







本文主要介绍Infineon Aurix2G TC3XX系列芯片内核指令集系统,及相关代码演示。
1. 指令集系统介绍
指令集系统是一种用于计算机或其他数字处理器的体系结构,它规定了处理器能够执行的指令集合,包括操作码、操作数和指令格式等。不同的处理器架构(如x86、ARM、MIPS等)都有自己的指令集系统,这些系统决定了处理器如何执行各种操作,从简单的加法和乘法到复杂的条件分支和内存访问。指令集系统的设计直接影响了处理器的性能、功耗和软件兼容性。
CPU中用来存放操作数的存储单元主要有三种:堆栈、累加器、通用寄存器组。据此,可以把指令集系统的结构分为以下三种:
- 堆栈型结构:在堆栈型结构中操作数都是隐式的,即利用栈顶和次栈顶的数据,运算后的结果压入栈顶,这种结构中,只能通过push/pull访问存储器;
- 累加器型结构:累加型结构中,一个操作数是隐式的,放在累加器中,另一个操作数是显式给出的,是一个存储单元,运算后的结构存入累加器;
- 通用寄存器型结构:在通用寄存器型结构中,所有的操作数都是显式给出的,它们或者都来自通用寄存器,或者有一个操作数来自存储器,运算结果写入存储器。
虽然早期的大多数计算机都是采用堆栈型结构或累加器型结构的指令系统,但是自1980年以后,大多数计算机都采用了通用寄存器型结构,该结构在灵活性和提高性能方面有明显的优势。
而在通用寄存器结构中,操作数可以来自存储器,也可以来自寄存器,根据操作数的来源不同,其又可以继续分类为寄存器-存储器结构(简称RM结构)和寄存器-寄存器结构(简称RR结构)。RM结构的操作数可以来自存储器,也可以来通用寄存器组;RR结构的操作数全部来自通用寄存器组 。由于在RR结构中,只有load指令和store指令能够访问寄存器,所以也称为load-store结构。RR结构因其简洁性和源操作数的对称性而备受青睐,并且对于实现指令流水也更方便。
和ARM指令集一样,TriCore指令集属于通用寄存器型结构中的寄存器-寄存器结构,即除了load和store以外,其余指令的操作数都来自通用寄存器组。
本文介绍的TriCore内核是Aurix TC3XX系列中使用的TriCore™ TC1.6.2版本的内核架构。 由于篇幅原因,无法讲解所有指令,但是通过本文的介绍,读者能够较好地掌握TriCore指令系统的结构和使用,然后就可以自行利用内核手册进行查阅和学习。
2. TriCore指令集结构
TriCore™是一种统一的、32位的微控制器-DSP,针对实时嵌入式系统进行了优化的单核架构。这里的单核架构不是指芯片只有一个核,而是指其不具有多核的异构耦合设计,每个核都是独立、同构存在的。
TriCore指令集支持32位指令和16位指令,支持嵌入式常用的微控制器系列处理指令,也支持一些DSP数据处理指令。
2.1 指令语法
和ARM等指令集系统一样,TriCore指令集的语法也是由指令和操作数组成,操作数可以是立即数、寄存器或内存。一条指令包括基础操作符、操作修饰符、操作数修饰符和操作数组成。如下面这条指令,是将一个立即数写入地址寄存器的高位:
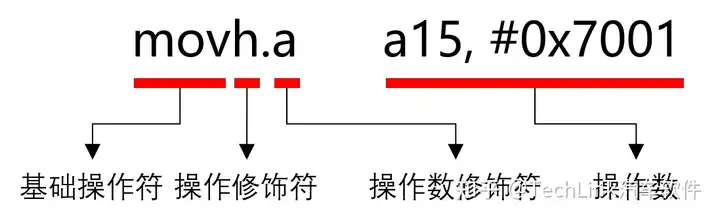
- 基础操作符:定义了该指令的基础操作,比如mov就是赋值,add就是累加;
- 操作修饰符:定义该操作更准确的细节,比如movh中的h定义操作a15的高16位;
- 操作数修饰符:定义了操作数的数据类型,比如movh.a中的a定义了目标寄存器为地址寄存器;
- 操作数:需要操作的寄存器、立即数或内存。
基础操作符即该指令的操作定义,操作类型较多,此处就不一一列出了。
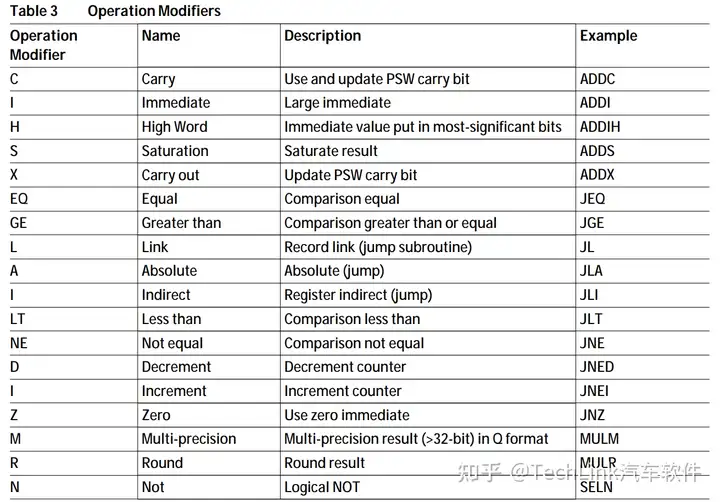
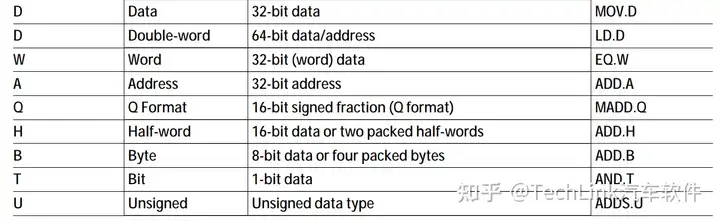
TriCore指令集的操作修饰符见下表:
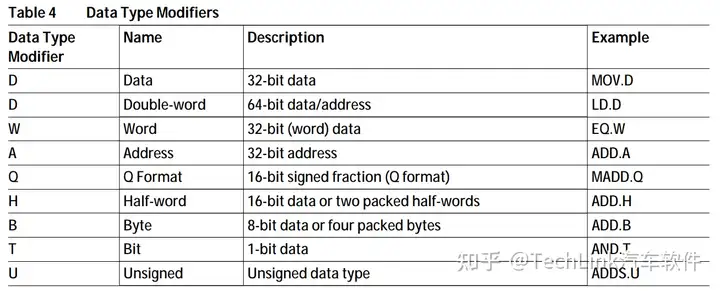
TriCore的操作数修饰符见下表:
有些16位指令还会使用隐式寄存器,即该条指令不指定寄存器,而是固定使用约定好的寄存器,隐式寄存器包含下面几种:
