







| 论文名称 | 发表时间 | 发表期刊 | 期刊等级 | 研究单位 |
| When Malware is Packin' Heat; Limits of Machine Learning Classifiers Based on Static Analysis Features | 2020年 | NDSS | 顶会 | 加州大学 |
1. 引言
研究背景:传统反恶意软件技术包括基于签名的检测与基于启发式的检测。恶意软件的泛滥催生了具有泛化能力反恶意软件技术的需求,专家学者开始利用静态分析、动态分析、机器学习等技术进行恶意软件检测。
现存问题:基于机器学习的恶意软件检测可分为,基于动态分析的恶意软件检测与基于静态分析的恶意软件检测。其中,动态分析虽然能够更全面的获取可执行文件的行为特征,但在实践中存在诸多问题(内核权限导致的攻击面扩大,虚拟机导致的计算资源爆炸等)。静态分析相较于动态分析具有更广阔的使用场景和更低的分析成本,但同时受到代码混淆和软件加壳的影响。
一些恶意软件研究人员认为加壳会阻止机器学习技术构建有效的分类器,另一些恶意软件研究人员认为机器学习模型可以实现加壳恶意软件的有效检测。一些研究人员怀疑出现这种情况的原因是,某些数据集中存在恶意软件即是加壳软件(良性软件即是非加壳软件)的情况。为了回答上述问题,论文引出以下研究问题:加壳二进制文件的静态分析是否能获得足够丰富的特征,以实现机器学习模型的有效构建?
主要工作:研究者构建了一个真实的数据集,该数据集可以同时确定每个样本是否加壳与是否为恶意软件。具体来说,研究者首先对商业反恶意软件供应商提供的可执行文件进行两步过滤(加壳可执行文件过滤,标签不一致可执行文件过滤),之后通过多款商业和免费加壳器对过滤后可执行文件进行加壳,最终实现实验数据集的构建。除此之外,论文从数据集中提取了 9 类可执行文件静态特征,并设计一系列实验以评估加壳样本对基于静态分析的恶意软件检测模型的影响与各类静态特征中”有效“信息的丰富程度。
2. 研究动机
长期以来,软件加壳一直是恶意软件坐着逃避基于签名反恶意软件引擎检测的有效方法,但加壳器在良性软件上的合法使用却很少能得到研究人员的重视。2013 年,研究人员使用 4 种不同的加壳器对 16663 个良性软件进行加壳操作,并通过 VirusTotal 进行检测。在实验种,96.7% 的良性软件被至少 10 个恶意软件引擎判定为恶意软件。2017年,研究人员基于上述发现构造对抗性样本,强制反恶意软件引擎将良性软件判定为恶意软件。论文作者猜测发生这种情况是因为:在之前的很长一段时间内,软件加壳是恶意软件的专属行为,基于静态特征的恶意软件检测模型很容易将加壳行为与恶意行为关联起来。让良性软件执行加壳操作后,恶意软件检测模型很容易将良性软件判定为恶意软件。

为了验证上述猜想,论文对收集到的可执行文件样本进行分析。发现加壳不仅在恶意软件样本中广泛存在(75%),而且在良性软件样本中也十分常见(最多达到 50%),如上图所示。除此之外,论文还使用 Themida 对 Windows 10 上的 613个良性可执行文件进行加壳,其中 564 个良性可执行文件被至少 10 个反恶意软件引擎判定为恶意软件,如上图所示。通过实验结果可知,任何在设计和评估恶意软件检测方法时未考虑加壳良性样本的方法最终都会导致在实际使用过程中出现大量误报。
3. 研究背景
加壳器介绍:加壳器是一种用于保护软件代码免受反编译的工具。通常包括代码加密、混淆、压缩以及虚拟化等功,可以有效增强软件的安全性。加壳器可以分为 6 类如下所示:
- 类型 1:执行单个解包例程以将控制权转移到原始程序。
- 类型 2:采用一系列按顺序执行的解包历程,并在连的末尾重新组合原始代码。
- 类型 3:解包例程包括循环和后沿。 尽管不一定在最后一层重构原始代码,但仍然存在尾部过渡来分隔加壳器和应用程序代码。
- 类型 4:在每一层打包中,解包例程的相应部分与原始代码的相应部分交织在一起。 然而,在执行过程中的某个时刻,整个原始代码将在内存中完全解压。
- 类型 5:加壳器由不同的层组成,其中解包代码与原始代码混合在一起。 有多个尾部跳转,一次仅显示原始代码的一帧。
- 类型 6:加壳器在任何给定时间仅显示(解包)原始代码的单个片段(小至单个指令)。
文件加壳检测的局限性:基于签名的加壳检测方法具有很高的误报率,因为它们需要先验了解每个加壳器生成的加壳可执行文件(PEiD 的漏报率约为 30%)。基于启发式的加壳检测方法具有较强的检测能力,但也会受到对手的攻击(通过将可执行文件插入文件,逃避基于熵的启发式检测方法)。基于动态分析的加壳检测方法检测能力最强,但仍需要面对引言部分提到的问题。
通用解包器的局限性:加壳器通常采用不同的技术来逃避通用解壳器使用的分析方法,例如 tELock 和 Armadillo 引入了多个反调试例程来终止调试的执行,Themida 将虚拟化混淆应用于其解包例程。一般来说,通用解包器依赖于许多在实践中不一定成立的假设:
