







1. 概述
主要分两类:one-stage直接输出物体的类别概率和坐标,速度快,准确度较two-stage低。two-stage第一步是通过RPN(Region Proposal Network)等生成候选区域,第二步对每个候选区域进行分类和回归得到最终结果。
另外还有anchor-based和anchor-free差别。anchor是一些先验的检验框。
评价指标
AP:给定IoU阈值(从0.1到1),计算precision和recall,PR曲线下方面积为AP。
mAP:不同分类的AP取平均。
2. 两阶段模型
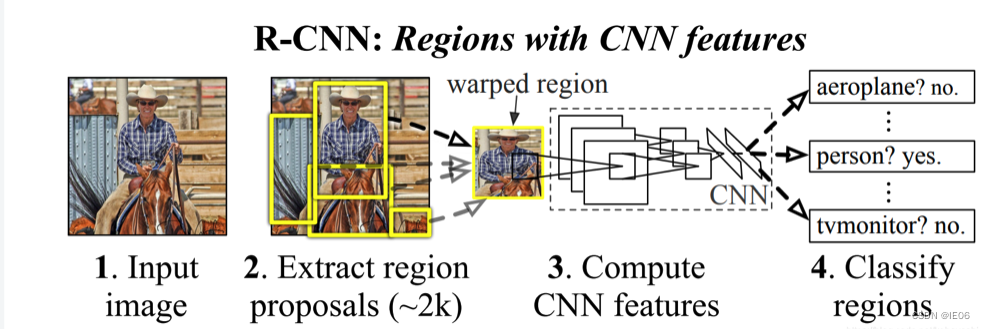
2.1 RCNN
step1:在输入图片上使用Selective Search产生大约2k个候选区域;
step2:将不同形状的候选区域统一变换到227*227尺寸,输入CNN(AlexNet)中提取特征;
step3:使用SVM进行分类
2.2 Fast R-CNN
改进:只做一次卷积
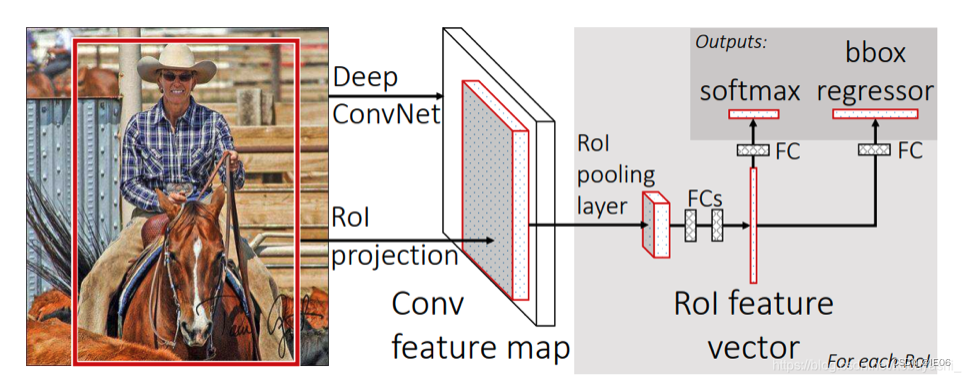
step1:输入是整张图片和候选区域(Selective Search得到)的集合,经过CNN(VGG16)后得到特征图;