- D[15]:通用数据寄存器D[15]可以作为16位指令的隐式数据寄存器使用;
- A[15]:通用地址寄存器A[15]可以作为16位指令的隐式地址寄存器使用;
- A[10]:A[10]为栈指针寄存器,所以对于栈相关操作指令默认操作数为A[10];
- A[11]:A[11]为返回地址寄存器,即链接寄存器,所以跳转指令默认使用A[11]作为指令默认的操作数。
2.2 程序状态字标志位(用户状态位)
之前的内核寄存器介绍中提到过,程序状态字寄存器PSW中有5个用户状态位,用于指令的状态存储。
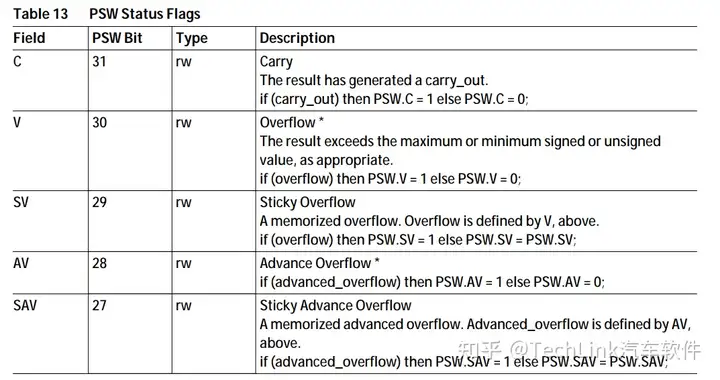
这5个状态位会会影响指令的操作逻辑,同时它们也会因为指令的操作结果而发生变化。比如第一个Carry位,它表示计算进位,比如在使用加法指令ADDC(带进位的加)中结果溢出了,那C位就会置位;并且如果在执行前C位已经置位了,那ADDC的结果就会加1。
在手册中每个指令后都会描述PSW的影响情况,可在指令详细信息中查看。

2.3 指令权限
TriCore内核分为三个权限等级,因此有些指令对权限是有限制的。下表列出的指令表示只有该权限等级下能够使用。

3. TriCore指令介绍
本章节将分类介绍TriCore指令集中的指令,同时包括部分操作修饰符和操作数修饰符的介绍。
3.1 Load/Store指令
在RR结构的内核中,Load(LD.X)和Store(ST.X)指令是唯一两条能够访问内存的指令,它们是内存和寄存器间的桥梁,其余的所有指令都是基于寄存器进行操作的。
Load/Store指令支持以下这些寻址模式:

其中最主要的还是绝对地址寻址和基址-偏移寻址。
TriCore指令集的Load/Store除了支持字节(byte)、半字(Half Word)、字(Word)、双字(Double Word)等基础数据类型,还支持浮点型和地址型(地址寄存器的读写)。TriCore中一个字Word,代表32字节。
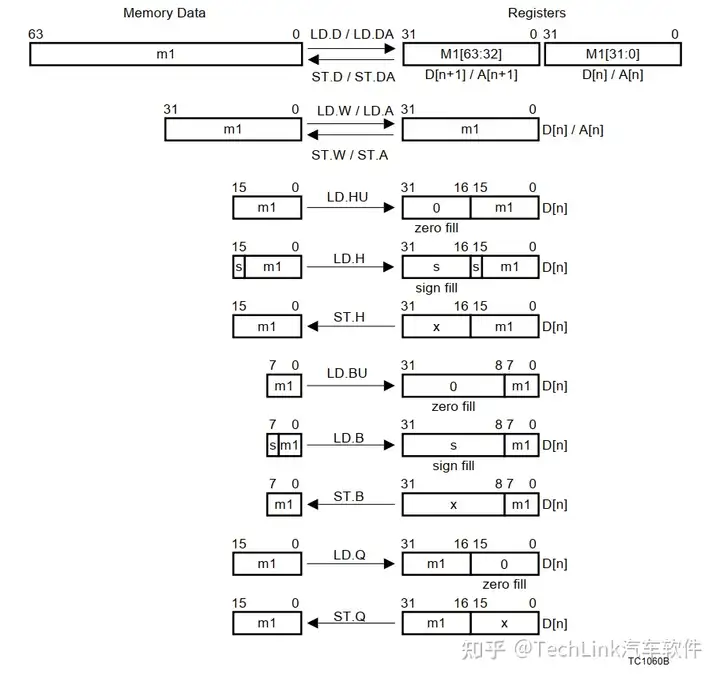
下面对Load/Store指令结合操作修饰符和操作数修饰符进行指令说明,这里需要注意的是,TriCore的通用寄存器是分为通用地址寄存器和通用数据寄存器两类的,因此操作数修饰符会强调操作数类型。
LD.A A0, [A15] //将A15指向的内存中的4字节数据,取到A0中,A表示操作数为地址寄存器
LD.BU D5, [A0] //将A0指向的内存中的一字节无符号数据,取到D5中,B表示Byte,1字节,U表示无符号
LD.D E0, [A0] //将A0指向的内存中的8字节数据,取到E0中(D0+D1),D表示Double Word
LD.H D1, [A0] //将A0指向的内存中的2字节数据,取到D1的低16位中,H表示Half Word
LD.W D2, [A2]0x44 //将A2+0x44指向的内存中的4字节数据,取到D2中,W表示Word,0x44表示地址偏移
ST.A [A1], A0 //将A0的数据,存储到A1指向的4字节内存中,A表示操作数为地址寄存器
ST.B [A1], D0 //将D0的1字节数据,存储到A1指向的1字节内存中,B表示长度为1字节
ST.D [A1], E0 //将E0(D0+D1)中的8字节数据,存储到A1指向的8字节内存中,D表示Double Word
ST.H [A0], D0 //将D0中的2字节数据,存储到A0指向的2字节内存中,H表示Half Word
ST.W [A1], D0 //将D0中的4字节数据,存储到A1指向的4字节内存中,W表示Word3.2 算术运算指令
算术运算指令包括MOVE、加减乘除、绝对值、逻辑运算、移位等,还包括计算非零bit位等。
TriCore算术运算符有一种Saturation运算,操作修饰符为S,即饱和运算,意思是说当运算结果超出内存大小,结果是当前内存的最大值。比如uint8的最大值为256,用ADDS去计算200+200,得到的结果是256。同样的如果减法运算值小于负的最大值,结果也是负的最大值。
