







0. 摘要
研究背景:二进制代码分类与相似性检测是恶意代码家族分析、软件代码溯源的基础,对保障网络空间安全具有重要作用。
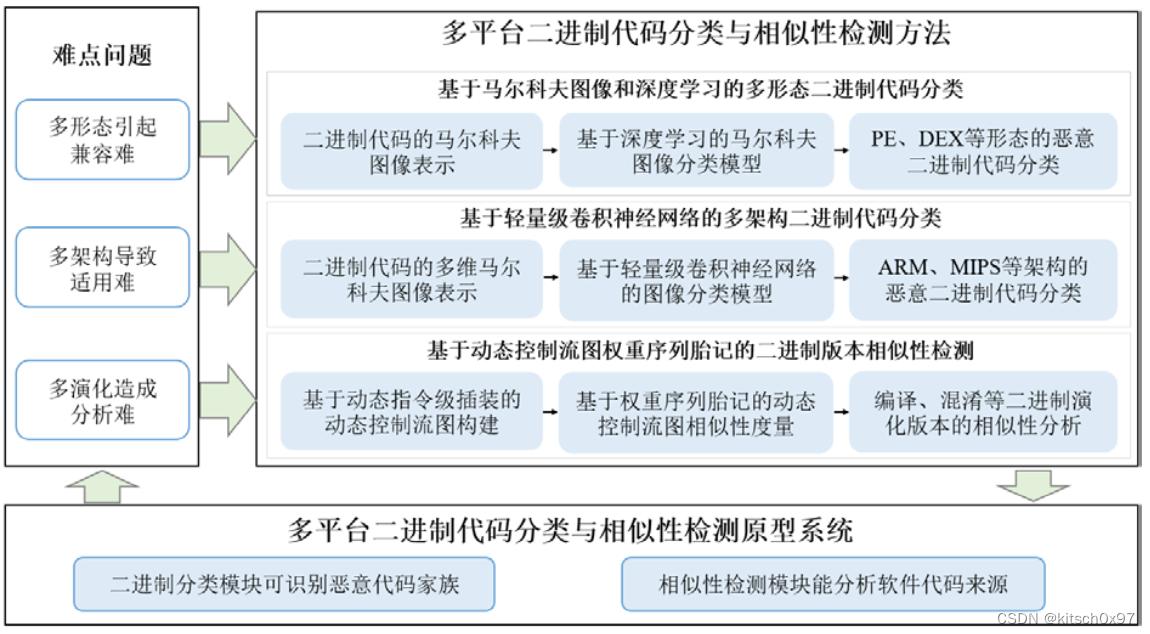
现存问题:在多种平台下,二进制代码包括 PE、ELF、DEX 等形态的文件格式,并设计 X86、ARM、MIPS、PPC 等指令架构。而在同一平台下,同一份软件代码也可经过混淆、加壳等烟花方式生成多种二进制版本。这种“多形态”、“多架构”、“多演化”的特征,导致二进制代码的分类与相似性检测面临着兼容难、适用难、分析难的问题。因此,如何对多平台二进制代码进行特征表示、分类以及相似性检测,成为亟待解决的技术难题。
研究内容:针对以上难点问题,论文首先提出了基于二进制字节码的马尔可夫图像表示,该方法无需逆向分析和动态分析过程,多平台兼容性强;其次,未适用于多种指令架构,论文提出了基于轻量级卷积神经网络的二进制代码分类方法,器分类模型的大小仅 1MB;然后,为分析二进制不同演化版本的相似性,论文结合动态指令级插桩,提出基于动态控制流图权重序列胎记的二进制代码相似性检测方法;最后,论文基于上述研究内容,构建多平台二进制代码分类和相似性检测原型系统。
1. 绪论
相关技术研究现状:二进制代码分类是指将具有相同或相似特征的二进制归为一类。二进制代码相似性检测直接比较两个软件代码的特征,判断二者是否相似。从技术层面来看,代码分类和代码相似性检测均已特征分析为前提,并综合利用了传统机器学习、深度学习等数据挖掘技术。
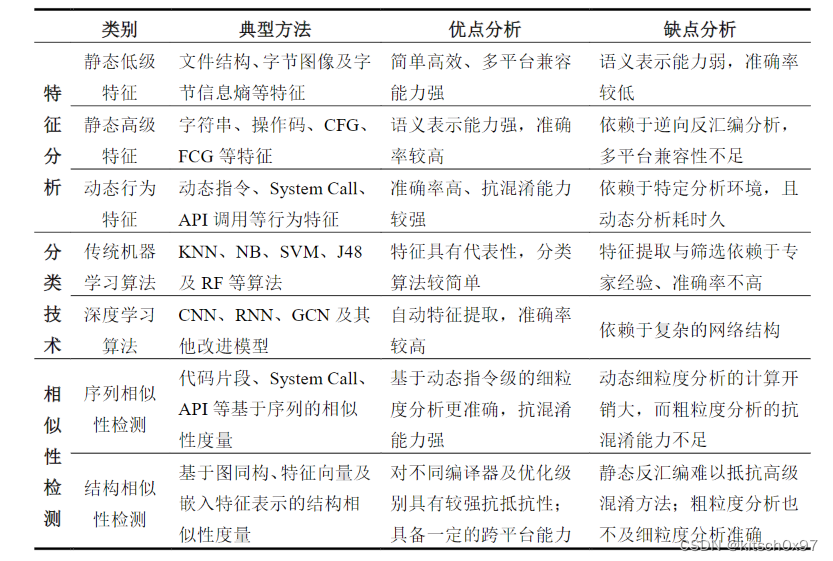
- 二进制代码特征分析:二进制代码特征包括静态低级特征、静态高级特征和动态行为特征。其中,静态低级特征直接从原始二进制文件中提取,而静态高级特征分析以逆向分析为基础,从二进制反汇编文件中提取。二者均属于静态分析,不需要二进制带啊吗实际运行起来,具有速度快、效率高的优点。而动态行为属于一种更高级的特征分析方法,需要在虚拟沙箱或受控环境中运行二进制代码,以观察其执行情况,具有更好的抗混淆能力。