step2:使用RoI pooling将特征图采样(RoI pooling layer+ FC)为一个定长的特征向量;
step3:对于每个RoI特征向量进行两个任务1)softmax输出类别;2)bbox回归
2.3 Faster R-CNN
改进:使用anchor,加入RPN网络,即候选框也通过特征图生成。
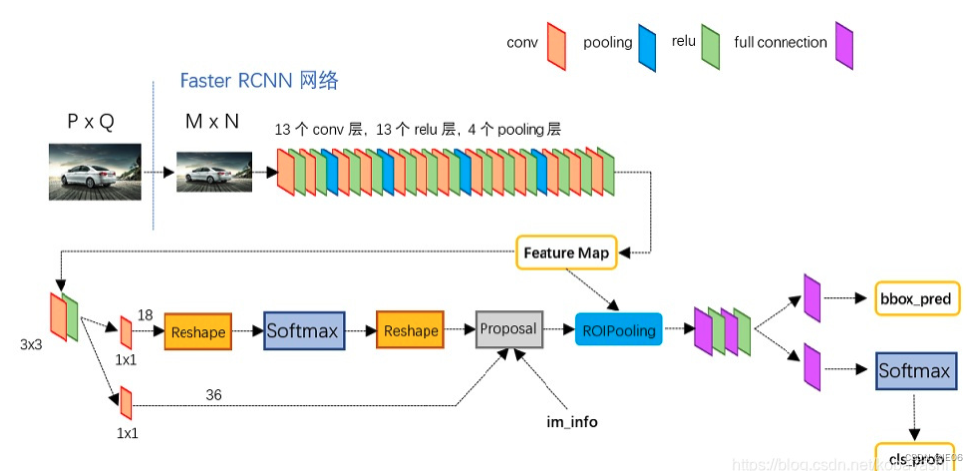
step1:卷积层对输入的图像进行特征提取得到特征图;
step2:RPN网络使用先验anchor输出带有objectness socre的矩形候选区域(通过先验anchor产生)集合;
2.4 Mask RCNN
用于实例分割。主要改进1)Faster R-CNN加了一个输出mask的分支;2)将RoI Pooling改为了RoI Align。
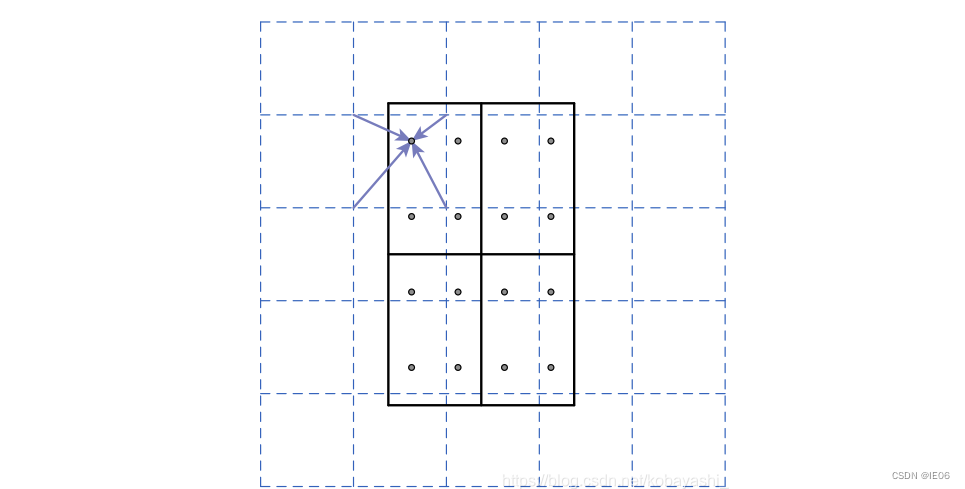
RoI Pooling将不同大小的特征子图采样成固定大小的 7 × 7,会丢失像素的位置信息,对语义分割有影响。
RoI Align将RoI的分为4个区域,每个区域设立4个采样点。RoI Align通过从特征图上附近的网格点进行双线性插值来计算每个采样点的值。对RoI、其bin或采样点所涉及的任何坐标不进行量化。