3.2.1 MOV指令
MOV指令是将一个立即数或者寄存器的值,赋值给另一个寄存器的指令。
MOV D0, D1 //将D1中的值赋值给D0
MOV.A A0, D0 //将D0中的值赋值给地址寄存器A0,A表示目的操作数是地址寄存器
MOV.D D3, A4 //将地址寄存器A4的值赋值给数据寄存器D3,D表示目的操作数是数据寄存器
MOV.AA A3, A4 //将地址寄存器A4的值赋值给地址寄存器A3,AA表示源操作数和目的操作数都是地址寄存器
MOVH D3, 180 //将立即数180赋值给D3的高16位,并将D3的低16位清零,H表示高位3.2.2 ADD/SUB指令
加法和减法指令类似,此处只列出加法的说明。
加法指令是ADD,普通加法运算中,溢出会自动去除高位,比如uint8的255+100,结果等于99。
而带修饰符的加法运算,是会修改PSW的用户状态位的,比如ADDC指令如果溢出会修改Carry位。
ADD D0, D1, D2 //计算D1+D2的值,结果存到D0中,溢出位舍弃,如255+1=0(uint8)
ADD.A A0, A1, A2 //计算地址寄存器A1+A2的值,结果存到A0中,A表示操作数为地址寄存器
ADDX D3, D1, D2 //计算D1+D2的值,结果存到D3中,如果溢出,PSW.C=1,否则PSW.C=0
ADDC D3, D1, D2 //计算D1+D2+PSW.C的值,结果存到D3中,如果溢出,PSW.C=1,否则PSW.C=0
ADDI D3, D1, 858 //计算D1+858的值,结果存到D3中
ADDIH D3, D1, 0x8 //立即数移位加法,计算D1+0x8<<16的值,结果存到D3中,IH表示立即数左移16位
ADDS D3, D1, D2 //计算D1+D2的值,如果溢出则做饱和运算处理,结果存放到D3中
ADDS.U D3, D1, D2 //计算无符号D1+D2的值,如果溢出则做饱和运算处理,结果存放到D3中3.2.3 MUL乘法指令
乘法指令为MUL,部分乘法指令同样也会修改PSW的用户状态位。
MUL D3, D1, D2 //计算D1*D2的值,溢出位舍弃,结果存放到D3中
MUL E0, D1, D2 //计算D1*D2的值,结果存放到E0(D1+D2)中
MULS D2, D1, D2 //计算D1*D2的值,溢出则做饱和运算处理,结果存放到D3中
MUL.U E0, D1, D2 //计算无符号D1*D2的值,结果存放到E0(D1+D2)中3.2.4 DIV除法指令
TriCore指令集支持32位的有/无符号除法,对于双精度64位的除法,则需要依赖于编译器的算法去执行。另外由于除法指令计算时间相对较长,会消耗数个指令周期,因此会降低中断的实时性响应,这种影响与商的有效位成正比。除法运算在计算时结果可以占据一个寄存器对,商保存在第一个寄存器中,余数保存在第二个寄存器中。
有符号整数除法的计算相对于加法等有较多的判断逻辑:
DIV E[c], D[a], D[b] //计算D[a]/D[b],商存放到E[c][31:0],余数存放到E[c][63:32]中
dividend = D[a];
divisor = D[b];
if (divisor == 0) then {
if (dividend >= 0) then {
quotient = 0x7fffffff;
remainder = 0x00000000;
} else {
quotient = 0x80000000;
remainder = 0x00000000;
}
} else if ((divisor == 0xffffffff) AND (dividend == 0x80000000)) then {
quotient = 0x7fffffff;
remainder = 0x00000000;
} else {
remainder = dividend % divisor
quotient = (dividend - remainder)/divisor
}
