







 超级会员免费看
超级会员免费看
Spark MLlib 特征工程系列—特征提取 TF-IDF
TF-IDF是文本挖掘中广泛使用的一种特征向量化方法,用于反映术语对语料库中文档的重要性。
Term Frequency (TF)
TF,即词频,是衡量一个词在文档中出现频率的指标。假设某词在文档中出现了( n )次,而文档总共包含( N )个词,则该词的TF定义为:
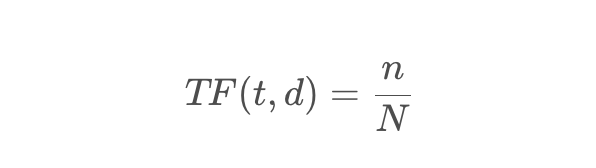
Inverse Document Frequency (IDF)
IDF,即逆文档频率,是对词普遍性的度量,反映了词的稀有程度。IDF越高,说明词越独特,对于区分文档具有更大的价值。IDF的计算公式为:
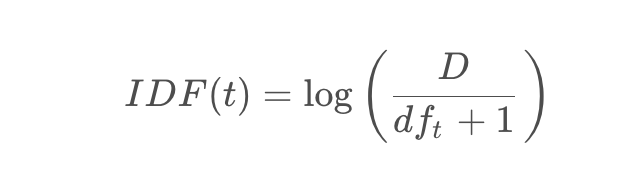
如果我们仅使用词频来衡量重要性,很容易过分强调那些出现频率很高但几乎不包含文档信息的术语,例如“a”、“the”和“of”。如果某个术语在整个语料库中出现的频率很高,则意味着它不包含有关特定文档的特殊信息。逆
由于使用了对数,如果某个术语出现在所有文档中,则其 IDF 值变为 0。请注意,应用了平滑项以避免语料库之外的术语除以零。 通过取对数,可以避免数值过大的问题,同时保证了IDF的单调递减特性。

 订阅专栏 解锁全文
订阅专栏 解锁全文

















 1628
1628

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