3. 单阶段模型
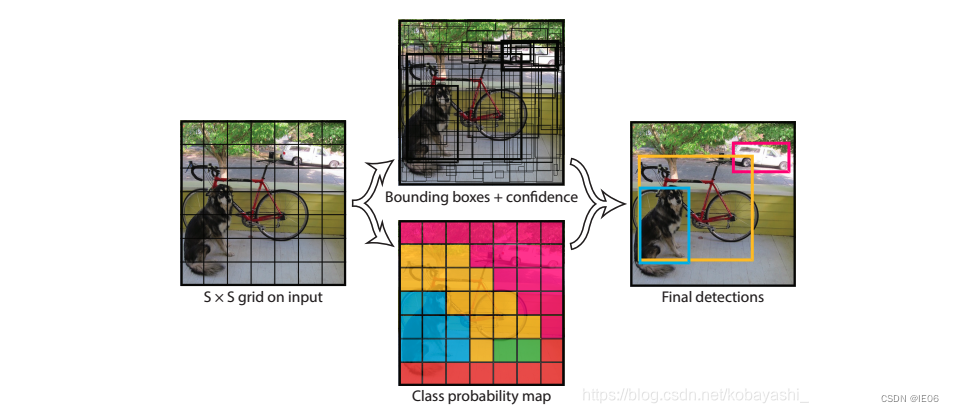
3.1 Yolo v1
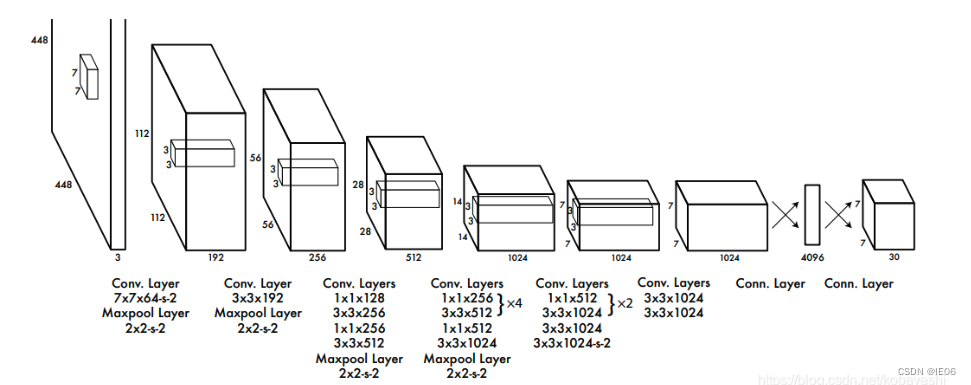
yolov1的模型如下,有24个卷积层和2个全连接层组成,输出形状为 7 × 7 × 30,30 = ( 4 + 1 ) × 2 + 20,4表示 ( w , h , x , y ),1表示置信度 c ,2表示预测两个矩形框;20代表预测20个类。
3.2 Yolo v2-v7
改进:1)分类使用树结构;2)使用FPN(Feature Pyramid Networks),即金字塔结构+RPN(Region Proposal Networks)
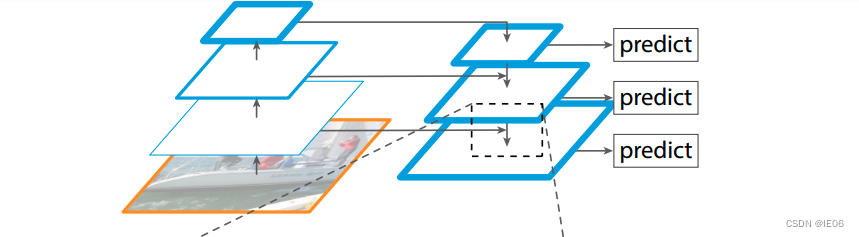
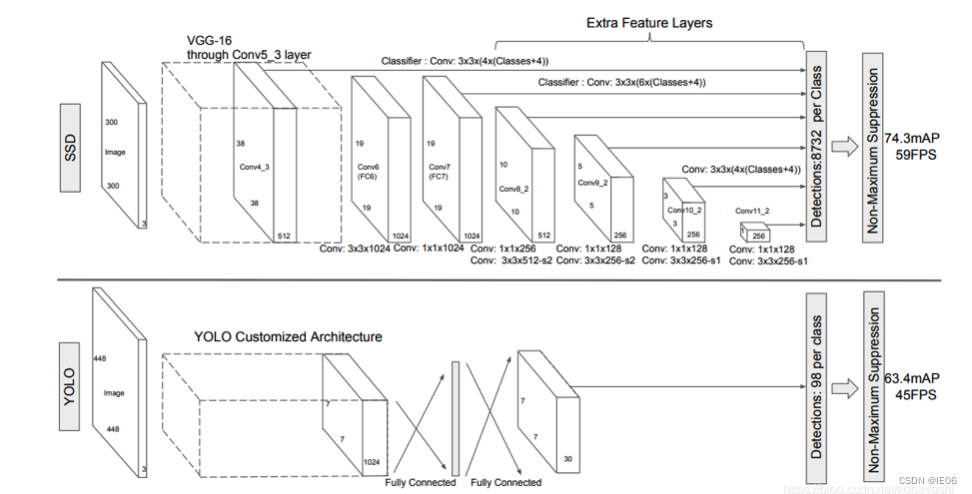
3.3 SSD
改进:使用了多尺度的特征图进行检测,对小目标的检测能力优于yolov1。
3.4 RetinaNet
改进:解决单阶段模型正负样本(前景和背景)不平衡的问题。
Focal Loss的是在cross entropy损失函数上改进的:
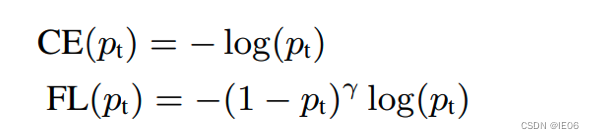
3.5 EfficientDet
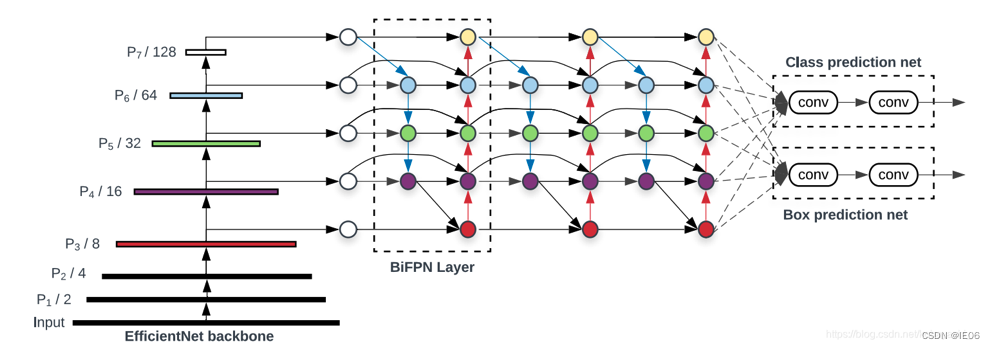
改进:1)使用EfficientNet作为backbone;2)提出了BiFPN结构。
BiFPN是双向,重复,残差结构的候选框生成网络,如下图,红色箭头是双向,黑色箭头的残差。
3.6 FCOS
改进:去除了anchor。
RCOS不是基于关键点检测,而是一种逐pixel的检测方法。通过对GT中心域所在cell进行类预测,并给出(l,r,t,b)四个偏移回归量,完成检测任务。
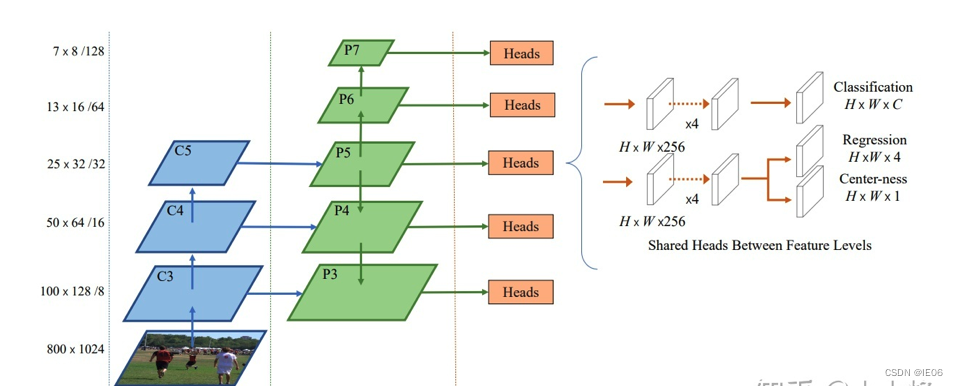
FCOS采用的网络架构和RetinaNet一样,都是采用FPN架构,如下图所示,每个特征图后是检测器,检测器包含3个分支:classification,regression和center-ness。
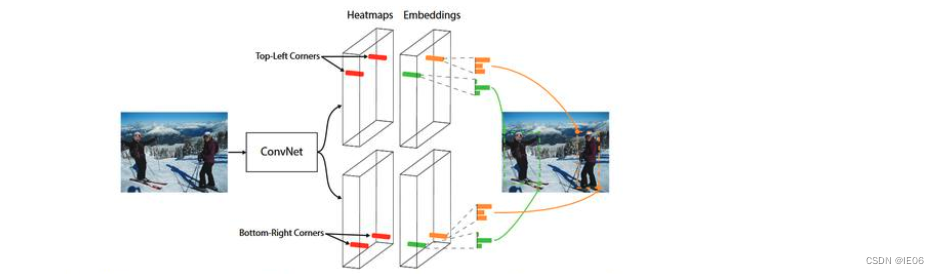
3.7 CornerNet
将对一个目标的检测看成一对关键点(左上和右下)的检测。
3.8 CenterNet
改进:将anchor+NMS改为heatmap+size(实际使用还有个offset),真正端到端。