E[c][31:0] = quotient;
E[c][63:32] = remainder;无符号整数的计算也类似上面的形式:
DIV.U E[c], D[a], D[b] //计算无符号D[a]/D[b],商存放到E[c][31:0],余数存放到E[c][63:32]中,U表示无符号
dividend = D[a];
divisor = D[b];
if (divisor == 0) then {
quotient = 0xffffffff;
remainder = 0x00000000;
} else {
remainder = dividend % divisor
quotient = (dividend - remainder)/divisor
}
E[c][31:0] = quotient;
E[c][63:32] = remainder; 浮点数的除法运算逻辑整体不复杂,根据IEEE754规范计算32位浮点数除法,指令的后台执行流程相对要多一些,这里不详细列出,感兴趣的读者可以查看内核手册。
DIV.F D3, D1, D2 //计算浮点数D1/D2的值,结果存放到D3中3.2.5 ABS/ABSDIF绝对值指令
TriCore指令集支持直接进行有符号数的绝对值运算,或者计算两个数的差值的绝对值。
ABS D1, D2 //计算D2的绝对值,结果存放到D1中
ABSDIF D3, D1, D2 //计算D1-D2的值的绝对值,结果存放到D3中3.2.6 MIN/MAX比较指令
TriCore指令集支持直接对两个数进行比较,取其较大值或较小值,输入源可以是整形或者无符号整形。
MIN D3, D1, D2 //比较D1和D2的大小,将较小的存放到D3中
MIN.U D3, D1, 8 //比较D1和8的大小,将较小的存放到D3中,U表示无符号数
MAX D3, D1, D2 //比较D1和D2的大小,将较大的存放到D3中
MAX.U D3, D1, 8 //比较D1和8的大小,将较大的存放到D3中,U表示无符号数3.2.7 CADD/CSUB/SEL条件指令
TriCore对于整数运算提供了条件执行指令,即先对某个数进行判断,来决定是否执行加减或者选择赋值来源。
CADD D4, D1, D2, D3 //如果D1非零,则D4=D2+D3,否则D4=D2
CADDN D4, D1, D2, 8 //如果D1为零,则D4=D2+8,否则D4=D2
CSUB D4, D1, D2, D3 //如果D1非零,则D4=D2-D3,否则D4=D2
SEL D4, D1, D2, D3 //如果D1非零,则D4=D2,否则D4=D3
SELN D4, D1, D2, 8 //如果D1为零,则D4=D2,否则D4=83.2.8 AND/OR/XOR逻辑指令
TriCore支持AND/OR/XOR等按位的逻辑指令,同时也支持结果取反的NAND/NOR/XNOR指令,以及源操作数取反的ANDN、ORN等。后两者容易混淆,要注意辨别,比如NAND和ANDN。
AND D3, D1, D2 //计算D1与D2的按位与,结果存放到D3中,即D3 = D1&D2
OR D3, D1, 0xCC //计算D1与0xCC的按位或,结果存放到D3中,即D3 = D1|0xCC
XOR D3, D1, D2 //计算D1与D2的按位异或,结果存放到D3中,即D3 = D1^D2
NAND D3, D1, D2 //计算D1与D2的按位与,并按位取反,结果存放到D3中,即D3 = ~(D1&D2)
ANDN D3, D1, D2 //计算D2的按位取反,然后与D1按位取与,结果存放到D3中,即D3 = D1&~D2
NOT D1 //计算D1的按位取反,结果存放到D1中,即D1 = ~D13.2.9 CLO/CLZ/CLS计位指令
TriCore提供了用于位计数的功能,能够计算高位连续的0位、1位或符号位。
CLO(Count Leading Ones)用于计算从最高位开始一共多少个连续的1,比如0xF000 0000计算的结果为4,0xF800 0000计算的结果为5.