- 假设 1:整个原始代码在某个时刻都在内存中。
- 假设 2:原始代码在最后一层解包。
- 假设 3:解包例程和原始代码的执行完全分离。
- 假设 4:解包代码和原始代码在同一进程中运行,没有任何进程间通信
这些假设使得解壳器在对现实世界加壳文件进行解包的过程中面临重重挑战。此外,通用解壳器通常依赖于为特定加壳器设计的启发式方法。
基于静态分析的加壳恶意软件检测:论文回顾了基于机器学习的各种静态恶意软件分析方法,尽管静态恶意软件检测器已被证明偏向于检测加壳,但许多论文仍在加壳软件检测方面缺少相关分析。具体来说,(1)其中 10 篇论文完全没有提及加壳和混淆技术;(2)其中 10 篇论文仅针对未加壳软件的分析;(3)其中 7 篇论文声称可执行文件的加壳不会影响模型性能,但并没有对软件加壳操作的影响进行分析;(4)其中 3 篇论文对加壳可执行文件进行了分析,但仍存在对应的局限性(加壳文件检测准确性存疑,数据增强方式有效性存疑)。
4. 数据集构建
原始数据集:论文从商业反恶意软件供应商处获得 29573 个可执行文件,从 EMBER 数据集中获得 56411 个可执行文件。为了确定可执行文件是否为恶意软件,论文使用三种不同的方式对可执行文件进行检测:
- 检测方式 1:通过查询 VirusTotal 获得整个数据集的报告,并选取 7 个检测能力最强的反恶意软件引擎对可执行文件进行标记。
- 检测方式 2:将 EMBER 数据集中的可执行文件交给反恶意软件供应商,并通过他们的沙箱对可执行文件进行标记。
- 检测方式 3:利用 EMBER 数据集自带的可执行文件标记。
根据检测结果,丢弃 4113 个在标签上存在冲突的可执行文件样本。最终获得 37269 个良性样本和 44602 个恶意样本。为了确定可执行文件是否加壳,论文使用三种方式对可执行文件进行检测:
- 检测方式 1:通过反恶意软件供应商的沙箱对可执行文件进行动态分析。
- 检测方式 2:使用 Deep Packer Inspector 工具对可执行文件进行动态分析。
- 检测方式 3:使用 Manalyze、ExeinfoPE 以及 PEiD 识别简单的加壳行为。
如果上述三种检测方式中的一种检测出可执行文件存在加壳行为,则将可执行文件标记为加壳。
实验数据集:论文使用 9 个商用或免费加壳器对原始数据集中的样本进行加壳,实现实验数据集的构建。除此之外,作者还开发了一个名为 AES-Encrypter 的加壳器,并通过该加壳器对原始数据集中样本进行加壳。
静态特征提取:论文选择了 9 类比较常用的静态特征,并从实验数据集中提取相应的静态特征。具体来说,这些静态特征包括 PE Header、PE Section、DLL import、API import、Rich Header、Byte n-grams、Opcode n-grams、Strings 以及 File generic。
- PE Header:从 PE Header 中的 File Header 和 Optional Header 中提取 13 个整数特征和 16 个二进制特征。
- PE Section:由于可执行文件 PE Section 的数量不固定,论文从可执行文件前 20 个 Section 中提取 PE Section 特征。对于每个 Section ,提取 7 个数值特征和 32 个二进制特征,一共提取 780 个特征。
- PE DLL:将可执行文件对应的 DLL 转换为二进制特征,获得 4305 个二进制特征。
- PE API:将可执行文件对应的 API 转换为二进制特征,获得 19168 个二进制特征。
- Rich Header:PE 文件(Portable Executable)的 Rich Header 是一段位于文件头部的加密数据,用于存储有关在生成该文件时所使用的编译器和链接器的信息。通过对Rich Header 进行解密,可以从中提取出 66 个整数特征。
- Byte n-grams:将可执行文件视为字节序列,提取可执行文件对应的 n-gram 特征,获得 13000 个 n-gram 特征。
- Opcode n-grams:对可执行文件进行反汇编,将可执行文件视为操作码序列。提取可执行文件操作码对应的 n-gram 特征,获得 2500 个 n-gram 特征。
- Strings:提取可执行文件中的字符串特征,获得 16900 个二进制特征。
- File Generic:计算每个样本的大小(以字节为单位)以及整个文件的熵,将这些特征作为通用特征。
5. 实验与结果
论文讨论的核心问题是:加壳二进制文件的静态分析是否为恶意软件分类器提供足够丰富的特征?为了回答这个问题,论文设计了下面的一系列实验。
5.1 加壳属性的分布对模型训练的影响
研究问题:当良性和恶意样本中加壳属性存在分布偏差时,分类器是否会将特定的加壳操作作为可执行文件是否为恶意的评判标准?
