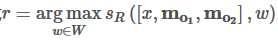
这里对所有的词汇进行循环遍历,挑出最适合答案(分数最高)的结果。在论文里,词汇被转化为同一空间里的向量空间模型的向量。如"memory"=[0,0,0,0,1,0,0,0],"network"=[1,0,0,0,0,0,0,0],则句子"memory network"=[1,0,0,0,1,0,0,0]。
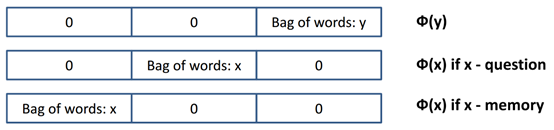
最后:作者继续简化处理
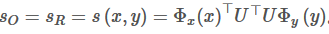
其中,U是一个权重矩阵,维度为n*D。D是输入向量的维度,n是嵌入的维度,n是一个超参数。作者使用D=3*lenW的维度。这里考虑了3倍向量空间模型长度,一份是给了phi_yФy,一份是给了x是输入的问题时的phi_xФx,一份是给了x是支撑记忆时的phi_xФx,三份直接连接在一起就可以了。(个人认为,作为对称,应该是4份。或许作者认为问题是一个空间,陈述句是另一个空间,而回答词汇只是属于陈述句空间,不用放在一起。) 和 使用不同的权重矩阵。
训练过程:使用margin ranking loss和sgd,在SVM和TransE里已经见识过了,就不赘述,复制公式如下:
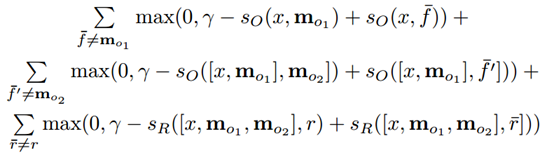
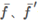 分别是第一和第二个支撑记忆,r¯′是正确答案。对的,读者也发现了,MemNN是一个监督学习的算法。(以后很多记忆模型,改成了弱监督了,以N2N为代表)注意,这里有两个监督的部分,一个是支撑记忆,一个是正确答案。
分别是第一和第二个支撑记忆,r¯′是正确答案。对的,读者也发现了,MemNN是一个监督学习的算法。(以后很多记忆模型,改成了弱监督了,以N2N为代表)注意,这里有两个监督的部分,一个是支撑记忆,一个是正确答案。
End-To-End Memory Networks
模型的结构如下图所示。图(a)是单层的模型,图(b)是多层模型(三层)。
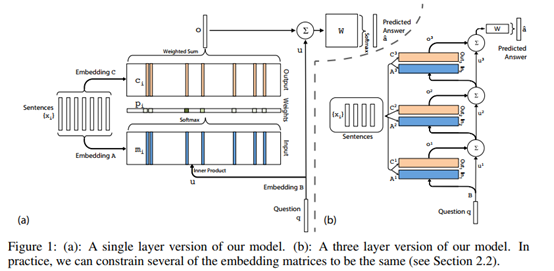
单层记忆网络
以图(a)为例,输入有两个部分,
使用输入集合

表示上下文知识,使用输入向量q表示问题,使用输出向量表示预测答案。记忆网络模型通过对上下文集合S和问题向量q的数学变换,得到对应于问题的答案。
首先,上下文集合S通过隐含层矩阵Embedding得到记忆向量的编码向量 。同样的,问题向量q通过隐含层矩阵Embedding得到问题向量的编码向量u,然后计算两者的内积:
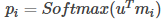
其中,
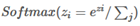
那么就为输入向量的概率。
然后,每个输入都有一个输出向量 ,和得到的方式是类似的,是通过隐含层矩阵Embedding 得到的。将 与相乘求和,得到答案向量的编码向量o。
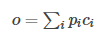
案向量的编码向量o以后,需要解码生成预测的答案,通过一个待训练矩阵,得到预测答案aˆ 。
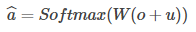
多层记忆网络
如图(b)所示,多层记忆网络和单层的基本结构是类似的,有一些小的细节需要改变,以将几个单层网络连接起来。
- 将与相加作为下一层的问题编码,即:
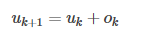
-
每一层都有嵌入矩阵来将x映射到记忆单元和编码单元。但是这样参数数量就会随模型层数的增加呈倍数增长,为了减少参数数量,使训练能够方便进行,论文中提出了两种减少参数的方法:
2.1相邻的嵌入矩阵相同,这样比着之前减少了一般参数,即
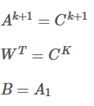
2.2层间共享参数,即
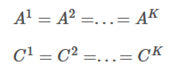















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