CLZ(Count Leading Zeros),用于计算从最高位开始一共多少个连续的0,比如0x0FFF 0000计算的结果为4,0x07FF 0000计算的结果为5.
CLS(Count Leading Signs),用于计算从次高位开始一共多少个与最高位相同值的连续位数,比如第31位为1,则从30开始计算连续的1的个数。
CLO D2, D1 //计算D1的CLO的值,结果存放到D2中
CLZ D2, D1 //计算D1的CLZ的值,结果存放到D2中
CLS D2, D1 //计算D1的CLS的值,结果存放到D2中3.2.10 SH/SHA/SHAS移位指令
TriCore的移位指令支持有符号数移位,如果是整数就左移,如果是负数就右移。
SH D3, D1, D2 //按照D2的值对D1进行移位,填充值始终为0,结果存放到D3中
SHA D3, D1, D2 //按照D2的值对D1进行移位,左移填充位为0,右移填充位同符号位,结果存放到D3中
SHAS D3, D1, D2 //与SHA计算相同,区别在于结果取饱和操作,S代表SATURATION3.2.11 EXTR/INSERT位提取/插入指令
TriCore支持对数据进行位提取和位插入功能。
位提取是指提取源操作数的某个bit段,赋值给目的操作数,操作数可以是整形或无符号整形。
EXTR D3, D1, D2, #4 //D2[4:0]为pos,4为width,然后按照下图从D1中截取,赋值到D3中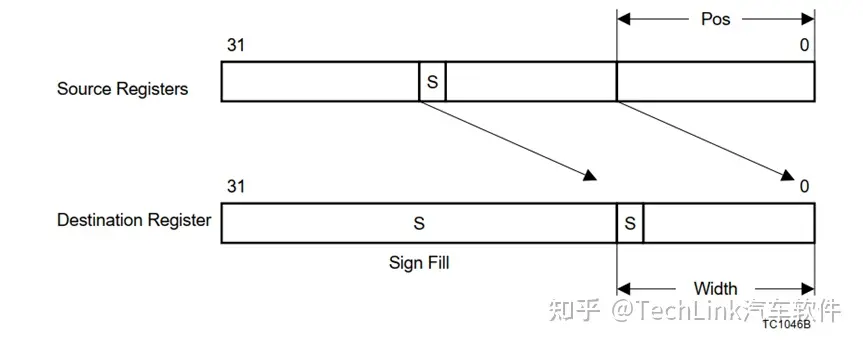
EXTR.U D3, D1, D2, #4 //D2[4:0]为pos,4为width,然后按照下图从D1中截取,赋值到D3中,U表示无符号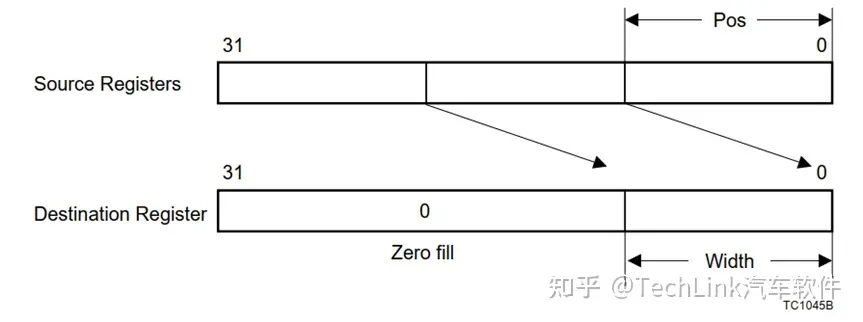
DEXTR D3, D1, D2, 5 //将{D1,D2}左移5位,然后截取[63:32]位,赋值给D3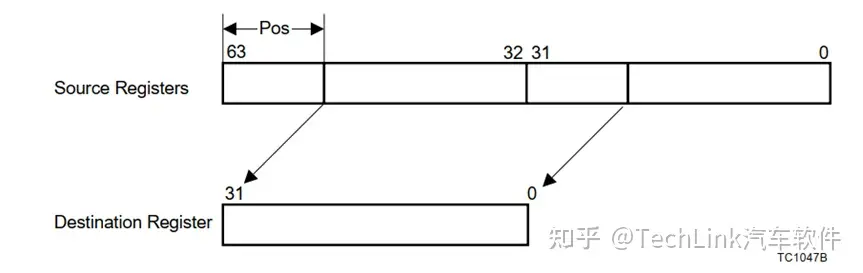
INSERT D3, D1, D2, D4, #8 //D4[4:0]为Pos,8为width,将D2按照下图位置左移,然后覆盖到D1该段,结果赋值给D3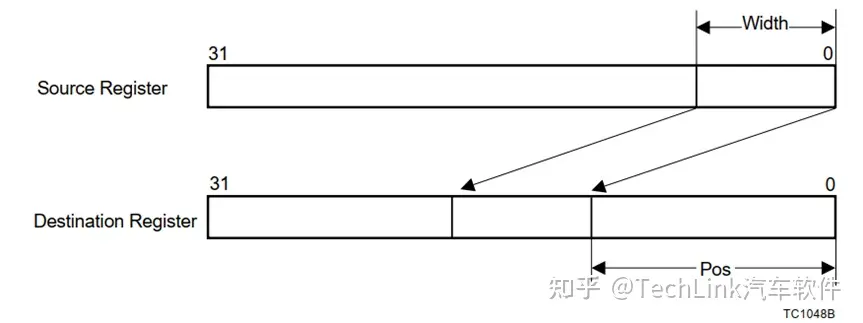
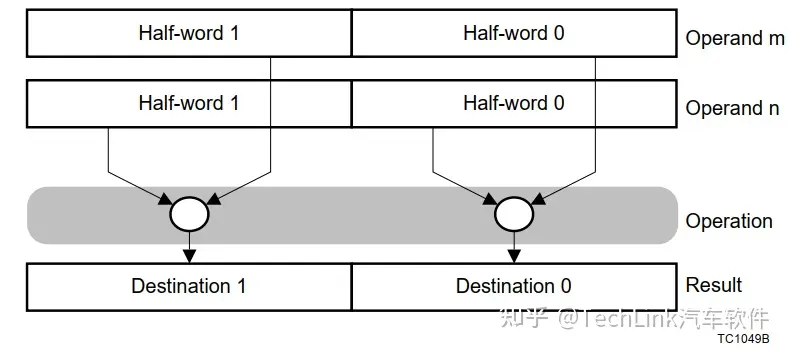
3.3 Packed打包计算
TriCore的算术运算符还有一种打包运算方法,对于一个32位数据,可以按照字节或者半字分别计算,结果分别存放到指定位置。
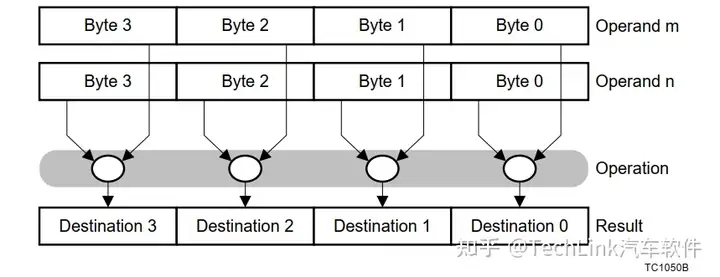
ADD.B D3, D1, D2 //将D1与D2按照字节依次相加,结果分字节存放到D3中,任意一个字节计算溢出,V和SV都会置位
ADD.H D3, D1, D2 //将D1与D2按照半字依次相加,结果分半字存放到D3中,任意一个半字计算溢出,V和SV都会置位3.4 EQ/NE/LE/GE比较指令
TriCore中比较指令的使用也是比较频繁的,主要用于条件指令的操作修饰符,比如分支跳转等。
- EQ (Equal)
- NE (Not Equal)
- LT (Less Than)
- GE (Greater than or Equal to)
另外对于大于和小于等于,TriCore是没有指令的,需要依赖上述指令隐式实现。
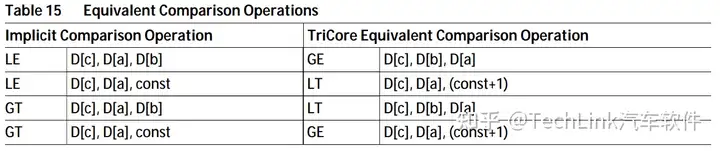