验证实验:论文使用 3956 个未加壳的良性可执行文件和 3956 个加壳的恶意可执行文件训练分类器,分类器的漏报率和误报率分别为 3.82% 和 2.64%。通过训练好的分类器对 12647 个加壳的良性样本进行检测,误报率由 2.64% 增加到 23.40%。
论文将加壳器分为两类(简称 A 类,B 类),通过 A类加壳器加壳的良性样本和 B 类加壳器加壳的恶意软件样本训练分类器。通过训练好的分类器对 B类加壳器加壳的良性样本和 A 类加壳器加壳的恶意软件样本进行检测,分类器的精度从 0.01% 到 12.57% 不等。
实验结论:上述实验研究了两种不同加壳分布(是否加壳的影响,不同类加壳的影响)数据集对训练分类器造成的影响,实验表明如果良性样本和恶意样本的加壳属性存在分布偏差,则分类器会偏向于将加壳特征作为可执行文件是否未恶意的评判标准。
5.2 加壳操作对基于静态分析的分类器的影响
研究问题:对可执行文件进行加壳对基于静态分析分类器有哪些影响?
验证实验:论文以完全随机的方式对数据集中的良性样本和恶意样本进行加壳,并通过逐渐增加加壳良性软件比例的方式构建一系列子数据集,最终通过这些子数据集训练分类器,如下图所示。在所有样本均加壳的情况下,分类器的误报率和漏报率仍能保持在较低的水平(分别为 12.24% 与 11.16%)。
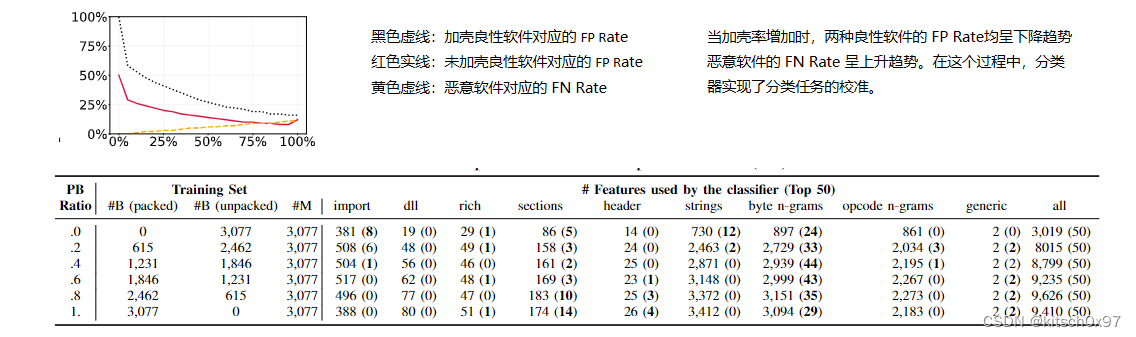
论文通过 9 种不同的加壳器对良性可执行文件和恶意可执行文件进行加壳,构建了 9 个不同的子数据集,并通过这些数据集训练分类器,实验结果如下图所示。实验表明,各实验的 FPR 与 FNR 均保持在在较低的水平(10% 以下),且不同实验的 FPR 与 FNR 相差较大(增加两倍)。

实验结论:加壳器在对可执行文件执行加壳操作时,会保留一些可能对恶意软件分类“有用”的信息,但这些信息并不一定代表样本的真实性质。
5.3 真实世界中的恶意软件分类
研究问题:经过精心训练且不偏向特定加壳操作的分类器能否在现实场景中表现良好?