- 二进制代码分类:在特征分析的基础上,早期的二进制代码分类方法一般采用 K 近邻(K-Nearest Neighbor, KNN)、朴素贝叶斯(Naive Bayes, NB)、决策树(Decision Tree, DT),随机森林(Random Forest, RF)、支持向量机(Support Vector Machine, SVM)等传统的机器学习算法。近年来,随着人工神经网络在计算机视觉、自然语言处理等相关领域体现出显著优势,深度学习算法也可用于二进制代码分类。
- 二进制代码相似性检测:相似性检测是对两个二进制代码的特征进行比较,可判断基本块、函数或整个程序是否相似。根据特征提取和表示方法的不同,二进制代码相似性检测方法包括序列相似性检测和结构相似性检测。与分裂方法相比,相似性检测不需要大量标记样本作为训练集,但是对特征提取和表示方法却有更高要求。
面临的问题和技术挑战:在特征分析方面,静态低级特征具有简单、高效和多平台兼容的优势,但分类准确率不高。在分类算法方面,基于深度学习的方法能够自动提取特征,且具有准确率较高的优势,但分类模型通过较复杂。在相似性检测方面,基于动态指令级的细粒度分析具备强大的抗混淆能力,但计算开销较大。
由于国内外研究在二进制代码特征分析、分类算法及相似性检测方法等方面存在着一定的不足,本文结合多平台二进制代码分类与相似性检测对兼容性、适用性及抗混淆能力的实际需求,提出 3 个需要解决的科学问题,(1)二进制代码缺乏简单高效的特征表示,高级特征分析方法难以兼容不同操作系统平台(针对静态特征的高效特征表示);(2)以 IoT 为代码的设备设计指令架构多、计算能力弱,导致复杂分类算法难以适用于多种指令架构(针对静态特征的轻量级模型);(3)二进制代码演化方式多,混淆、加壳操作造成一般检测方法难以分析二进制不同版本的相似性(针对动态特征的相似性检测)。
研究内容:论文针对多平台二进制代码分类与相似性检测中存在的兼容难,适用难以及分析难的问题,从多平台二进制代码的特征表示、分类即相似性检测方法等方面展开研究,并构建了多平台二进制代码分类与相似性原型系统。
















 1172
1172

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