LT D3, D1, D2 //D3 = (D1<D2)
GE D3, D1, D2 //D3 = (D1>=D2)3.5 地址指令
TriCore中对于地址的运算和操作和数据还是具有一定差异的,同时硬件上采用了通用地址寄存器等设计来实现加速。一般使用赋值加载以及LEA指令进行地址计算。
LEA(Load Effective Address)指令用于计算绝对地址,并保存到指定的地址寄存器中。
MOVH.A A5, #0x7001 //将0x7001赋值给A5高16位,低16位置0
LEA A5, [A5]0x4864 //将A5中的值加上0x4864,然后赋值给A5,组成0x7001 4864地址值3.6 跳转指令
TriCore中的分支指令大致分为以下三种:
- Jump:跳转指令,该指令不做任何其他操作,仅修改PC指针到指定地址运行,一般用户常规指令运算或分支跳转;
- Jump And Link:链接跳转指令,该指令除了跳转以外,还会将其下一条指令的地址存到返回地址寄存器中;
- Call And Return:调用和返回指令,该指令必须成对使用,调用指令会保存高上下文,返回指令则会恢复高上下文。一般用于函数调用。
J foobar //跳转到foobar
JI A5 //跳转到A5指向地址
JL foobar //将下一条指令地址写入到返回地址寄存器中,并跳转到foobar
CALL foobar //保存高上下文,将下一条指令地址写入到返回地址寄存器中,跳转到foobar
JEQ D1, D2, foobar //如果D1==D2,跳转到foobar
JGE D1, D2, foobar //如果D1>=D2,跳转到foobar3.7 上下文相关指令
TriCore的上下文除了中断、Trap以及CALL、RET指令能够操作以外,还提供了专有的上下文操作指令。主要分为以下两类:
- SVLCX/RSLCX:低上下文保存和恢复指令,使用的内存是CSA区域,并同时会更新PCX以及FCX寄存器;
- STUCX/STLCX/LDUCX/LDLCX:上下文加载和存储指令,使用的区域需要指令指定,且不会更新PCX和FCX;
这里要注意区分,第二种使用方法虽然也能够保存和加载通用寄存器,但是它是不使用CSA区域的,同时也不会更改PCX和FCX寄存器。
关于TriCore上下文相关介绍,读者可参考之前发布的《TriCore上下文切换及CSA机制》。
3.8 系统相关指令
TriCore提供了内核系统指令,主要包括System Call、指令和程序屏障、开关中断等功能。
3.8.1 SYSCAL系统调用指令
TriCore的系统调用是通过Trap6来实现的,一般用来给OS做内核模式切换使用的。
SYSCALL 4 //执行System Call,4为系统调用的入参3.8.2 DYSNC/ISYNC数据/指令屏障
这两条指令的作用是作为数据/指令屏障而使用的。
DYSNC指令
在计算机科学中,数据屏障(Memory Barrier)是一种用于控制处理器和内存之间数据同步的机制。它确保在多核或多线程系统中的内存访问顺序得到正确的维护,避免了由于并发访问导致的数据不一致性和竞态条件。DYSNC作为一个屏障,将其前后的指令进行分隔,保证后面的指令一定在前面的所有内存访问完成后执行,包括Cache,防止因编译器优化或指令流水、多线程等导致的数据访问次序错误。
ISYNC指令
