







这是以前的我写的多模态系列,进行的重整理,去除了调侃的话和描述不清楚的地方,相当于重写了一遍,也算是万字长文了。个人感觉就算不是全网最细也能排进前10了,我尽量往简单了写,想入门多模态的各位可以无脑刷。
第5章 多模态架构MLLM讲解
MLLM(Multimodal Large Language Models)即多模态的大语言模型,顾名思义,这个还是以大语言模型为基础的
如何说明一个模型是多模呢?主要是2点:
1-Encoder,decoder的多模
2-多模融合
5.1 FLIP
从一个简单的多模态CLIP讲起,CLIP也是OPENAI的模型,现在也被广泛的应用于各种多模态的业务场景里,本身是开源的,又是挺重要的分类器,目前开源的多模态模型或多或少都用了它的代码和概念 首先看它是怎么实现的,如图5-1
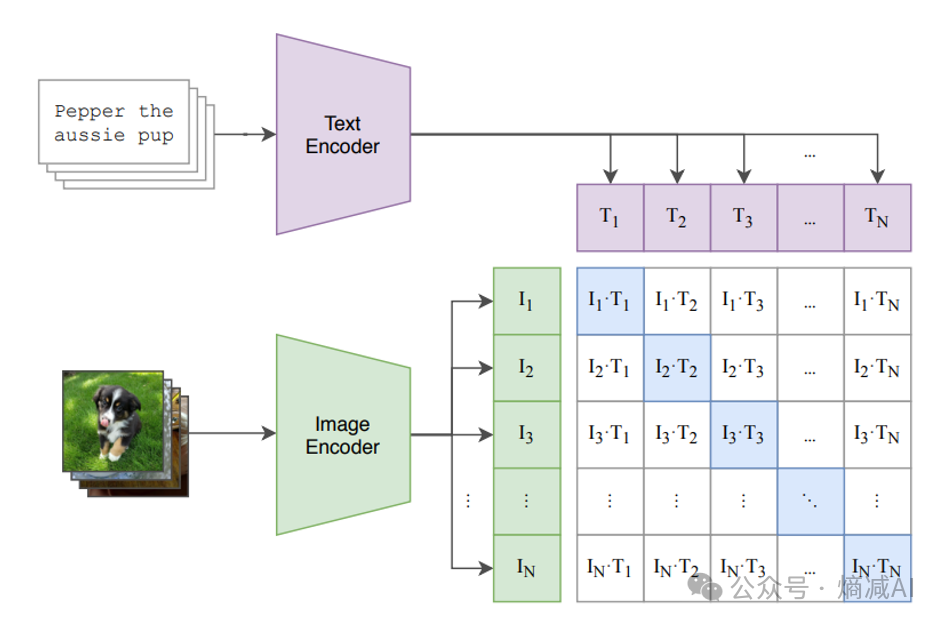
图5-1 CLIP的概念
CLIP的训练方式也可以被称为对比学习,首先设计一个矩阵,矩阵的行方向,是由一个Text-encoder来实现对于文本的embedding,它针对训练数据中的图片的描述给encoding成向量, Text-Encoder我们可以拿任何的Text-Transformer来实现。
相对应的,有一系列图片,这些图片和上面的图片描述是对应的,同时有一个image的的encoder,这个encoder也会把图片的高维数据,压缩成一个向量, Image-Encoder可以是ResNet,也可以是VGG, ViT都可以。
如图5-1所示,第一个文本T1和一堆图片I1到IN的向量做内积,最大的那个就是I1T1,第二个也是如此,I2T2,一直到InTn,相乘的得到一个矩阵的对角线,这个对角线就是最大值的一个集合。
既然要训练,那目标函数F(I,T)是什么呢?很显然它的目标就是最大化正样本的相似度,其他的位置全是负样本,要让负样本最小化。
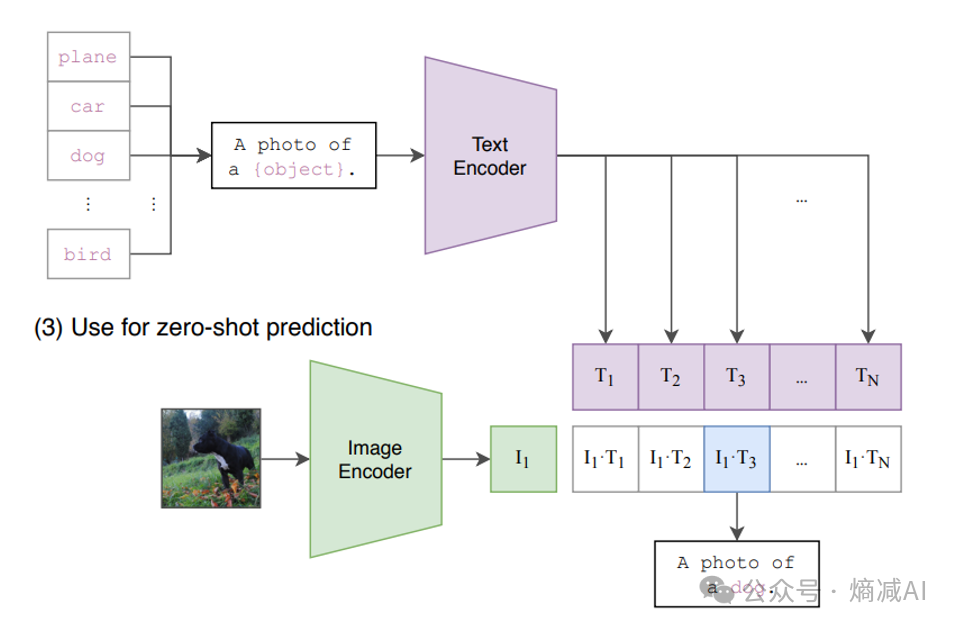
5-2 CLIP的推理
在推理的时候,如图5-2所示比如给一个zero-shot就给一只狗的图片,过了image encoder以后,和上面的text-encoder下来的那个向量做点积。然后直接取最大的那个,就能得到一句话"a photo of a dog", 就完成了一个简单的图片分类的任务。