验证实验:论文通过原始数据集和实验数据集分别训练原始分类器和实验分类器,并分别通过原始分类器和实验分类器检测实验数据集和原始数据集,实验结果表明两类模型的泛化能力都比较弱。除此之外,论文还通过特定加壳数据集训练出的特定加壳分类器检测其他加壳数据集,实验结果表明特定加壳分类器无法有效检测其他加壳数据集中的恶意软件。
论文作者开发了可以实现可执行文件原始二进制信息完全隐藏的加壳器 AES-Encrypter,通过该加壳器生成对应的数据集,并进行恶意软件检测实验。实验表明,分类器仅能通过文件大小和文件熵对恶意软件进行判断。如果去除这两个特征(攻击者可以改变文件大小和文件熵),分类器将完全无法分辨良性软件与恶意软件。
论文作者在恶意软件的基础上构建对抗性样本,并通过训练好的分类器检测对抗性样本,实验表明分类器无法有效检测出这些构造的对抗性样本。
实验结果:尽管静态分析特征与机器学习相结合可以一定程度上区分加壳的良性软件和恶意软件,但这样的分类器在现实环境中往往是无效的。
5.4 反恶意软件行业与加壳恶意软件
研究问题:利用机器学习与静态分析功能相结合的现实世界反恶意软件引擎的准确度如何受加壳的影响?
验证实验:论文作者在 VirusTotal 中选取了 6 种完全基于静态分析特征的基于机器学习的恶意软件检测器,将实验数据集中的 6000 个加壳良性软件和 6000 个加壳恶意软件提交给 VirusTotal,实验结果如下表所示。实验结果表明,所有 6 个恶意软件检测器在所提交的数据上都存在很高的误报率。 除此之外,VirusTotal 上的其他引擎也产生了与这 6 个引擎类似的高误报率。
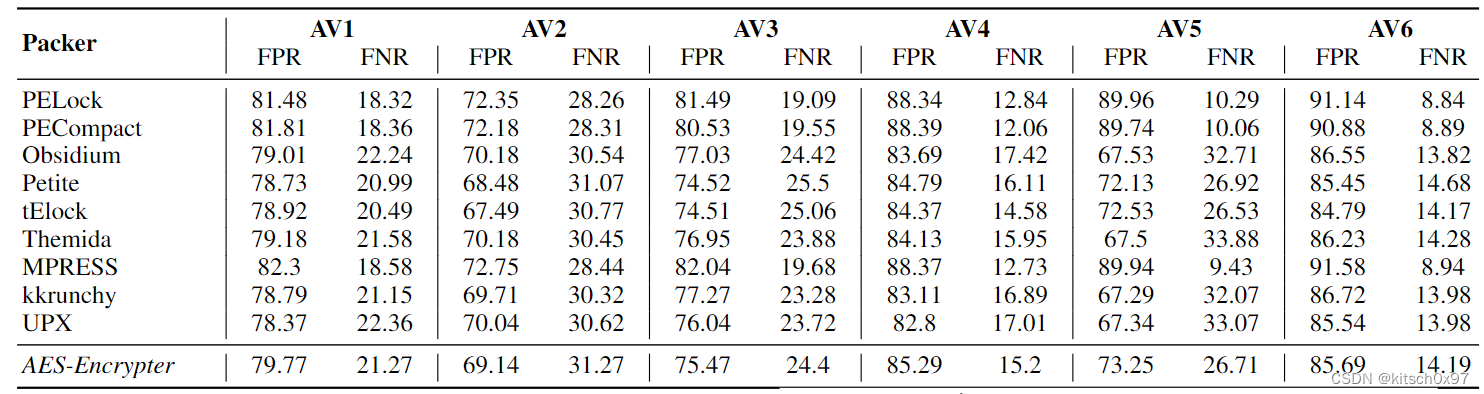
实验结论:VirusTotal 上基于机器学习的反恶意软件引擎实际上是对所提交软件是否加壳进行检测,而不是对软件本身是否存在恶意行为进行检测。
6. 讨论
实验表明,VirusTotal 上基于机器学习的反恶意软件引擎会对加壳的二进制文件产生大量误报。对于基于机器学习的方法来说,这尤其是一个严重的问题。因为这些方法经常依赖于VirusTotal 中的标签,导致新方法依赖于被污染的数据集,进而生成被污染的无限循环。
有人可能会说,可以通过代码签名证书将良性样本列入白名单来避免加壳良性软件误报率高的问题。然而,这种代码签名证书的引入很可能被恶意软件利用,以实现其对反恶意软件引擎的绕过。应该指出的是,针对已知加壳器的分类任务是一项相对简单的任务,但现实世界中攻击者往往会使用定制加壳器,因此在实现加壳器检测的基础上进行恶意代码检测仍然困难重重。虽然使用动态分析特征可以很大程度上解决静态特征存在的问题,但恶意软件仍然可以通过沙箱规避迫使恶意软件检测器依赖静态特征。所有这些问题表明,恶意软件检测应使用动静结合的混合方法。
















 520
520

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