指令屏障(Instruction Barrier)是另一种用于控制处理器执行指令顺序的机制。它确保在处理器执行指令时,按照程序员的预期顺序执行,避免指令重排或者乱序执行导致的问题。另外如果指令修改了系统的状态,比如内存保护设置,则该指令能够保证其后执行的所有程序都是按照新的内存保护设置执行的。
DYSNC //数据屏障
ISYNC //指令屏障3.8.3 MFCR/MTCR核特殊功能寄存器指令
TriCore的核特殊功能寄存器CSFR是每个核特有的,而且对于多核其地址是不进行区分的,因此必须通过特殊的指令进行操作,哪个核执行该指令就作用于哪个核。
MFCR(Move From Core Special Function Register)读取指令
MFCR指令用于从CSFR中读取内容,比如我们最常用的读取当前核的ID。
MTCR(Move To Core Special Function Register)操作指令
MTCR指令用于修改CSFR中的内容,后面必须跟一条ISYNC用于指令屏障,保证操作完成。
MFCR D15, #0xFE1C //读取CoreID,结果保存到D15中
MTCR #0xFE04, D15 //修改PSW寄存器,将其值修改为D153.8.4 ENABLE/DISABLE开关中断
TriCore中每个核的中断使能是相互独立的,只需要使用ENABLE/DISABLE指令即可。
ENABLE //开中断
DISABLE //关中断3.8.5 TRAP指令
TriCore提供了用户软件触发Trap的方法,可以使用TRAPV或TRAPSV,当OverFlow或StickyOverflow位置位时触发Trap。
TRAPV //Trap on overflow
TRAPSV //Trap on sticky overflow3.9 16Bit指令
TriCore的大部分指令在某些情况下是支持16位格式的,甚至有些指令只有16位格式,具体可以参考内核手册,上面有每条指令的格式说明。
4. 使用示例
下面我们通过一段示例代码,通过对汇编进行说明,来帮助读者了解TriCore的指令集。下面的代码通过辗转相除法求两个数的最大公约数,数据源和结果都用了全局变量,以使用Load/Store指令。
4.1 示例代码
//变量声明
volatile int MyResult;
volatile int num1=15, num2=20; //volatile防止编译器优化
// 函数声明
int TestInstruction(void);
int gcd(int a, int b);
void echoInit(void){
TestInstruction();
}
int TestInstruction(void) {
// 计算并输出最大公约数
MyResult = gcd(num1, num2);
printf("GCD of %d and %d is %d\n", num1, num2, MyResult);
return 0;
}
// 计算最大公约数的函数
int gcd(int a, int b) {
int temp;
// 辗转相除法
while (b != 0) {
temp = b;
b = a % b;
a = temp;
}
return a;
}4.2 TestInstruction调用
我们首先看TestInstruction的调用这里,使用的是Jump指令,而不是JL或者Call。

这样做的好处是,当该条代码是调用方的最后一条指令,在其执行完毕之后已经没有必要返回调用方了,而是直接返回调用方的上一层调用方,这样的优化能够节省系统时间,提高性能。