CLIP和传统的什么resnet的训练方式不一样,不用定义正负样本,只需要标准文本图像对,正负样本是在batchsize里面随机得到的。
训CLIP的话,batchsize挺重要的:
第一:bacthsize不能太小,因为没有正负样本提前规划,所以如果训练太小的话,对角线跑不出来,比如给了文字,没给够足够的图片,文字知道和描述类似的东西是啥,但是不能理解不类似的东西是啥,那自然训练效果就不好,说白了就会变成隐式负样本的缺失。
第二:batchsize大,但是分类任务设置的太小,比如即使batchsize是100,但是分类任务就2个(猫,狗),有可能你这100个也捞不出来几个负样本,所以训练效果还是不好。
CLIP比传统的分类方式好处在哪呢?

图 5-3 CLIP和ResNet101对比
如图5-3所示,比如拿真实的水果图片去做训练,然后拿Resnet和CLIP来PK,同样的都是真实水果图片的场景来推理,它俩其实差不多,CLIP也没看出来好。但是,随着图片越来越抽象,ResNet的准确率下滑的就不是简单的线性了,甚至指数的下跌,这就是训练方式不同导致的CLIP显示出来的优势,从另外的角度解读就是,它的泛化能力特别强,支持新类别的拓展。
支持新类别的拓展是什么意思呢?因为它对图片来讲是点积得到的吗,我举个例子,你说 “A women walks on a street ”和 “A girl walks on a street”, 这两句话虽然不一样,但是women和girl的余弦距离本来就没那么大,所以你拿一个girl的图片来让只见过"women"的CLIP分类器来分类,一样能给比较好的完成下游任务。
还一个值得说的就是工程化的能力
如图5-3 红框的这两个部分和对角线矩阵是松耦合的,所以意味着完全可以独立离线计算,可以不一起占用算力,在上线的时候两个encoder各自训练好,再开始算对角线就可以了,也能实现算力版的"分时复用"
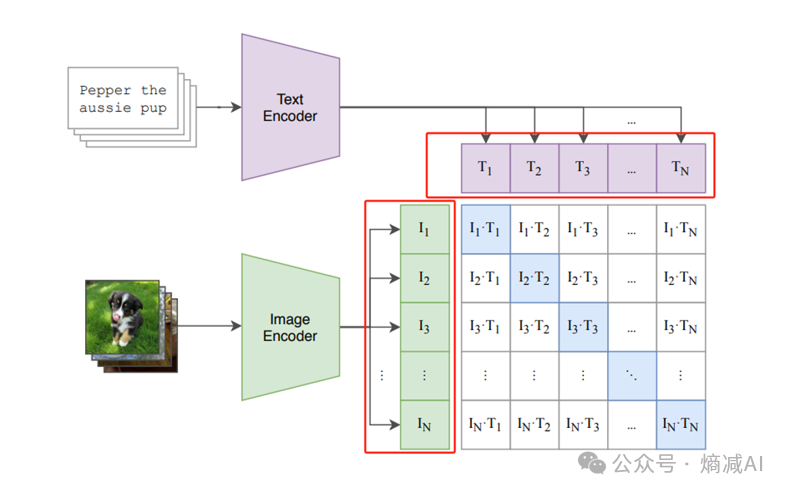
图5-3 算力分时复用
5.2 VIT
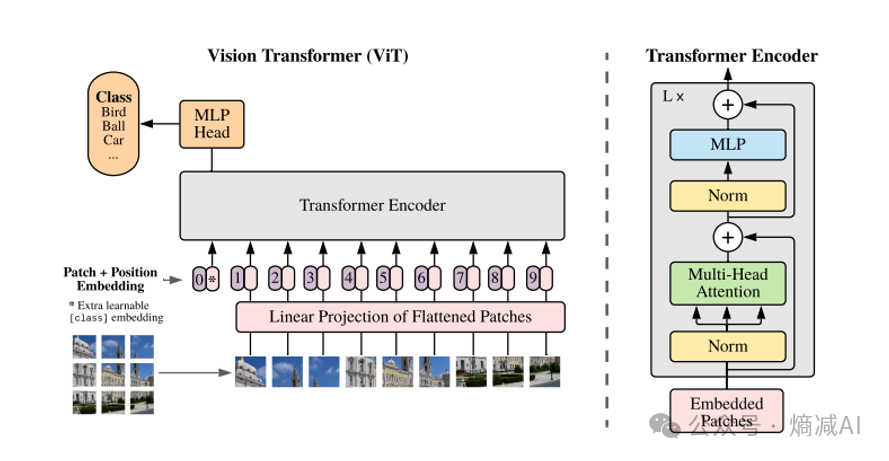
图5-4 VIT
我们来看看一下Vit的思路如图5-4,整个网络就是一个普通的Transformer网络,包含了正常的attention层,MLP层,Norm,和LN啥的也都有。