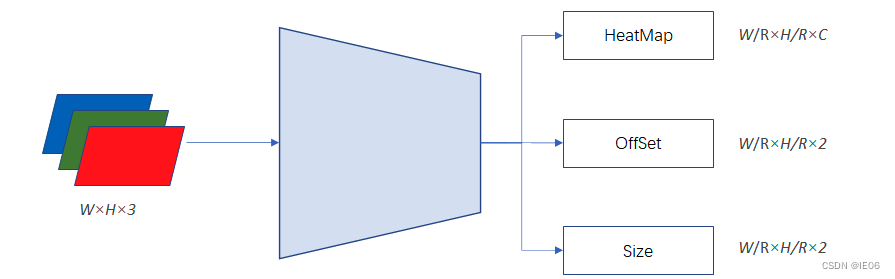
CornerNet对于小物体的错检率很高,达到了60.3。究其原因,就是因为CornerNet不能“窥探”bounding box内部的信息。因此,CenterNet用三个关键点进行bounding box的确定。

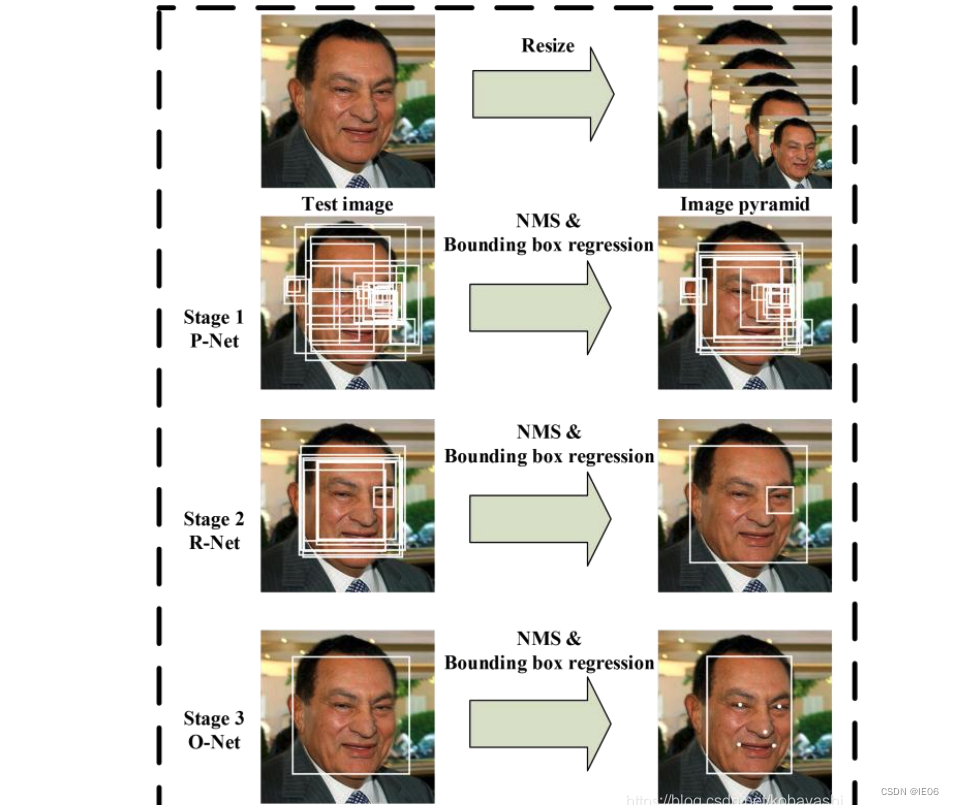
4. 级联模型
专用于人脸检测,由3个网络构成:1)P-Net:负责输出候选区域;2)R-Net:负责对候选区域进行进一步调整;3)O-Net:负责对R-Net调整之后的区域又进一步调整,然后输出。
当然也可以一直这么迭代下去。
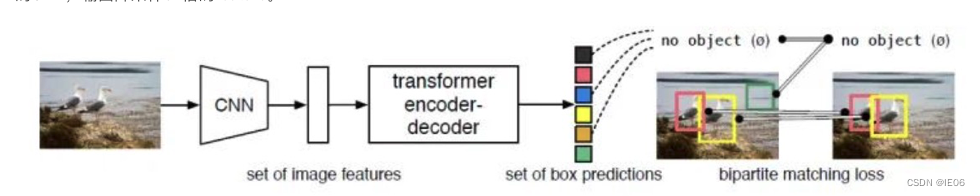
5. Transformer模型
5.1 DETR模型
使用CNN+位置编码进行encoding,然后通过transfomer+随机N个输入直接得到N个输出,每个输出包含位置/大小和分类结果














 1567
1567











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