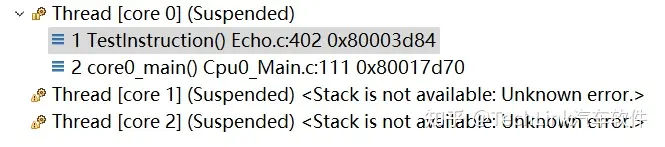
但是缺点是调用栈中就会少一层,图中echoInit就没有显示,不便于调试。所以我们在调试过程中经常会遇到调用栈的信息缺失,或者使用Return调试操作的时候会直接返回两层的情况,都是这个原因。
4.3 TestInstruction函数
TestInstruction函数一共只有三行,我们一一展开描述。

第一行是以num1和num2为入参,计算最大公约数:
- 首先是两条LD.W指令,因为是全局变量,所以要从内存中取出来;
- 然后是CALL指令,调用gcd函数,TriCore的入参是依次使用D4~D7数据寄存器,或A4~A7地址寄存器;
- 然后返回值在D2寄存器中,使用ST.W将其存入MyResult全局变量中;
第二行是调用printf函数将其显示出来:
- 首先是三条LD.W指令将全局变量读出来(这里因为我使用了volatile,所以没有编译器优化,每次都重新读写);
- 然后是三条ST.W指令将加载的三个变量压入栈中,作为printf函数的第2、3、4个入参;
- 然后是MOVH.A和LEA指令将地址0x8001 421C写入到A4寄存器中作为第一个入参,这里printf的第一个入参是字符串,传入的是字符串的首地址,我们打开内存使用ASCII格式可以看到这段字符;

- 然后进行printf函数调用。
最后一行是return 0:
- 使用MOV指令,将返回值写入到D2寄存器中;
- 使用RET指令返回,前面提到,TestInstruction是通过Jump调用的,所以这里会直接返回到调用echoInit的那层;
4.4 gcd函数
gcd函数这里是while循环,通过条件跳转,来进行循环计算。

- 首先是一条JG指令(目前观察其功能同J,但无论是Infineon手册还是Tasking手册都没有找到JG的相关描述),作为入口跳转到0x80004078;
- 在0x80004078处通过条件指令JNE,当D5(形参b)不等于0时跳转0x80004070进入循环;
- 然后在0x800040700开始,执行MOV、DIV、MOV进行算法的数学计算,随后进入下一轮的循环判断;
- 当循环结束后执行到0x8000407C,这里将D4(形参a)的值写入到D2中,并调用RET函数返回;
至此全部的函数调用就介绍完了,不同的编译器或者编译优化等级、编译选项等可能有不同的汇编结果,但是整体的内容是差不多的,希望读者能够通过这个示例,了解TriCore指令集的框架结构。
5.小结
本文介绍了TriCore内核的指令集系统,描述了其指令集的类型和特点;并介绍了其指令的语法结构,对常用的指令进行了详细说明。最后通过一段C语言示例,展示了TriCore指令集的调用和计算框架。读者如果感兴趣想进一步了解,可以结合日常代码参考内核手册进行查询学习,如果有问题也可以在评论区留言,大家互相交流学习。
参考资料
- Infineon-AURIX_TC3xx_Architecture_vol1-UserManual-v01_00-EN.pdf
- Infineon-AURIX_TC3xx_Architecture_vol2-UserManual-v01_00-EN.pdf

















 7205
7205

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









