






上回的地址:强化学习入门到不想放弃-3 (qq.com)
上上回地址:强化学习入门到不想放弃-2 (qq.com)
上上上回地址:强化学习入门到不想放弃-1 (qq.com)
好久没更新了,也是不知道写啥啊,(有些文章刚写了就被有些企业给告了,然后就被删了,我也不知道我啥不该些的了

)正好O1比较火,我就想起来我之前写的RL强化学习这块,之前是真的没人看啊,RL现在因为O1就特别的火了,所以我再尝试一下写写,看看有人看没。
可能也是我写的太散了,太书本话了,那今天先从广义上大家想了解的PPO吧,后面会写DPO, Q-learning, DQN
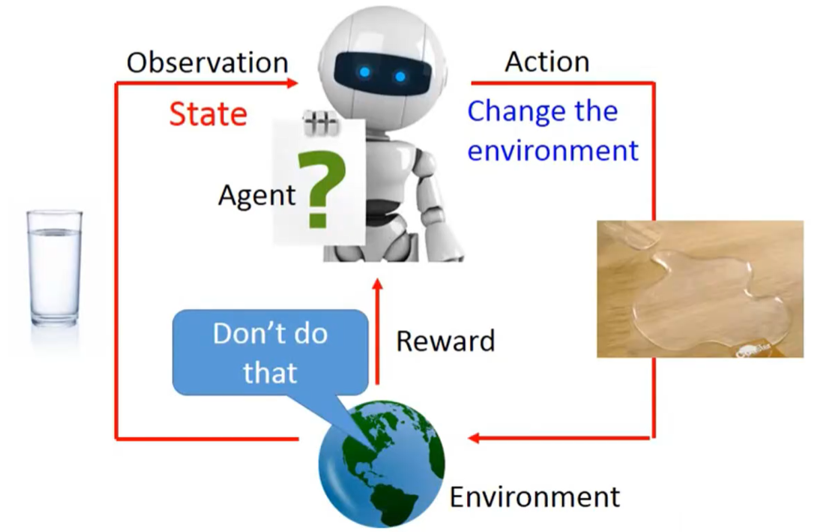
强化学习的一些基本概念,上面的机器人叫Agent,下面的地球叫environment。
Agent:与环境交互的进程(也可以是网络)
Environment:即环境,说白了就是一些规则的集合(已知的/未知的)
Agent和Environment有三种交互方式
1- Obseveration: 就是观察环境,观察什么呢?就是观察环境的状态,也就是state,那什么是state呢?比如说AlpacaGo可以观察围棋的棋盘上面的落子,或者图里的看到一杯水。
2- Action:就是对环境执行的动作,Action对环境执行了动作以后,环境就改了,比如把水给洒桌子上了,那state 也就是环境的状态,也就变了
3- Reward:Agent默认如果对环境的规则没有任何概念的话,它是不知道如何做的,但是比如弄洒了水咋桌子以上,这种的行为,其实就是一个减分项,如果我们认为洒水要-100分,而把水擦干会得200分,那在之后Agent于环境的操作就不会洒水了,而发现别的水洒了,它会擦干,其实就有点像小孩对这个世界刚开始的认识差不多,是靠一些奖惩机制来了解世界的。
从一个抽象的理解,其实强化学习就是这么定义的。

我们拿Super Mario Bro来套用刚才的概念
1- Action Space:就是你能做哪些操作,比如这里我就给一个向量
{left,right,A, B} (任天堂的操作),这是指这个游戏里你可以操作Mario执行任何的操作
2- Policy:Policy就是Agent Oberserve了Environment以后,比如它可以读取棋盘的对弈态势,或者它能通过几个连续帧来了解你的Mario处于的危险之中,以后输出Action的概率分布,一般用π来表示。
比如:{left:0.2,right0.2,A:0.2, B:0.4} (跳的操作)
3- Trajectiory:也就是轨迹,什么是轨迹呢,因为对于一局国际象棋,一局Super Mario,虽然某些动作能决定你的生死,比如一记妙手,比如前方有个乌龟正挡在Mario前进的道路上。
![]()
但是,大部分的情况下,一个action,决定不了你的输赢,你的胜利正常情况下是建立在一系列的动作操作基础上的,说白了是一个序列,我们一般叫它Episode, 由若干个state和action组成,这里用s和a来简写
比如{S0,a0,S1,a1,s2,a2.....St,at,St+1,at+1}
st+1一般是由st,at来决定的
st+1分为,确定的,和不确定的,比如 围棋的落子就是确定的,比如马里奥顶带有?的格子拿宝物,就是不确定的。
而a其实也分为两种,第一种是离散的,比如Mario的操作,上下左右,BA啥的,这样好弄,但是第二种连续的,就比较麻烦,比如求一个温度,求一个力量的牛顿数,这种就很难采样,这些以后讲怎么处理。
4- 最后一个就是 Return或者交Total reward,就是你执行的所有action统一获得的奖励的和。
先写到这,下节应该写马尔科夫和贝尔曼方程,不过也可能想到啥写啥,毕竟我没有提纲
















 738
738

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