主要区别其实是在Transformer的Encoder前面整了一个线性层,这个线性层是整个网络的核心。
线性层主要作用就是mapping,何为mapping,就是把图片这种和文字不相干的元素也能被处理NLP的网络来进行处理,这就是mapping的含义。
那它具体是怎么做到的?
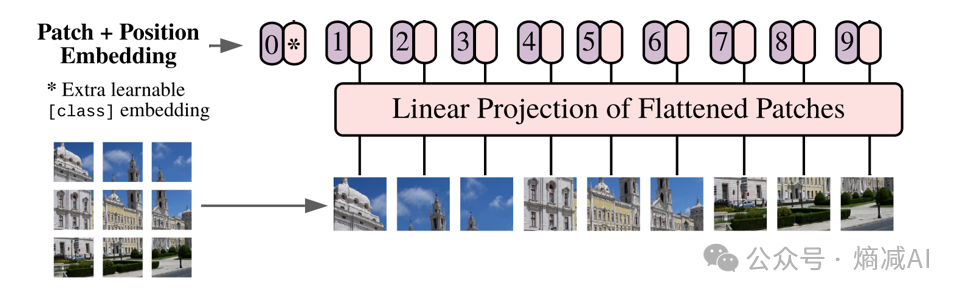
图5-5 Patch+Position Embedding
首先它把一幅图比如224*224*3的给切分了,比如切成一堆每块16*16*3的Tensor,(乘3就是RGB通道,这里当彩图处理的),这个Tensor被命名了一个名字叫Patch。 切完了以后,每个patch不是16*16吗,但是原图是224*224的,除以16*16就得到了196的patches,所以输入到encoder的seq_number就应该是224*224/16*16=196,如果是彩图,加上RGB,每个patch的tensor形状就是16*16*3=768。
然后这个tensor要做一个shape变成768,这样输入的训练数据就是[batch_size,196*768]这样的一个tensor,这里需要注意的原来这模型刚出来,实际上是个分类任务,所以又加了一个cls的分类字段。也就是197维的seq_number了,真实的输入训练数据是[batch_size,197,768]。
还有一种是不加cls位,然后token算加权,最后让一个MLP去做分类,我们就不介绍了,意思也差不多。
这个Tensor要被送入到线性层,线性层其实就是个编码层。
Tensor进来以后和Transformer一样要加进去位置编码,比如图里画的0-9,原论文是用和GPT一样的绝对编码来做的,通过正弦余弦来表示。编码完还是一样[batch_size,197,768]。
进了Transformer以后过多头self-attention再过 MLP,最后唯一区别输出是一个图的分类,不是关于字典的logit。
5.3 VAE
VAE的上
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 7144
7144











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









